
如何管理Spark结构化流中的偏移?(_spark_metadata的问题)

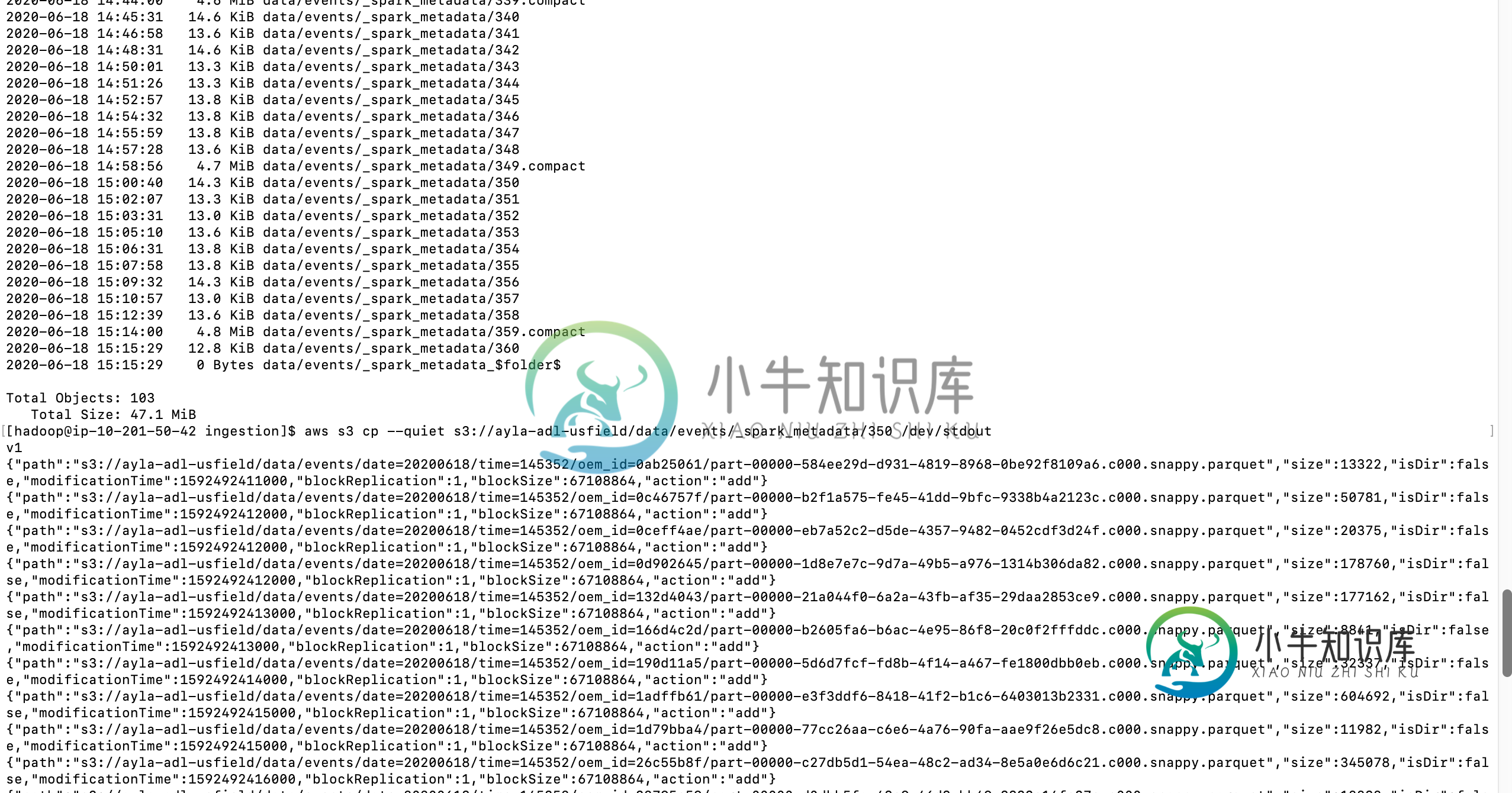
背景:我写了一个简单的spark结构化蒸app,把数据从Kafka搬到S3。我发现,为了支持一次准确的保证,spark创建了_spark_metadata文件夹,但该文件夹最终变得太大,当流应用程序运行很长时间时,元数据文件夹变得太大,以至于我们开始出现OOM错误。我想摆脱Spark结构化流的元数据和检查点文件夹,自己管理偏移量。
我们如何管理Spark Streaming中的偏移量:我使用了val offsetRanges=rdd.asInstanceOf[HasOffsetRanges].offsetRanges来获取Spark结构化流中的偏移量。但是想知道如何获取偏移量和其他元数据来使用Spark结构化流管理自己的检查点。您有没有实现检查点的示例程序?
