
使用utf-8编码的utf-8读取文件不起作用,但使用“windows-1252”或“iso-8859-1”读取相同的文件起作用

这里发生了什么?为什么当我使用utf-8读取文件时,它会在控制台中输出问号?
这是一个最小的工作示例:
import java.io.File;
import java.io.IOException;
import java.nio.charset.Charset;
import static org.apache.commons.io.FileUtils.readFileToString;
import static org.apache.commons.io.FileUtils.writeStringToFile;
public class Main {
public static void main(String... args) throws IOException {
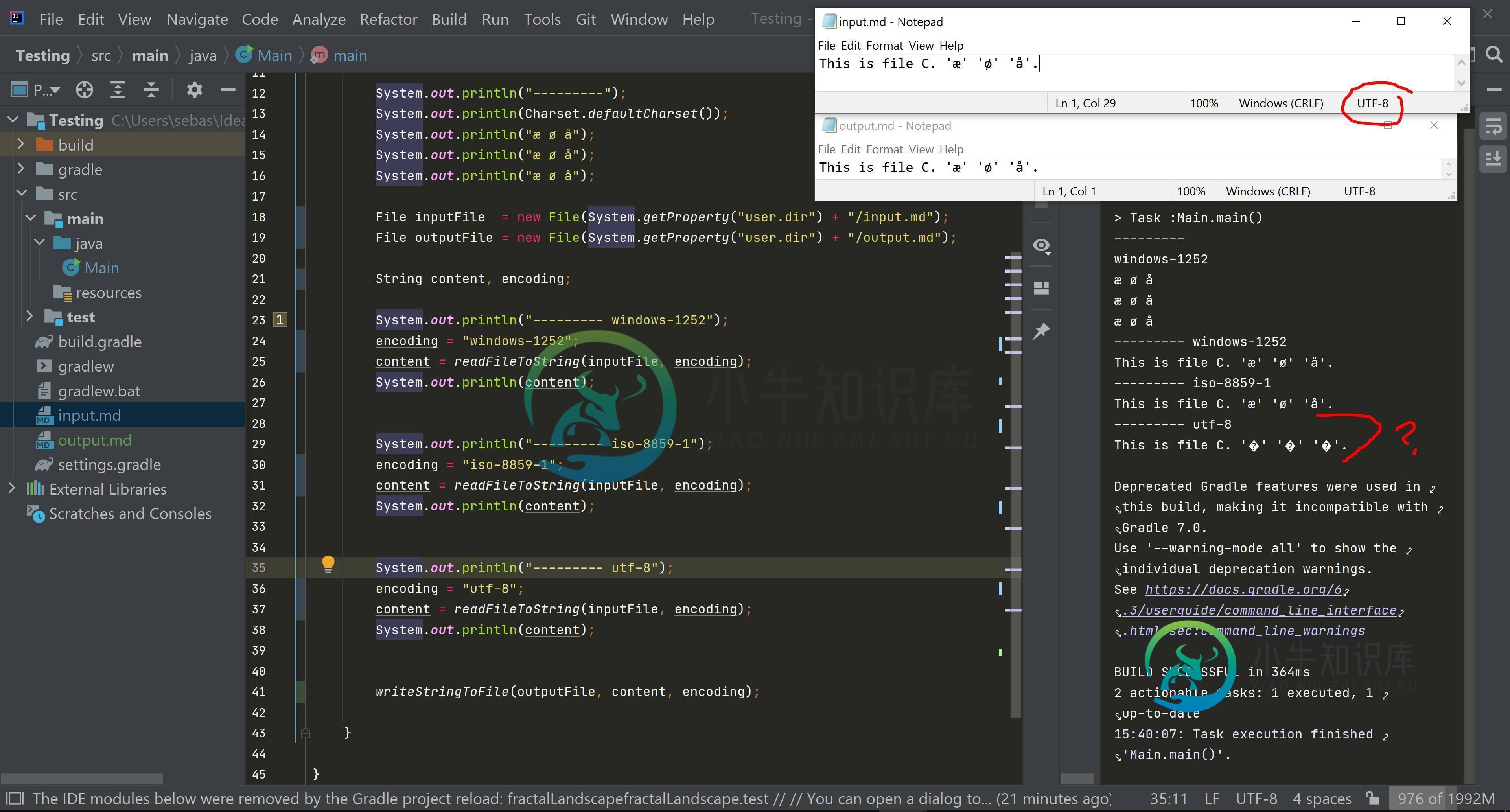
System.out.println("---------");
System.out.println(Charset.defaultCharset());
System.out.println("æ ø å");
System.out.println("æ ø å");
System.out.println("æ ø å");
File inputFile = new File(System.getProperty("user.dir") + "/input.md");
File outputFile = new File(System.getProperty("user.dir") + "/output.md");
String content, encoding;
System.out.println("--------- windows-1252");
encoding = "windows-1252";
content = readFileToString(inputFile, encoding);
System.out.println(content);
System.out.println("--------- iso-8859-1");
encoding = "iso-8859-1";
content = readFileToString(inputFile, encoding);
System.out.println(content);
System.out.println("--------- utf-8");
encoding = "utf-8";
content = readFileToString(inputFile, encoding);
System.out.println(content);
writeStringToFile(outputFile, content, encoding);
}
}
其中<代码>输入。md包含:(UTF-8编码)
This is input.md. 'æ' 'ø' 'å'
运行上述代码会产生
---------
windows-1252
æ ø å
æ ø å
æ ø å
--------- windows-1252
This is file C. 'æ' 'ø' 'å'.
