
gremlin查询以检索它们之间具有多条边的顶点

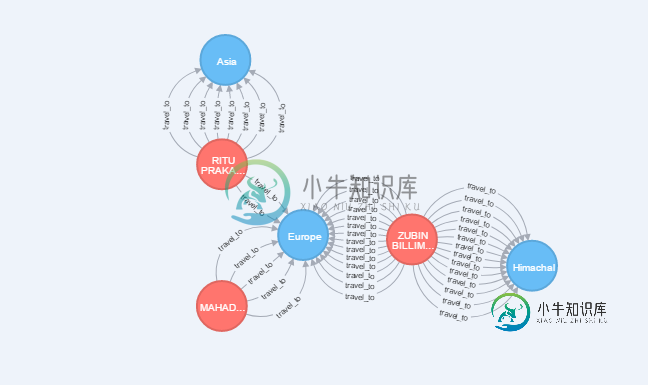
考虑上图。我想要一个小精灵查询,返回所有在它们之间有多条边的节点,如图所示。
该图是使用neo4j cypher查询获得的:MATCH(d:dest)-[r]-(n:cust),其中d,n,count(r)作为常用返回d,n,按常用描述极限5排序
例如:在RITUPRAKA…和Asia之间有8条多条边,因此查询返回了2个节点和边,对于其他节点也是如此。
注意:图中有其他节点,它们之间只有一条边,这些节点不会返回。
我想在《小精灵》中也做同样的事情。
我使用了下面给出的查询g.V().as('out').out().as('in')。select('out','in')。groupCount()。unfold()。filter(select(values)。is(gt(1))。select(keys)
它显示出:v[1234],在:v[3456]......
但我不想显示节点的ID,而是想显示节点的值,比如out:ICIC1234,in:HDFC234
我已将查询修改为g。V()。值(“名称”)。as('out')。out()。as('in')。值(“name”)。选择('out','in')。groupCount()。展开()。过滤器(选择(值)。是(gt(1)))。选择(键)
但它显示的错误就像class castException一样,每个要遍历的顶点都使用索引进行快速迭代
共有2个答案

我的建议类似于Stephen的建议,但也包括边缘,或者更确切地说是整个路径(我猜Cypher查询也返回了边缘)。
g.V().as("dest").outE().inV().as("cust").
group().by(select("dest","cust")).by(path().fold()).
unfold().filter(select(values).count(local).is(gt(1))).
select(values).unfold()

你的图似乎并没有表明双向边是可能的,所以我将在回答时牢记这个假设。这是一个简单的示例图-请考虑包含一个关于未来问题的示例图,因为它比图片和文本描述更容易让阅读您的问题的人理解并开始编写一个小精灵遍历来帮助您:
g.addV().property(id,'a').as('a').
addV().property(id,'b').as('b').
addV().property(id,'c').as('c').
addE('knows').from('a').to('b').
addE('knows').from('a').to('b').
addE('knows').from('a').to('c').iterate()
所以你可以看到顶点“a”有两条到“b”的外边缘和一条到“c”的外边缘,因此我们应该得到“a b”顶点对。一种方法是:
gremlin> g.V().as('out').out().as('in').
......1> select('out','in').
......2> groupCount().
......3> unfold().
......4> filter(select(values).is(gt(1))).
......5> select(keys)
==>[out:v[a],in:v[b]]
上述遍历使用groupCount()计算“out”和“in”标记顶点出现的次数(即它们之间的边数)。它使用unfold()迭代
也许另一种方法是使用这种方法:
gremlin> g.V().filter(outE()).
......1> project('out','in').
......2> by().
......3> by(out().
......4> groupCount().
......5> unfold().
......6> filter(select(values).is(gt(1))).
......7> select(keys)).
......8> select(values)
==>[v[a],v[b]]
这种使用project()的方法放弃了对整个图上的大group Count()的较重内存要求,转而在单个Vertex上构建较小的Map,该Vertex在by()结束时符合垃圾回收机制的条件(或基本上每个处理的初始顶点)。
-
如何在Gremlin查询中检索从根顶点开始的所有顶点属性? 我们有以下结构: 根顶点:Employee 边缘:EdCompany,EdDepartment,EdRole顶点:公司,部门,角色 我们试图接收与根顶点连接的其他顶点的数据。有人这样想: 我们尝试了该查询,但返回了一个复杂的JSON: 编辑: 我们还尝试了Kelvin建议的查询: 堆栈跟踪:提交查询失败:g.V().hasLabel(“E
-
我是gremlin查询的新手。我有一个如下图,我的源顶点是P3,我想编写一个查询,它将获取所有父\祖先顶点(如果有一条从该顶点到P3的路径,其边缘类型为“包含”)类型为“部分”,并与它们关联一个Owner。所以在这种情况下,查询应该返回P1和P2,而不是P。 查询以创建样本数据: 这是我提出的查询,但遍历一旦找到一个具有相关所有者顶点的零件顶点,就会停止。如何更新它以返回P1和P2。 我还尝试了使
-
我在我的应用程序中使用gremlin REST服务器,我想在单个查询中为一个顶点创建多个边。我有从哪里创建边缘到单个顶点的顶点ID列表。 对于eg-g.V(12,13,14,15)。添加(“使用”,g.V(100)) 我已经尝试了许多遍历步骤,但无法使其工作。
-
我只是在玩Cosmos DB中的Graph API,它使用Gremlin语法进行查询。 我在图中有许多用户(顶点),每个用户对其他用户都有“知道”的属性。其中一些是外边缘(outE),另一些是内边缘(inE),具体取决于关系的创建方式。我现在尝试创建一个查询,该查询将返回给定用户(顶点)的所有“已知”关系。我可以通过以下方式轻松获取inE或outE的ID: 其中是我正在查询的用户的ID,但我无法提
-
好吧,问题很简单,但我不知道怎么做。我试着逐个检查两个元素,但这不是最好的方法。我有一组圆形物体。数组有位置字段X和Y。我想遍历数组,检查所有元素是否在一条线上(水平或垂直)。我如何通过数组检查圆心是否在同一条线上。 我试着做这样的事情,看看圆圈是否在同一条垂直线上,但我说它需要一个元素与邻居。
-
我的场景是在单个查询中在顶点之间添加多条边: 假设下面的节点:这些是我拥有的标签和ID 用户: 4100 歌曲: 4200 4355 4676 我必须在这些顶点之间建立边 我们通常可以通过在节点之间创建单条边来实现。如果我们想一次在50多个顶点之间创建边,这不是一种有效的方法。我正在使用Tinkerpop 3.0.1。