
Dynamodb模式设计(将关系数据映射到nosql)

我想了解一下这个例子,从AWS映射关系模型到nosql
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-modeling-nosql-B.html
这里强调的一个关键概念是:
重要的
.... 大多数设计良好的应用程序只需要一个表。。。
因此,示例表如下
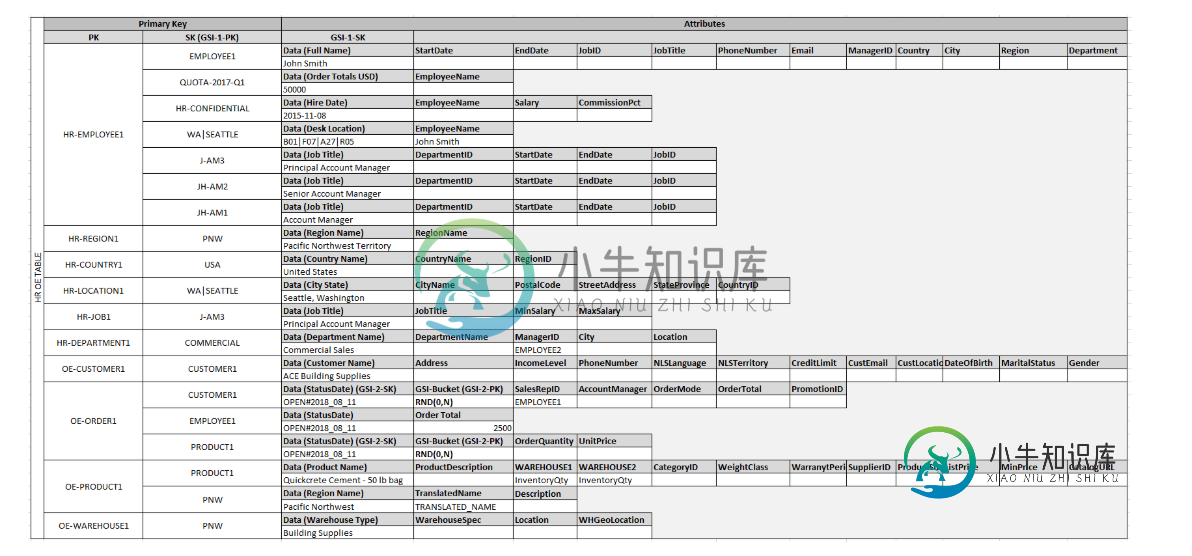
它解释了,
您可以定义以下实体,这些实体支持关系订单条目模式:
HR员工-主键:员工ID,主键:员工姓名
HR区域-主键:区域ID,主键:区域名称
...
但是,示例表中的实体HR Employee-PK:EmployeeID,SK:Employee Name具有SK值,这些值不是Employee Names。
此外,它建议以下查询

但是GSI-1没有员工名的PK。
我理解这可能是AWS文档中的一个差异,我应该向他们提出(我有,他们在后续工作中表现得非常糟糕),但我不确定的是文档是否正确,我的理解是否错误(我倾向于相信后者,因为AWS文档通常是准确的)。
有人能在nosql模式映射方面为我指明正确的方向吗?对于上面链接中的模式,一个正确的示例(带有dynamo表的示例记录)将非常有价值。
共有1个答案

所以我会试着让你更清楚,让我知道如果有些事情仍然没有意义。
首先,您提到以下事实:
但是,示例表中的实体HR-雇员-PK:雇员ID、SK:雇员名称的SK值不是雇员名称。
存在不是“员工姓名”的SK值的原因是,SK不仅用于“员工姓名”,还用于其他查询(如地区名称、国家名称等)。把SK想象成它的确切含义,一个排序键。文档中似乎没有解释额外的SK,所以让我总结一下您所看到的内容。
您有HR-Employee1,员工姓名=Employee1,QuotaID(猜猜这个键是什么)=配额-2017-Q1,其他一些键=HR-机密
这些键名实际上并没有在表中定义,它们都位于排序键下,并且只是隐式的“雇员名”或“配额id”或“区域名”。
这允许您使用employeeID作为主键、EmployeeName作为主键来查询员工数据,但也允许您使用employeeID作为主键、QuoteAid作为主键来查询员工配额数据(或其他数据)。
关于GSI-1的第二个问题也是如此。本质上,在这个场景中,他们设计表的方式是使用一个SK“SortKey”,在这里可以有各种类型的值进行排序,如果这样做有意义的话。
-
本文向大家介绍浅析php设计模式之数据对象映射模式,包括了浅析php设计模式之数据对象映射模式的使用技巧和注意事项,需要的朋友参考一下 php中的设计模式中有很多的各种模式了,在这里我们来为各位介绍一个不常用的数据映射模式吧,希望文章能够帮助到各位。 数据映射模式使您能更好的组织你的应用程序与数据库进行交互。 数据映射模式将对象的属性与存储它们的表字段间的结合密度降低。数据映射模式的本质就是一个类
-
我不确定这是否是问这个问题的正确地方。 我是dynamodb的新手,正在尝试创建一个小型web应用程序。我已经阅读了这里的最佳实践http://docs.amazonwebservices.com/amazondynamodb/latest/developerguide/BestPractices.html 我的桌子将是: 建筑物 租户(一栋建筑可以有尽可能多的租户,由楼层编号确定) 收件人(每个
-
问题内容: 我有一个表,其记录表示某些对象。为了简单起见,我将假定该表只有一列,这是唯一的。现在,我需要一种方法来存储该表中对象的组合。组合必须是唯一的,但可以是任意长度。例如,如果我有s 我想存储以下组合: 不需要订购。我当前的实现是要有一个将s映射到s的表。因此,每个组合都会收到一个唯一的ID: 这是上面示例的前两个组合的映射。问题在于,查找特定组合的的查询似乎非常复杂。该表的两个主要使用方案
-
如何在spring数据R2DBC中使用映射,以获取具有接收/发送到数据库的关系的映射表/实体?使用r2dbcCustomConversions、@WritingConverter和@ReadingConverter。有人可以给予。一些实例谢谢
-
我使用jooq针对本地数据库生成对象,但在以后的生产中运行“for real”时,实际数据库将具有不同的名称。为了解决这个问题,我使用
-
前两章――动态数据模式与表数据网关模式各自展示对记录与每个表进行抽象的策略。这些模式都很有用,但每一个模式的执行都与底层的数据库结构结合过于紧密,因此基于以上模式的解决方案就存在一定的问题。比如,你的代码用字段名作为数组的关键字或是行数据对象的属性,则你的应用就受到数据库结构的约束,并且每当表结构发生哪怕是很小的变化,你都不得不在你的PHP程序中做大量的修改。 因为代码与数据库结构在开发过程经常变