
Akka演员是如何清理资源的?

我们在使用Akka HTTP构建的web服务器上遇到了奇怪的内存行为。我们的架构是这样的:
- Web服务器路由调用各种参与者,为将来获取结果并将其流式传输到响应
- 参与者调用非阻塞操作(使用期货),组合和处理从中提取的数据,并将结果传送给发送者。我们使用标准的Akka Actor,实现它的receive方法(不是Akka键入的)
- 应用程序中的任何地方都没有阻止代码
当我在本地运行web服务器时,一开始大约需要350 MB。在第一个请求之后,内存使用量会跃升到430 MB左右,并且随着每个请求(使用Mac上的活动监视器进行监视)而缓慢增加。但是GC不应该在每个请求之后清理东西吗?处理后的内存使用量不应该再是350 MB吗?
我还安装了YourKit java profiler,下面是头内存的一个图
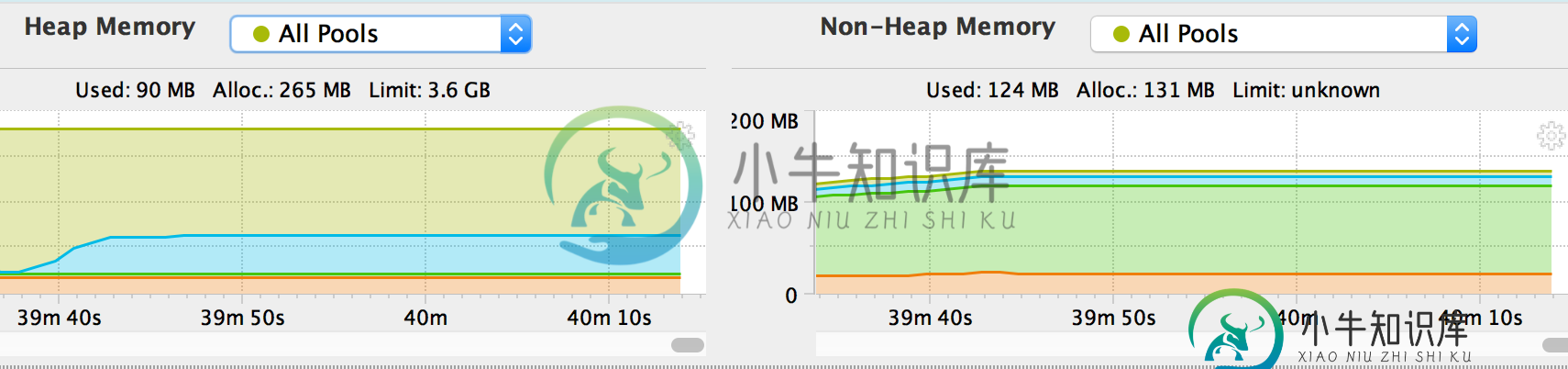
可以看出,一旦内存使用量增加,它就不再返回,系统是无状态的。还有,当我从探查器手动运行GC时,它几乎什么都不做,只是内存使用量的一个小的减少。我知道有些服务可能会在第一次请求后缓存东西,暂时消耗内存,但是在Akka Actors或Akka HTTP中有没有关于这一点的策略?
我试图检查离GC最远的对象,但它只显示库类和类中构建的Akka,与我们的代码无关。
- 执行元如何在消息处理后关闭资源并释放内存?你经历过类似的事情吗?
- 有没有更好的分析Akka HTTP的方法,可以向我展示最远离GC使用classed的stacktrace?
另外,在Actors内部使用调度程序(在Akka HTTP服务器内部运行)是否可取?当我这样做时,似乎内存使用量增加了很多,应用程序在开发环境中运行我们的内存。
先谢谢你,
阿默尔
共有1个答案

执行元保持活动状态,直到显式停止:没有垃圾回收。
管理参与者生存期的两种最常见的方法(除了参与者自己决定是时候停止之外)可能是:
>
家长负责阻止孩子。例如,如果派生参与者是为了代表父级执行特定任务,则需要使用这种方法。
使用非活动超时。如果参与者表示域实体(例如。每个用户帐户的执行元,其中该执行元在某种意义上充当内存缓存),使用context.setReceiveTimeout使ReceiveTimeout消息在超时后发送到执行元(请注意,在某些情况下,如果消息已在邮箱中排队,但在超时过期时未处理,则该消息的计划发送可能无法及时取消:接收ReceiveTimeout并不能保证自上次接收的消息后超时已过)是一个相当合理的解决方案,特别是如果使用Akka持久性和Akka集群分片来恢复执行元的状态。
更新以添加:
关于
GC不是应该在每次请求后清理东西吗?
-
我很难理解Akka中的演员,以及一个线索如何与一个演员相关联。 让我们以Fridge Actor和Person Actor向Fridge Actor引用发送GetFoodMessage为例。假设不变性受到尊重。 这些消息是在不同的线程中“同时”处理,还是在队列中一个接一个地处理? 线程产卵是否完全由库管理并从actor的概念中抽象出来? 参与者引用是参与者的实例吗? 当我阻止一个演员(和他的孩子)
-
问题内容: 我有一个不是actor的java对象,它使用actorSelection(Path)从一个actor系统中选择actor。系统中可能不存在所选参与者。 在Java Api中,ActorSelection不存在ask(),因此我无法向actor选择发送和标识消息并使用响应的发送者。 我试图通过演员选择将消息发送给演员,然后对死信做出反应来解决该问题。但是我没有任何死信。 如何通过Acto
-
我从这里得到上面的错误消息: 特别是从第二行。。进口是 akka版本是2.2.1,scala是2.10.2,我正在使用sbt 0.13来构建它。 编辑:我用 结果如下:
-
我很想知道调整大小,或者在本例中增加单个节点系统上的actor池中actor的数量是否真的会影响性能。 我有一个带超线程的四核系统。在任何给定的点上,系统可以运行8个线程。假设执行元执行的大多数操作都是CPU绑定的,那么将池中的执行元数量从20个增加到40个会有什么收获呢?
-
我正在将现有应用程序从Akka Classic移植到Akka Typed。最初,您可以使用上下文获取对参与者的引用。actorSelection()。resolveOne() 我知道在Akka Type中不再支持这一点,我们应该使用来注册演员以供发现。 但是,我只想将消息发送到本地参与者,即存在于集群中每个节点上的本地单例。我有它的本地路径,但没有对它的直接引用。这是因为它是由Akka管理系统创建