
字符集或字符编码问题?这是一个很好的例子

我正在移动我的网站到另一个主机,因为它缺乏支持,从星期六起就不运作了。
在新的主机上,我的网站将一些字符显示为带有问号()的黑色菱形,而不是正确的符号(á,ç,è,等等)
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
它是使用phpadmin导入的,并且映射字符集被设置为UTF-8
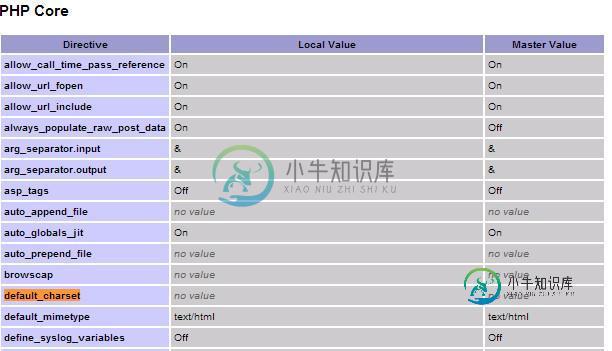
-
null
谢谢
共有1个答案

尝试在文件顶部使用utf-8字符集:
header('Content-Type: text/html; charset=utf-8');
-
我们都知道计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),0 - 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A 的编码是 65,小写字母 z 的编码是 122。 如果要表示中
-
问题内容: 我遇到以下字符编码问题,以某种方式设法将具有不同字符编码的数据保存到数据库(UTF8)中,下面的代码和输出显示2个示例字符串以及它们的输出方式。其中之一需要更改为UTF8,而另一个已经更改为。 如何/应该去检查是否应该对字符串进行编码? 例如,我需要正确输出每个字符串,那么如何检查它是否已经是utf8或是否需要转换? 我正在使用PHP 5.2,mysql myisam表: 输出1: 输
-
像其它大多数的Java应用程序一样,FreeMarker使用 "UNICODE 文本"(UTF-16)来工作。 不过,也有必须处理 字符集 的情况, 因为它不得不和外界交换数据,这就会使用到很多字符集。 输入的字符集 当 FreeMarker 要加载模板文件(或没有解析的文本文件)时, 那就必须要知道文件使用的字符集,因为文件的存储是原生的字节序列。 可以使用 encoding 配置 来确定字符集
-
问题内容: 我目前正在使用ReactJS和webpack构建一个网站。 我的文本编辑器设置为编码,并且使用带重音或特殊字符的字符,例如。 在我的html页面中,我相信我使用的配置正确: 但是特殊字符的渲染方式不正确: 例如,而不是。 我尝试设置,但没有任何改变。 我觉得webpack正在使用编码构建,这使我的角色停滞不前。我该如何解决这个问题? 问题答案: 我没有找到一种使Webpack读取UTF
-
在本书第1篇“第3章安装Git”中,就已经详细介绍了不同平台对本地字符集(如中文)的支持情况,本章再做以简单的概述。 Linux、Mac OS X以及Windows下的Cygwin缺省使用UTF-8字符集。Git运行这这些平台下,能够使用本地语言(如中文)写提交说明、命名文件,甚至使用本地语言命名分支和里程碑。在这些平台上唯一要做的就是对Git进行如下设置,以便使用了本地语言(如中文)命名文件时,
-
我遇到了一个关于编码蝙蝠的问题,问题是: 给定一个字符串,返回一个由原始字符串的最后2个字符的3个副本组成的新字符串。字符串长度至少为2。我解决了这个问题,解决方案(下图)比我的好,但是,解决方案代码有一个问题,当字符串长度小于2时,假设长度只有1。str索引将是-1。代码还能工作吗?为什么网站说解决方案是正确的?