
DFS中的探索顺序对边缘分类有影响吗

我正在为学院实现DFS和边缘分类(基于本文提供的html" target="_blank">代码:https://courses.csail.mit.edu/6.006/fall11/rec/rec14.pdf)。
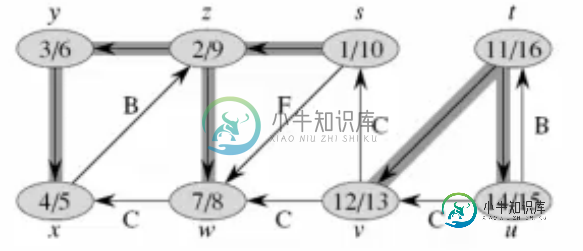
斜体字母只是顶点的名称,而顶点内部的数字分别是发现时间和完成时间。边缘分为后、前或交叉;其他都是树边。
正如您所看到的,该图是按照以下顺序访问的:首先是s,然后是它的邻居(在DFS之后);当没有更多可访问的邻居时,访问开始于t。
为了测试我们的算法,老师会提供一个文本文件,每个边都是一条线。当执行DFS时,我只是按照每个顶点在文件中的出现顺序;在本例中,首先是S,然后是V,而不是T。这又给出了不同的边分类:T到V被认为是交叉边,T到U被认为是背边,U到T被认为是树边。
这种行为正常吗?探索的顺序是否影响最终的边缘分类?如果是的话,我的分类和示例的分类是否正确?如果没有,有没有办法让我知道先探索哪个顶点?
共有1个答案

这种行为正常吗?探索的顺序是否影响最终的边缘分类?
当然可以。当存在任何反边或交叉边时(即当图不是树时),算法选择用于探索的边的顺序决定了边的分类
如果是的话,我的分类和示例的分类是否正确?
该问题可能指定了特定的探索顺序-例如,您的图片上的图形似乎是按照顶点命名的反字母顺序遍历的:Z在W之前从S开始,Y在W之前从Z开始,V在U之前从T开始。
-
使用递归的DFS将节点标记为未访问、已发现或已完成(或白、灰、黑),可以根据三类(后边缘、树/前边缘、交叉边缘)对边缘进行分类。 我们是否也可以使用算法的迭代版本(参照深度优先搜索)对边缘进行分类?
-
问题内容: 我在玩networkx(Python中的图形库),发现文档说PageRank算法在评分时考虑了边缘权重,但是我想知道更大的边缘权重是更好还是更低的权重呢? 问题答案: 不久,较大的权重对于传入的节点更好。 PageRank在有向加权图上工作。如果页面A具有到页面B的链接,则页面B的得分会上升,即页面B(节点)输入的次数越多,其得分就越高。 有关更多详细信息,请参见PageRank上的W
-
本文向大家介绍mysql索引对排序的影响实例分析,包括了mysql索引对排序的影响实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了mysql索引对排序的影响。分享给大家供大家参考,具体如下: 索引不仅能提高查询速度,还可以添加排序速度,如果order by 后面的语句用到了索引,那么将会提高排序的速度。 测试 1、创建测试表:t15表 2、插入1W行数据 3、商场网站,一般都会按照
-
我理解线性探测中的问题,即由于后续的索引,会出现元素簇。但是我不明白这句话
-
问题内容: 说,我有以下mixin通过触摸彼此重叠: 如果我希望我的视图通过该命令,请检查A->检查B,我的代码应该是还是? 为什么我们总是将其子类或子类放在mixins之后?(我通过阅读django通用视图的源代码注意到了这一点,但我不知道其背后的原理,如果有的话) 问题答案: MRO基本上是深度优先,从左到右。有关更多信息,请参见新型Python类中的方法解析顺序(MRO)。 你可以查看要检查
-
我有一个“用户”顶点,其中有几个用户。我有一个“邀请”顶点,它基本上讲述了一个用户发送给另一个用户的邀请。我有一个“sentTo”边,将邀请顶点与用户顶点(邀请的接收者)连接起来。我有一个“sentBy”边,将邀请顶点连接到用户顶点(发送邀请的用户)。sentBy edge有一个“on”属性,它是一个日期对象。sentBy edge还具有“inviterCount”属性,基本上是收件人用户(接收邀