
试图在整个列中查找值

我尝试了以下代码。
import pandas as pd
import numpy as np
excel_file = 'bank_acc.xlsx'
bank_acc = pd.read_excel(excel_file)
bank_acc.describe()
acc_no = 1
column1 = pd.read_excel(excel_file, index_cols=None, na_values=['NA'], usecols="A:C", skiprows=0)
if acc_no in column1:
print("found")
else:
print("not found")
但它总是打印“未找到”
我有以下excel文件:
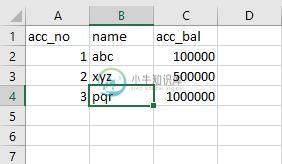
现在,如果我将acc_no的值更改为1、2或3,它将打印未找到的。如果我将acc_no的值从字符串“acc_no”更改为字符串“acc_no”,则会找到它。我想这意味着它总是只扫描第一行,而不是所有的行。。谁能给我一个建议或者我写了一个错误的代码。。。
共有1个答案

这是我的路。由于我发现了一些错误,我不得不删除我的旧答案。这应该行得通。
df = pd.read_excel("test.xlsx")
print(df)
acc_no = 3 # you can change this value
a = any(df['acc_no'] == acc_no)
if a == True:
print("Found")
else:
print("Not Found")
-
这里有一些示例来展示您的函数应该如何工作。 我已经两天没睡了,我能写的最好的代码是
-
我有一张地图清单
-
我正在使用MongoDB搜索包含列表列表的元素,其中列表中至少有一个项目与搜索参数匹配。 这是我目前拥有的结构的一个例子。 我想搜索数据列表中值为“绿色”的所有项目。 我目前有这个: 但是,不会返回任何结果。
-
问题内容: 关于你的第一个问题:该代码非常好,并且如果与其中的一个元素相等就可以正常工作。也许你尝试查找与其中一项不完全匹配的字符串,或者你使用的浮点值会导致不准确。 关于第二个问题:如果“查找”列表中的内容,实际上有几种可能的方法。 检查里面是否有东西 这是你描述的用例:检查列表中是否包含某些内容。如你所知,你可以使用in运算符: 过滤集合 即,找到满足特定条件的序列中的所有元素。你可以为此使用
-
如何找到python列表的中间位置? 这只是一个函数的例子,它可以找到任何列表的中间,你可以用列表理解来做这件事吗? 编辑:这与去掉中间点不同,因为我只想打印出中间值,如果列表是奇数,我想返回两个中间值,就像接受的答案一样。没有像另一个问题那样得到中值,而是得到两个值的平均值。
-
问题内容: 我对正则表达式很陌生。您能帮我创建一个匹配整个单词,包含特定部分的模式吗?例如,如果我有一个文本字符串“执行正则表达式匹配”,并且如果我搜索 express ,它将给我 expression ;如果我搜索 form ,它将给我 Perform 等。有这个主意吗? 问题答案: 哪里: 是单词边界 是一个或多个“单词”字符* 是零个或多个“单词”字符 有关PCRE的信息,请参见有关转义序列