
Spark Executor在向拼花地板写入数据帧时性能低下

Spark版本:2.3 hadoop dist:azure Hdinsight 2.6.5平台:azure存储:BLOB
集群中的节点:6个执行器实例:每个执行器6个内核:每个执行器3个内存:8gb
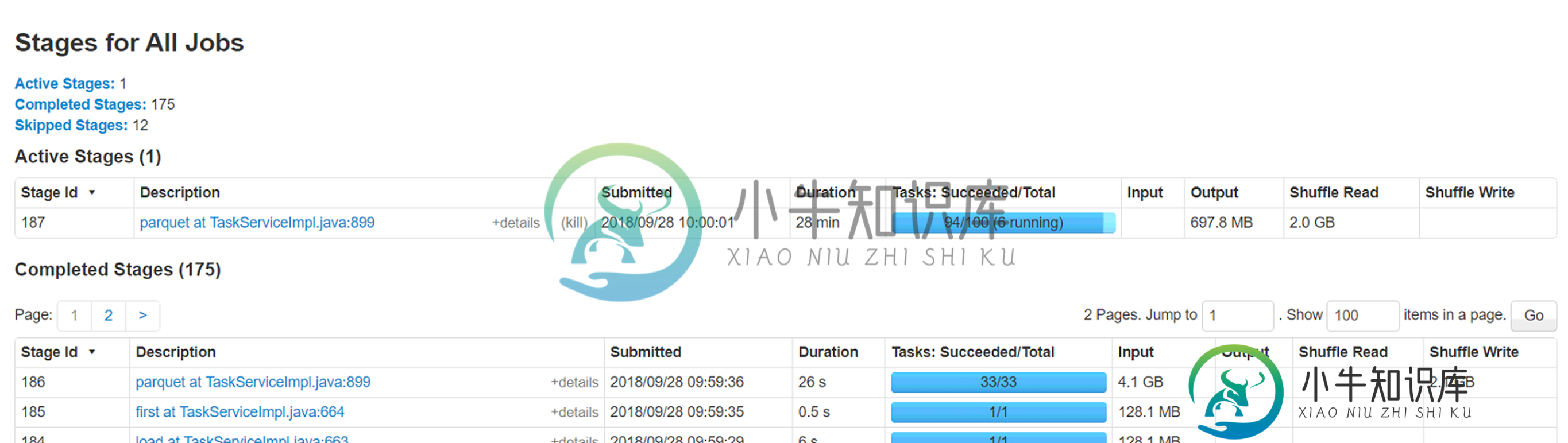