我们是如何在Spark结构化流中管理偏移的??看看这个JIRA https://issues-test.apache.org/JIRA/browse/spark-18258。似乎没有提供偏移。我们该怎么走呢?
代码:
1. Reading records from Kafka topic
Dataset<Row> inputDf = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.option("startingOffsets", "earliest") \
.load()
2. Use from_json API from Spark to extract your data for further transformation in a dataset.
Dataset<Row> dataDf = inputDf.select(from_json(col("value").cast("string"), EVENT_SCHEMA).alias("event"))
....withColumn("oem_id", col("metadata.oem_id"));
3. Construct a temp table of above dataset using SQLContext
SQLContext sqlContext = new SQLContext(sparkSession);
dataDf.createOrReplaceTempView("event");
4. Flatten events since Parquet does not support hierarchical data.
5. Store output in parquet format on S3
StreamingQuery query = flatDf.writeStream().format("parquet")
Dataset dataDf=inputdf.select(from_json(col(“value”).cast(“string”),EVENT_SCHEMA).alias(“event”)).select(“event.metadata”,“event.data”,“event.connection”,“event.registration_event”,“event.version_event”);SQLContext SQLContext=新建SQLContext(sparkSession);DataDf.CreateOrReplaceTempView(“事件”);Dataset flatDf=sqlContext.sql(“Select”+“date,time,id”+flattenSchema(EVENT_SCHEMA,“Event”)+“from Event”);StreamingQuery query=flatDf.WriteStream().OutputMode(“append”).Option(“Compression”,“Snappy”).Format(“Parquet”).Option(“checkpointLocation”,checkpointLocation“.Option(”Path“,outputPath).PartitionBy(”Date“,”Time“,”ID“).Trigger(Trigger.ProcessingTime(triggerProcessingTime)).Start();Query.AwaitTermination();
共有1个答案

对于非批处理Spark结构化流KAFKA集成:
报价:
结构化流忽略Apache Kafka中提交的偏移量。
优秀参考:https://www.waitingforcode.com/apache-spark-structure-streaming/apache-spark-structure-streaming-apache-kafka-offsets-management/read
对于批处理,情况不同,您需要自己管理并存储偏移。
更新基于评论,我建议问题略有不同,建议您看看Spark结构化流检查点清理。除了您更新的评论和没有错误的事实之外,我建议您在Spark Structured Streaming的元数据https://www.waitingforcode.com/apache-spark-structured-streaming/checkpoint-storage-structured-streaming/read上确认这一点。看代码,与我的风格不同,但看不到任何明显的错误。
-
我正在研究为Spark结构化流在kafka中存储kafka偏移量,就像它为DStreams工作一样,除了结构化流,我也在研究同样的情况。是否支持结构化流?如果是,我如何实现? 我知道使用进行hdfs检查点,但我对内置的偏移量管理感兴趣。 我期待Kafka存储偏移量只在内部没有火花hdfs检查点。
-
我的项目中有一个场景,我正在使用spark-sql-2.4.1版本阅读Kafka主题消息。我能够使用结构化流媒体处理一天。一旦收到数据并进行处理后,我需要将数据保存到hdfs存储中的各个拼花文件中。 我能够存储和读取拼花文件,我保持了15秒到1分钟的触发时间。这些文件的大小非常小,因此会产生许多文件。 这些拼花地板文件需要稍后通过配置单元查询读取。 那么1)该策略在生产环境中有效吗?还是会导致以后
-
场景与经典的流连接略有不同 交易流: transTS, userid, productid,... streamB:创建的新产品流:productid、productname、createTS等) 我想加入与产品的交易,但我找不到水印/加入条件的组合来实现这一点。 结果为空。 我做错了什么?
-
我正在用Kafka运行一个结构化流应用程序。我发现如果系统因为某种原因停机几天...检查点变得过时,并且在Kafka中找不到与该检查点相对应的偏移量。我如何让Spark结构化流应用程序选择最后一个可用的偏移量,并从那里开始。我尝试将偏移量重置设置为“早期/最新”,但系统崩溃,出现以下错误:
-
Spark(v2.4)程序功能: 在spark中以结构化流模式从Kafka队列读取JSON数据 按原样在控制台上打印读取的数据 问题获取: -获取
-
在过去的几个月里,我已经使用了相当多的结构化流来实现流作业(在大量使用Kafka之后)。在阅读了《Stream Processing with Apache Spark》一书之后,我有这样一个问题:有没有什么观点或用例可以让我使用Spark Streaming而不是Structured Streaming?如果我投入一些时间来研究它,或者由于im已经使用了Spark结构化流,我应该坚持使用它,而之