
R:通过使用形状文件和光栅中的变量进行计算,创建新的光栅/形状文件

我目前正在尝试根据条件计算创建一个新的光栅或形状文件,需要根据光栅文件中的值对形状值中的每个值进行计算。我通常不使用光栅和形状文件,所以我对这里的元素很不熟悉。我是笼统地问这个问题,但以下是我使用的数据,希望它能让我更好地理解我试图实现的目标:
rast_norm <- ftp://prism.nacse.org/normals_4km/tmean/PRISM_tmean_30yr_normal_4kmM2_04_bil.zip
shp_probs <- ftp://ftp.cpc.ncep.noaa.gov/GIS/us_tempprcpfcst/seastemp_201603.zip
主要目标是取与shp_probs中的每个点(纬度和经度)相关的概率,并将其乘以对应于rast_norm中相同纬度和经度的值,以及之后的一些其他计算。如果我有两个data.tables,我可以做如下操作:
dt1 <- data.table(col1 = c(0:3), col2 = c(1:4)*11, factor1 = sqrt(c(285:288))
# # Output # #
# col1 col2 factor1
# 0 11 16.88194
# 1 22 16.91153
# 2 33 16.94107
# 3 44 16.97056
dt2 <- data.table(col1 = c(0:3), col2 = c(1:4)*11, factor2 = abs(sin(c(1:4))))
# # Output # #
# col1 col2 factor1
# 0 11 0.8414710
# 1 22 0.9092974
# 2 33 0.1411200
# 3 44 0.7568025
dt3 <- merge(dt1, dt2, by = c("col1", "col2"))
dt3$factor1 <- dt3$factor1 * dt3$factor2
dt3$factor2 <- NULL
# # Output # #
# col1 col2 factor1
# 0 11 14.205665
# 1 22 15.377615
# 2 33 2.390725
# 3 44 12.843364
使用数据表很容易。但是我不知道如何使用光栅和空间多边形数据帧来做到这一点。到目前为止,我需要阅读和清理文件:
# Importing the "rast_norm" file, the first listed above with a link
rast_norm <- "/my/file/path/PRISM_tmean_30yr_normal_4kmM2_04_bil.zip"
zipdirec <- "/my/zip/directory"
unzip(rast_norm, exdir = zipdirec)
# Get the correct file from the file list
rast_norm <- list.files(zipdirec, full.names = TRUE, pattern = ".bil")
rast_norm <- rast_norm[!grepl("\\.xml", rast_norm)]
# Convert to raster
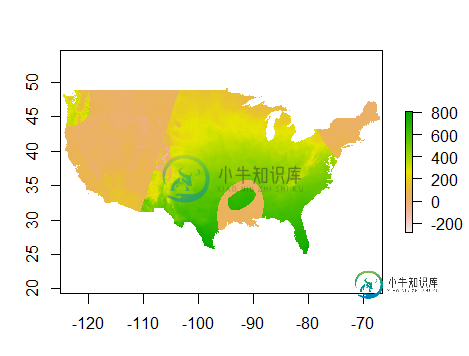
rast_norm <- raster(rast_norm)
单独绘制rast_norm可以得到这张地图。
# Importing the "shp_probs" file, the second listed above with a link
shp_probs <- "/my/file/path/seastemp_201603.zip"
zipdirec <- "/my/zip/directory"
unzip(shp_probs, exdir = zipdirec, overwrite = TRUE)
# Get the correct file from the list of file names and find the layer name
layer_name <- list.files(zipdirec, pattern = "lead14")
layer_name <- layer_name[grepl(".shp", layer_name)]
layer_name <- layer_name[!grepl("\\.xml", layer_name)]
layer_name <- do.call("rbind", strsplit(layer_name, "\\.shp"))[,1]
layer_name <- unique(layer_name)
# Use the layer name to read in the shape file
shp_probs <- readOGR(shp_probs, layer = layer_name)
names_levels <- paste0(shp_probs$Cat, shp_probs$Prob)
names_levels <- gsub("Below", "-", names_levels)
names_levels <- gsub("Above", "+", names_levels)
names_levels <- as.integer(names_levels)
shp_probs@data$id <- names_levels
