
丢失、val_丢失、acc和val_acc不会在所有历代更新

我为序列分类(二进制)创建了一个LSTM网络,其中每个样本有25个时间步和4个特征。以下是我的keras网络拓扑:
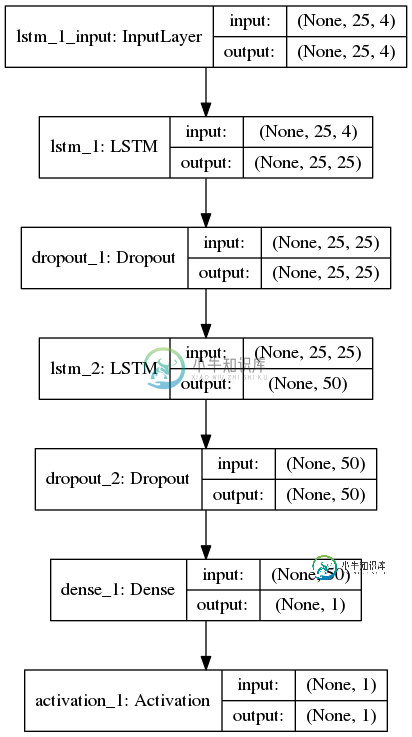
上面,密集层之后的激活层使用softmax功能。我使用二进制交叉熵作为损失函数,Adam作为优化器来编译keras模型。使用batch_size=256、shuffle=True和validation_split=0.05对模型进行训练,以下是训练日志:
Train on 618196 samples, validate on 32537 samples
2017-09-15 01:23:34.407434: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:893] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2017-09-15 01:23:34.407719: I tensorflow/core/common_runtime/gpu/gpu_device.cc:955] Found device 0 with properties:
name: GeForce GTX 1050
major: 6 minor: 1 memoryClockRate (GHz) 1.493
pciBusID 0000:01:00.0
Total memory: 3.95GiB
Free memory: 3.47GiB
2017-09-15 01:23:34.407735: I tensorflow/core/common_runtime/gpu/gpu_device.cc:976] DMA: 0
2017-09-15 01:23:34.407757: I tensorflow/core/common_runtime/gpu/gpu_device.cc:986] 0: Y
2017-09-15 01:23:34.407764: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1045] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1050, pci bus id: 0000:01:00.0)
618196/618196 [==============================] - 139s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 2/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 3/50
618196/618196 [==============================] - 134s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 4/50
618196/618196 [==============================] - 133s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 5/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 6/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 7/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
Epoch 8/50
618196/618196 [==============================] - 132s - loss: 4.3489 - acc: 0.7302 - val_loss: 4.4316 - val_acc: 0.7251
... and so on through 50 epochs with same numbers
到目前为止,我还尝试使用了rmsprop、nadam优化器和batch_size128, 512, 1024但是损失、val_loss、acc、val_acc在所有时代都保持不变,每次尝试的精确度在0.72到0.74之间。
共有1个答案

softmax激活可确保输出之和为1。它有助于确保在许多类中只输出一个类。
因为您只有一个输出(只有一个类),所以这肯定不是一个好主意。所有样本的结果可能都是1。
改用sigmoid。它与二进制交叉熵配合得很好。
-
问题内容: 我正在使用SQL数据库,我有一列名为“价格”。创建数据库后,将“价格”列设置为“我”,需要将其类型更改为不丢失数据库中的数据。这应该通过SQL脚本来完成 我想到了创建一个新列,将数据移到其中,删除旧列,然后重命名新创建的列。 有人可以帮我举个例子吗?在SQL中也有一个函数可以将字符串解析为十进制? 谢谢 问题答案: 您无需添加新列两次,只需在更新新列后删除旧列即可: 请注意,如果不是数
-
问题内容: 我今天犯了升级Eclipse的错误,现在无法启动新的Android项目。 我收到消息Proguard.cfg(找不到文件)。 我似乎在哪里找不到这东西?是否有可能摆脱它我在这个项目中不需要混淆… 谢谢 问题答案: 如果您确实不需要Proguard来混淆发行版,则可以从项目根文件夹的default.properties文件中删除以下行: proguard.config = proguar
-
免责声明: 然而,标记它的人,没有考虑到我跟随重复的帖子的回答没有排序我的问题。此外,这个问题涉及到从Java8到Java9的转移,当时Java9处于测试版。 在我的例子中,我正在从Java8升级到11(oracle,而不是openjdk),后者是Java的当前稳定版本。此外,我运行的是InteliJ的第二个最新版本(2018.3),最新版本是2018.3.1。 最后,我面临的问题不仅仅是某些包的
-
我试图以CSV格式保存py spark . SQL . data frame . data frame(也可以是其他格式,只要它易于阅读)。 到目前为止,我找到了几个示例来保存DataFrame。然而,每次我编写它时,它都会丢失信息。 数据集示例: 为了将这个文件保存为CSV,我首先尝试了这个解决方案: 不幸是,这导致了以下错误: 这就是我尝试另一种可能性的原因,将spark数据帧转换成panda
-
问题内容: 我想在我的网站上使用,但得到以下信息: 我试过打印。输出以下内容: 谁能帮助我找到或建议替代方案? 问题答案: 从文档中: 页面(如果有的话)的地址,该页面将用户代理引至当前页面。这是由用户代理设置的。并非所有的用户代理都将设置此功能,有些用户代理提供了将HTTP_REFERER修改为功能的功能。简而言之,它不能真正被信任。
-
问题内容: 我目前正在一个小项目上使用RPi 3B(最新的Raspbian Jessie),该项目涉及播放简短的.mp4文件。由于Pygame似乎支持播放.mpg文件,因此我将视频转换为该格式。 但是,当我尝试导入movie模块时,出现了常见的python导入错误: 经过研究,我发现其他人也遇到了与此处所述相同的问题。我真的不知道是否有解决方案,或者我在RPi上有什么替代方案。 Pygame,py