--------- iso-8859-1
This is file C. 'æ' 'ø' 'å'.
--------- utf-8
This is file C. '�' '�' '�'.
为什么我得到<代码>� 当我使用UTF-8读取文件时?这尤其奇怪,因为文件是用UTF-8编码的。
更新:我的控制台设置为“UTF-8”:
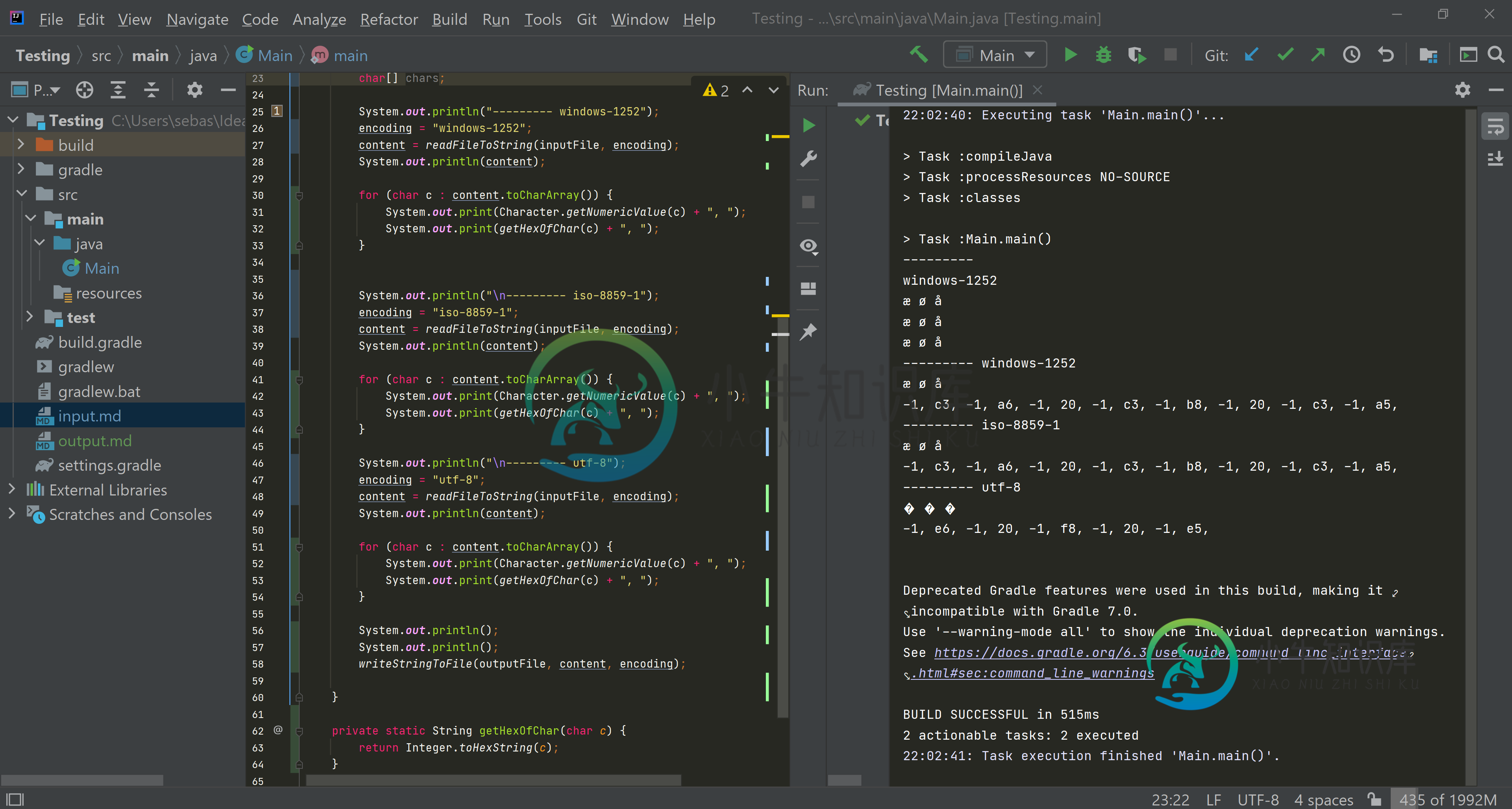
以下是从输入文件中提取的字符串中每个字符的十六进制值的屏幕截图:
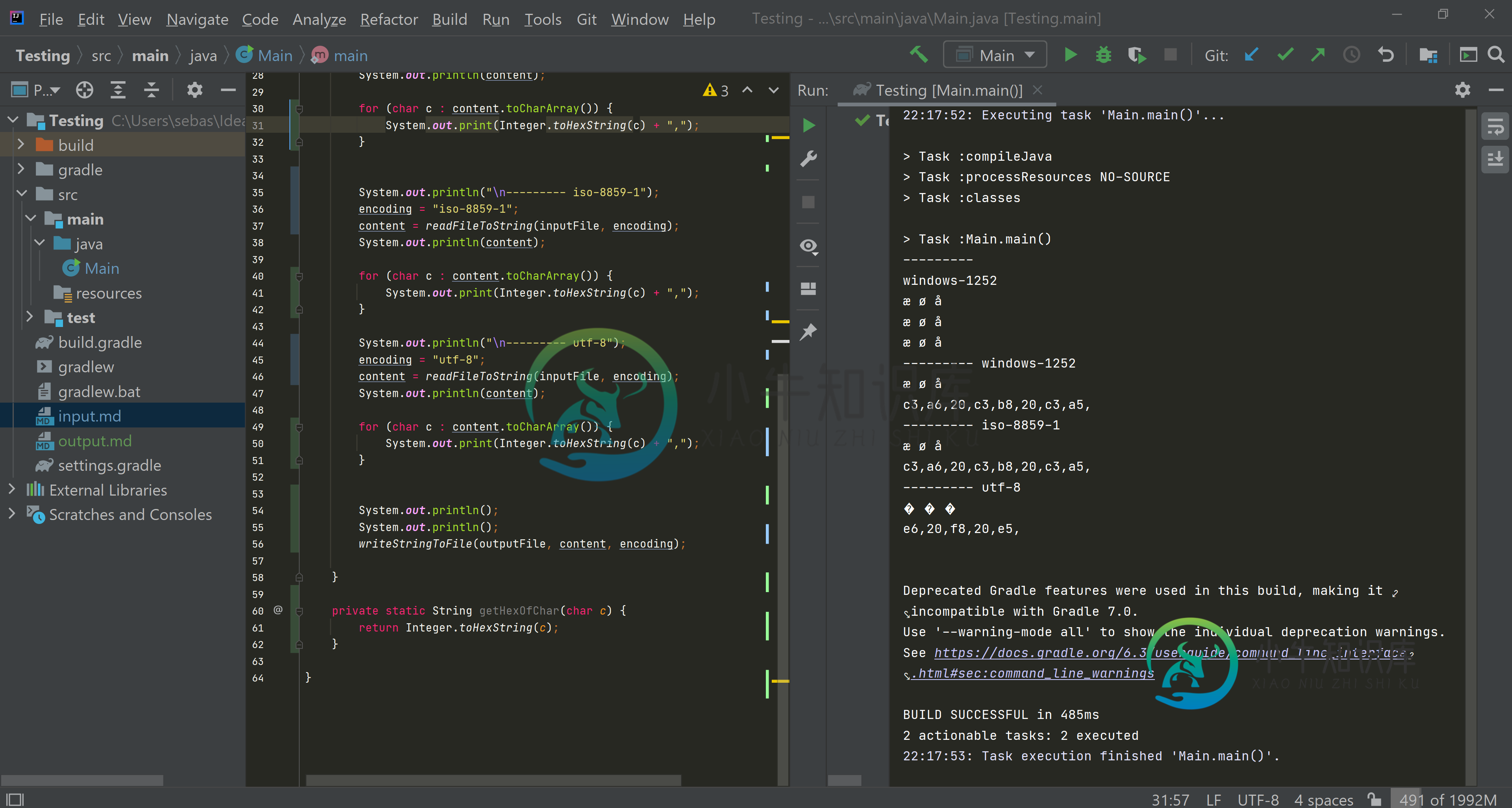
以下是十六进制隔离的更好截图:
共有2个答案

对于有类似问题的人来说,问题在于控制台的编码(正如@Remy Lebeau也指出的那样)。
我按照这个答案解决了这个问题
事实上,我在评论中关注了@Nicolas的回答,以获得提到的答案:
这也可以从“帮助”中访问
现在我得到了预期的输出:

代码在我看来很好,您的输出也很好。md文件看起来没问题。所以这很可能只是控制台输出的问题。
您正在试验的Unicode字符在Windows-1252和ISO-8859-1中编码为相同的单字节(æ=0xE6、ø=0xF8、å=0xE5),但在UTF-8中编码为多字节(æ=0xC3 0xA6、248=0xC3 0xB8、å=0xC3 0xA5)。
以Windows-1252或ISO-8859-1格式读取UTF-8编码文件将分别对每个字节进行解码,生成一个字符串,每个字节包含一个单独的字符,这些字符将与字节具有相同的数值。因此,您应该以包含字符的字符串结束,这些字符包括0x00C3 0x00A6、0x00C3 0x00B8和0x00C3 0x00A5。将这些字符作为Windows-1252输出到控制台应该显示为øå,而不是æå