shp_probs <- as(shp_probs, "SpatialPolygons")
# Create a data frame of values to use in conjunction with the existing id's
weights <- data.table(id = shp_probs$id, weight = shp_probs$id)
weights$weight <- c(.80, .80, .10, .10, .10, .10, .10, .10, .80, .10, .10, .10, .10, .10)
shp_probs <- SpatialPolygonsDataFrame(otlk_sp, weights, match.ID = FALSE)
单独绘制shp_probs可以得到这张地图。
现在我想取与shp_probs文件相关的概率,乘以与rast_norm文件相关的降雨量,再乘以与shp_probs文件中概率相关的权重。
我真的不知道该怎么办,任何帮助都将不胜感激。如何提取所有对应的数据点以匹配纬度和经度?我想如果我知道了,我会知道该怎么办。
谢谢你,提前。
共有1个答案

假设您想对光栅的每个网格单元执行此计算,您可以执行以下操作:
>
下载/读取数据,并添加weight列。请注意,这里我刚刚使用了随机权重,因为您的示例似乎为7个多边形指定了14个权重。另外,我不确定你的id专栏有什么用途,所以我跳过了这一部分。
library(raster)
library(rgdal)
download.file('ftp://prism.nacse.org/normals_4km/tmean/PRISM_tmean_30yr_normal_4kmM2_04_bil.zip',
fr <- tempfile(), mode='wb')
download.file('ftp://ftp.cpc.ncep.noaa.gov/GIS/us_tempprcpfcst/seastemp_201603.zip',
fs <- tempfile(), mode='wb')
unzip(fr, exdir=tempdir())
unzip(fs, exdir=tempdir())
r <- raster(file.path(tempdir(), 'PRISM_tmean_30yr_normal_4kmM2_04_bil.bil'))
s <- readOGR(tempdir(), 'lead14_Apr_temp')
s$weight <- runif(length(s))
执行栅格单元格和多边形坐标的空间叠加。(或者,您可以使用栅格::栅格化两次,将Prob和id字段转换为栅格,然后将三个栅格相乘。)
xy <- SpatialPoints(coordinates(r), proj4string=crs(r))
o <- over(xy, s)
创建与原始光栅具有相同范围/尺寸的新光栅,并为其单元格指定适当的值。
r2 <- raster(r)
r2[] <- r[] * o$Prob * o$weight
根据这些随机数据,结果如下所示:
-
在R中,与包“光栅”中的“提取”相比,在包“空间生态”的函数“zonal.stats”中计算平均值存在偏差。对于两者,我都使用多边形作为区域字段,并使用光栅作为值。 这是一个例子: z2和z1偏差的原因是什么?
-
下面的代码在我的图像上生成两个框。我正计划进一步分析这些框内的像素。 在下面的例子中,在红色方块的情况下,我不想继续下去,因为它的右上角有黑色像素。而我想继续在绿色方块的情况下,因为它没有一个黑色像素沿着它的边缘。
-
我已经为此挣扎了几个小时。我有一个包含177个多边形(即177个县)的shapefile(称为“shp”)。这个shapefile覆盖在光栅上。我的光栅(称为“ras”)由具有不同污染值的像素组成。 现在我想提取每个多边形的所有像素值及其出现次数。 这正是QGIS功能“分区直方图”所做的。但我想在R中做同样的事情。 我尝试了提取()函数,并设法获得了每个县的平均值,这已经是第一步,但我想制作像素分
-
我想将光栅数据聚合到自定义形状文件中的每个多边形。 在这种情况下,我想获得撒哈拉以南非洲次国家区域城市化的平均程度。 我的sf如下所示: 或绘制: 另一方面,光栅数据采用以下形式: 这些比整个星球所需的要细得多。为了加速计算,我首先聚合光栅,然后将其转换为shapefile,剩余的每个光栅像素都转换为shapefile中的点几何形状。然后,这个shapefile可以聚合到我的区域边界。诚然,这不是
-
我正在尝试在R中设置一个randomForest,以便根据其他光栅图像对光栅图像进行分类。我的训练数据是一个完全填充的光栅图像,我想训练许多其他光栅,以尝试基于初始光栅创建光栅输出。代码示例如下: <代码>rf1 ...其中,是我的光栅格式的实际已知值,而到是我想用来预测trainingRaster1是什么的其他光栅图像。我知道您将使用向量或点的训练类来训练一系列光栅,但在我的情况下,我希望使用光
-
我目前正在将原始矩阵转换为光栅以使用焦距函数,然后我想将光栅转换回矩阵。但是,当我尝试将光栅函数用作时,出现了一条错误消息。矩阵()。即使有这个非常简单的例子: 以下是我得到的: 如果(!is.null(names(x)))列表(names(x),,则数组(x,c(length(x),1L)中出错: “dimnames”[1]的长度不等于数组范围 我正在使用RstuIO、R版本3.4.0和、和库。