
如何编写Gremlin查询以查找具有指定边的父顶点?

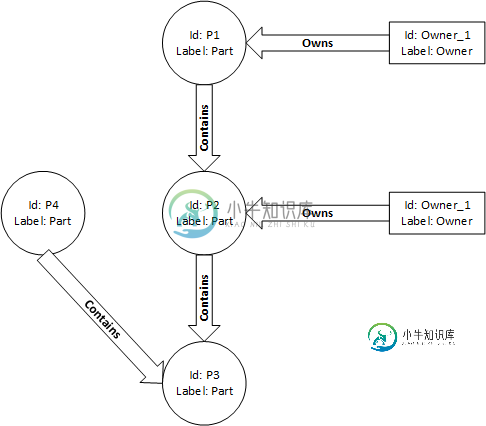
我是gremlin查询的新手。我有一个如下图,我的源顶点是P3,我想编写一个查询,它将获取所有父\祖先顶点(如果有一条从该顶点到P3的路径,其边缘类型为“包含”)类型为“部分”,并与它们关联一个Owner。所以在这种情况下,查询应该返回P1和P2,而不是P。
查询以创建样本数据:
g.addV(id, 'P1').property('label','part').as('p1')
.addV(id, 'P2').property('label','part').as('p2')
.addV(id, 'P3').property('label','part').as('p3')
.addV(id, 'P4').property('label','part').as('p4')
.addV(id, 'owner1').property('label','owner').as('o1')
.addV(id, 'owner2').property('label','owner').as('o2')
.addE('contains').from('p1').to('p2')
.addE('contains').from('p2').to('p3')
.addE('contains').from('p4').to('p3')
.addE('owns').from('o1').to('p1')
.addE('owns').from('o2').to('p2')
这是我提出的查询,但遍历一旦找到一个具有相关所有者顶点的零件顶点,就会停止。如何更新它以返回P1和P2。
g.V('P3')
.union(
inE().hasLabel('owns').inV(),
repeat(inE().hasLabel('contains')
.outV().hasLabel('part'))
.until(inE().hasLabel('owns'))
).dedup()
我还尝试了使用边际效应步骤来收集部分顶点,但没有得到所需的结果。
g.V('P3').union(
inE().hasLabel('owns').inV(),
repeat(inE().sideEffect(hasLabel('owns').outV().as('parts'))
.hasLabel('contains')
.outV().hasLabel('part'))
)
.select('parts').dedup()
共有1个答案

由于语法错误,我修改了您的示例数据代码:
gremlin> g = TinkerGraph.open().traversal()
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.addV('part').property(id, 'P1').as('p1').
......1> addV('part').property(id, 'P2').as('p2').
......2> addV('part').property(id, 'P3').as('p3').
......3> addV('part').property(id, 'P4').as('p4').
......4> addV('owner').property(id, 'owner1').as('o1').
......5> addV('owner').property(id, 'owner2').as('o2').
......6> addE('contains').from('p1').to('p2').
......7> addE('contains').from('p2').to('p3').
......8> addE('contains').from('p4').to('p3').
......9> addE('owns').from('o1').to('p1').
.....10> addE('owns').from('o2').to('p2').iterate()
我认为可以将遍历简化为一个简单的repeat():
gremlin> g.V('P3').emit(inE('owns')).repeat(__.in('contains'))
==>v[P2]
==>v[P1]
注意控制循环输出顶点的emit()步骤的位置。
-
考虑上图。我想要一个小精灵查询,返回所有在它们之间有多条边的节点,如图所示。 该图是使用neo4j cypher查询获得的:MATCH(d:dest)-[r]-(n:cust),其中d,n,count(r)作为常用返回d,n,按常用描述极限5排序 例如:在RITUPRAKA…和Asia之间有8条多条边,因此查询返回了2个节点和边,对于其他节点也是如此。 注意:图中有其他节点,它们之间只有一条边,这
-
我只是在玩Cosmos DB中的Graph API,它使用Gremlin语法进行查询。 我在图中有许多用户(顶点),每个用户对其他用户都有“知道”的属性。其中一些是外边缘(outE),另一些是内边缘(inE),具体取决于关系的创建方式。我现在尝试创建一个查询,该查询将返回给定用户(顶点)的所有“已知”关系。我可以通过以下方式轻松获取inE或outE的ID: 其中是我正在查询的用户的ID,但我无法提
-
我需要从一个顶点开始,找到所有相关的顶点,直到结束。标准是匹配边inV顶点中的任何一个边属性(属性)。如果边缘属性“value”与inV顶点“attribute”名称不匹配,我应该跳过该顶点。边的属性值作为属性名称传播到inV顶点中 我使用下面的查询,但这给了我父节点、下一个节点和之间的边的json输出。通过输出am写入逻辑,仅拾取与边缘属性匹配的下一个属性。如果属性匹配可以通过gremlin查询
-
如何在Gremlin查询中检索从根顶点开始的所有顶点属性? 我们有以下结构: 根顶点:Employee 边缘:EdCompany,EdDepartment,EdRole顶点:公司,部门,角色 我们试图接收与根顶点连接的其他顶点的数据。有人这样想: 我们尝试了该查询,但返回了一个复杂的JSON: 编辑: 我们还尝试了Kelvin建议的查询: 堆栈跟踪:提交查询失败:g.V().hasLabel(“E
-
问题内容: 有没有办法从mySQL的子查询中指定父查询字段? 例如: 我已经用PHP编写了一个基本的公告板类型程序。 在数据库中,每个帖子都包含:id(PK)和parent_id(父帖子的ID)。如果帖子本身是父项,则其parent_id设置为0。 我正在尝试编写一个mySQL查询,该查询将查找每个父级帖子以及父级拥有的子级数。 棘手的是,第一个 ID 不知道它应该引用子查询之外的第二个 ID 。
-
我有一个有向图,有大约1000个顶点和3000条边,其中包含圈。 我试图从给定顶点找到所有下游(外)路径。 使用以下Gremlin查询时 对于某些路径,由于周期的原因,需要花费很长时间才能得到结果,尽管simplePath步骤应该可以防止这种情况发生。 我尝试优化查询,并使用“聚合”步骤和“不使用”步骤两次遍历同一顶点,但现在跳过了一些顶点。 谢谢