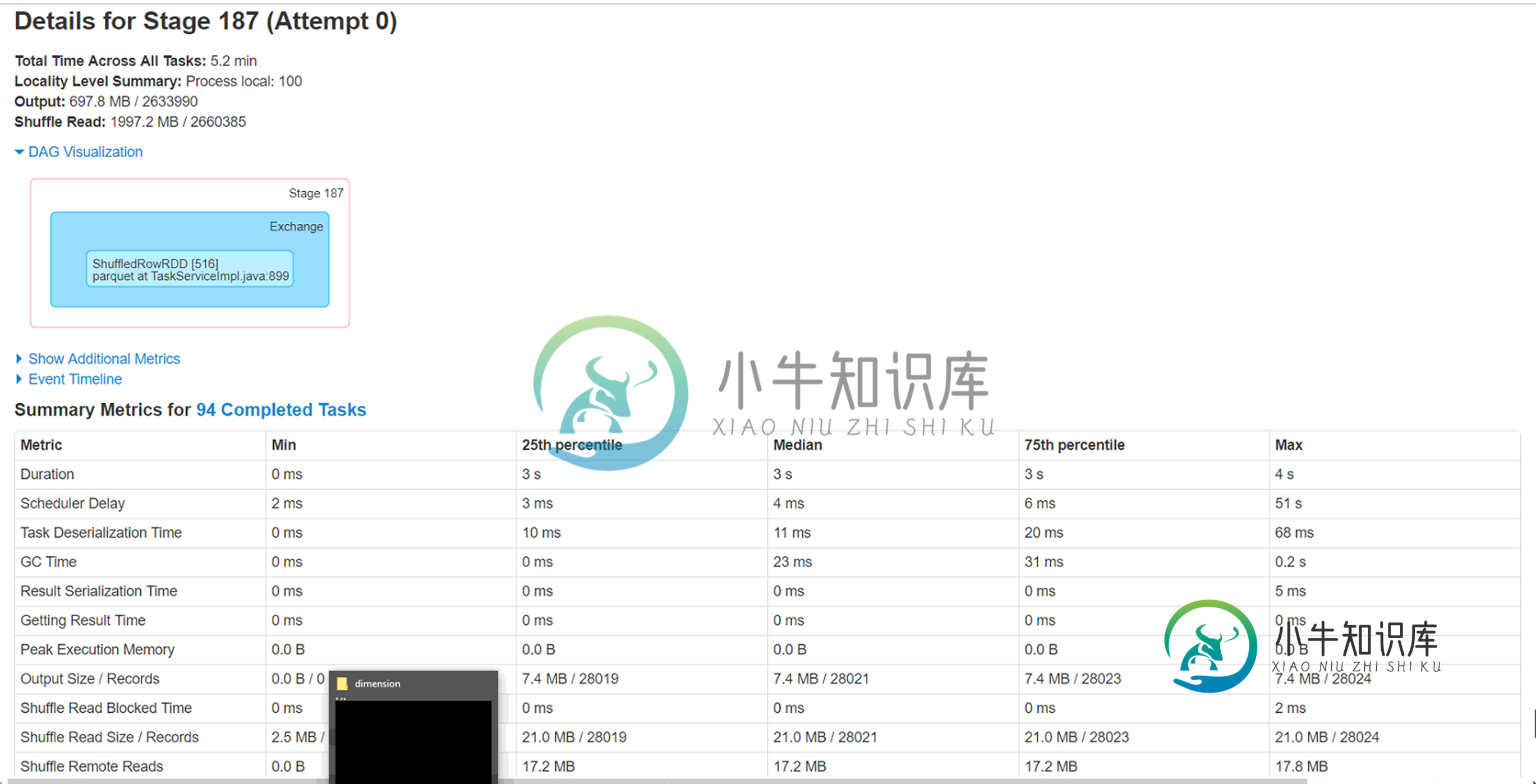
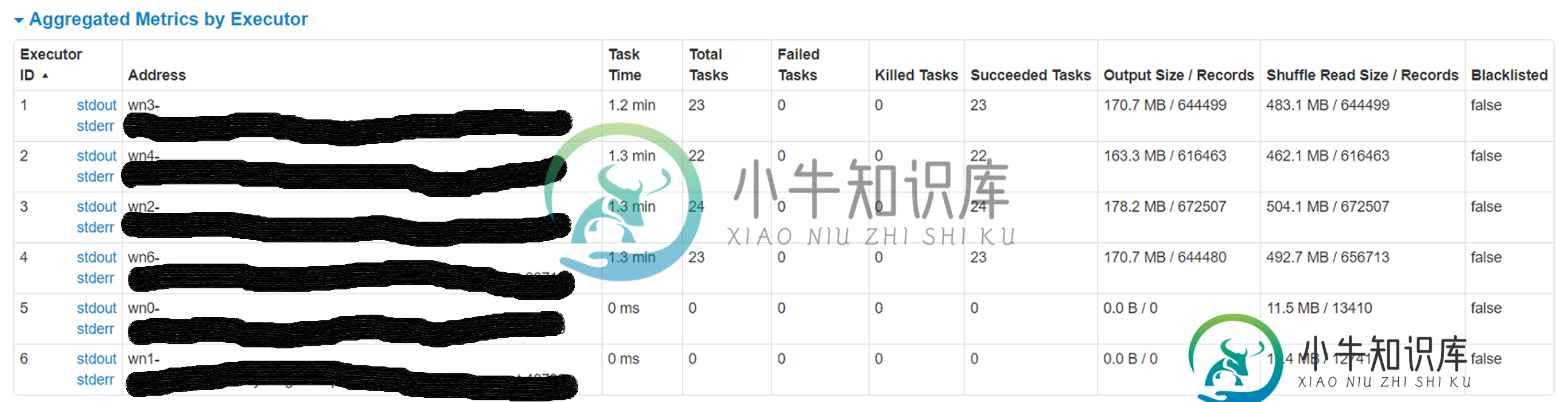
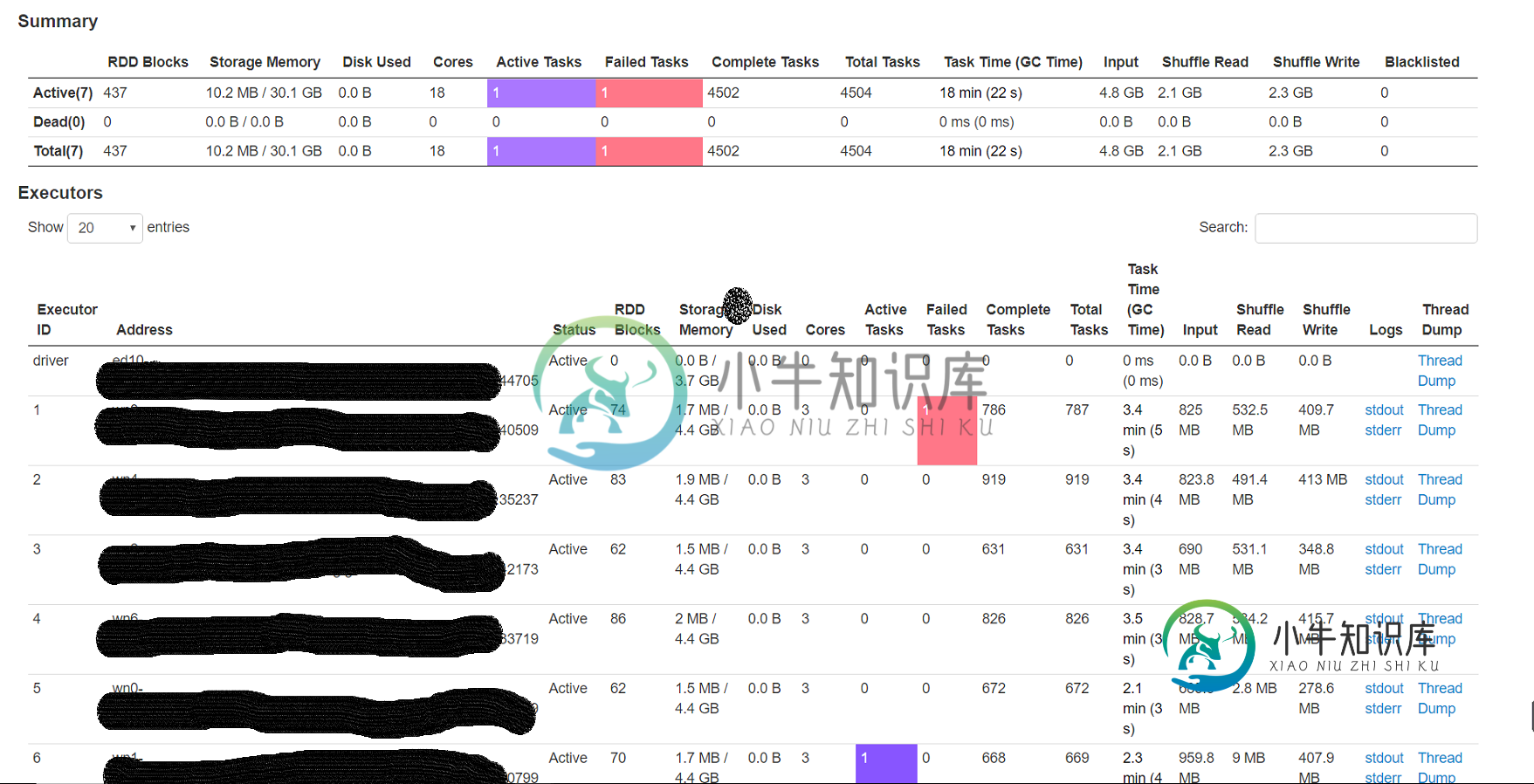
试图通过同一存储帐户上的spark数据框将azure blob(wasb)中的csv文件(大小4.5g-280列,2.8 mil行)加载到拼花格式。我重新划分了大小不同的文件,即20、40、60、100,但面临一个奇怪的问题,即6个执行者中有2个处理非常小的记录子集(

问题:
1) 这两个执行者正在处理的分区需要处理的记录最少(少于1%),但需要将近一个小时才能完成。原因是什么。这是否与数据倾斜的情况相反?