另一方面,将UTF-8编码的文件读取为UTF-8将正确解码该文件,生成带有字符的字符串,即0x00E6、0x00F8和0x00E5。将字符串写入UTF-8编码文件应该会产生正确的字节序列(0xC3 0xA6、0xC3 0xB8和0xC3 0xA5),但输出与Windows-1252相同的字符串有数据丢失的风险,但您应该看到,正如预期的那样,因为Windows-1252确实支持这些Unicode字符。
所以,你的结果实际上与我的预期相反。即使是字符集。defaultCharset()正在报告Windows-1252,我怀疑您的控制台实际上使用了不同的字符集进行输出。
我建议您打印出内容字符串的单个字符的数值,以准确了解输入方式。md实际上是通过每个编码进行解码的。您应该得到我上面提到的char值。
-
正常的ASCII是正确的,但韩语字符不是。 所以我做了一个简单的程序来读取一个UTF-8文本文件并打印内容。 输出表示,字符在字符串、文字和文件中的编码是不同的。
-
问题内容: 我尝试进行后期呼叫并使用此值传递输入-“ä€爱لآहที่”,我收到了错误消息 这是我的代码 它在conn.getInputStream()上失败了; 内容的价值是 在输入为字符串或整数的情况下工作 当我添加语句 我收到了不同的消息 问题答案: 请尝试以下代码: 您应该使用JSONObject传递参数 输入,请尝试 如果输出是:???????,那么不用担心,因为您的输出控制台不支持UT
-