2) 运行这些执行器的节点上的本地缓存文件夹正在被填满(50-60GB)。不确定这背后的原因。
3) 增加分区确实会使总的执行时间降低到40分钟,但只想知道这两个执行器的低吞吐量背后的原因。
对于spark来说是个新手,所以期待着一些指导来调整这个工作负载。附加Spark WebUi的附加信息。
共有1个答案

您使用的是什么hadoop集群环境?
1) 答:你是在写文件时唱partitionColumnBy吗?否则就试试看。
2) 答:增加分区的数量,即使用“spark.sql.shuffle.partitions”
3) 答:需要更具体的信息,如样本数据等,才能给出答案。
-
我在Spark 2.1.0/Cassandra 3.10集群(4台机器*12个内核*256个RAM*2个SSD)上工作,很长一段时间以来,我一直在努力使用Spark Cassandra connector 2.0.1向Cassandra写入特定的大数据帧。 这是我的表的模式 用作主键的散列是256位;列表字段包含多达1MB的某种结构化类型的数据。总共,我需要写几亿行。 目前,我正在使用以下写入方法
-
如何将数据帧中的数据写入到单个。拼花地板文件(两个数据 df.rdd.get1个分区 1个 如果我使用上述命令在HDFS中创建拼花文件,它将在HDFS中创建目录“payloads.parquet”,并在该目录中创建多个文件。拼花地板文件,元数据文件正在保存。 找到4项 如何将数据帧中的数据写入单个文件(两个数据 帮助将不胜感激。
-
我试图做一些非常简单的事情,我有一些非常愚蠢的挣扎。我想这一定与对火花的基本误解有关。我非常感谢任何帮助或解释。 我有一张非常大的桌子(~3 TB,~300毫米行,25k个分区),在s3中保存为拼花地板,我想给一些人一个很小的拼花文件样本。不幸的是,这要花很长时间才能完成,我不明白为什么。我尝试了以下方法: 然后当这不起作用时,我尝试了这个,我认为应该是一样的,但我不确定。(我添加了,以尝试调试。
-
当我在所有任务成功后将数据帧中的数据写入拼花地板表(已分区)时,该过程在更新分区统计信息时陷入了困境。 我的桌子有
-
我正试图在模式下将写入文件格式(在最新的pandas版本0.21.0中引入)。但是,文件将被新数据覆盖,而不是附加到现有文件。我错过了什么? 写入语法是 读取语法是
-
我有一个很大的数据框,我正在HDFS中写入拼花文件。从日志中获取以下异常: 谷歌对此进行了搜索,但找不到任何具体的解决方案。将推测设置为false:conf.Set(“spark.投机”,“false”) 但仍然没有帮助。它只完成了几个任务,生成了几个零件文件,然后突然因此错误而停止。 详细信息:Spark版本:2.3.1(这在1.6x中没有发生) 只有一个会话正在运行,这排除了不同会话访问同一位