我有一个Android应用程序,它读取带有SQL脚本的文件,将数据插入SQLite数据库。然而,我需要知道这个文件的详细编码,我有一个从SQLite读取信息的EditText,如果编码不正确,它将显示为无效字符,如“?”而不是像“ç,í,ã”这样的字符。 我有以下代码: 这适用于“ISO-8859-1”编码,如果我将“UTF-8”设置为字符集,则适用于UTF-8。我需要以编程方式检测字符集编码(U
-
我有字节数组,它放在InputStreamReader中,用它做一些操作。 JVM有默认的cp1252编码,但是我转换成字节数组的文件有utf-8编码。此外,这个文件有德语umlauts。当我把字节数组放在InputStreamReader中时,java会将元音解码为错误的符号。例如,ürepression为。我试着把“utf-8”和charset.forname(“utf-8”).newdeco
-
问题内容: 我在理解将文本写入文件和将文件写入文件时遇到了大脑故障(Python 2.4)。 因此,我在文件f2 中输入我最喜欢的编辑器。 然后: 我在这里不明白什么?显然,我缺少一些至关重要的魔术(或理性)。一种类型的文本文件可以正确转换? 在这里,我真正无法理解的是UTF-8表示法的意义所在,如果你实际上无法让Python识别它的话(如果它来自外部)。也许我应该只将JSON转储字符串,然后使用
-
本章是由 Alex Cabal 最初撰写在 PHP Best Practices 中的,我们使用它作为进行建议的基础。 这不是在开玩笑。请小心、仔细并且前后一致地处理它。 目前,PHP 仍未在底层实现对 Unicode 的支持。虽然有很多途径可以确保 UTF-8 字符串能够被正确地处理,但这并不是很简单的事情,通常需要对 Web 应用进行全方面的检查,从 HTML 到 SQL 再到 PHP。我们将