
Azure cosmos db没有分区键更快

我对cosmos DB的分区密钥感到困惑。我有一个数据库/容器,大约有4000条小记录。如果我使用分区键筛选器尝试sql语句,则RUs和持续时间会比不使用时长更大。
有人明白这一点吗?
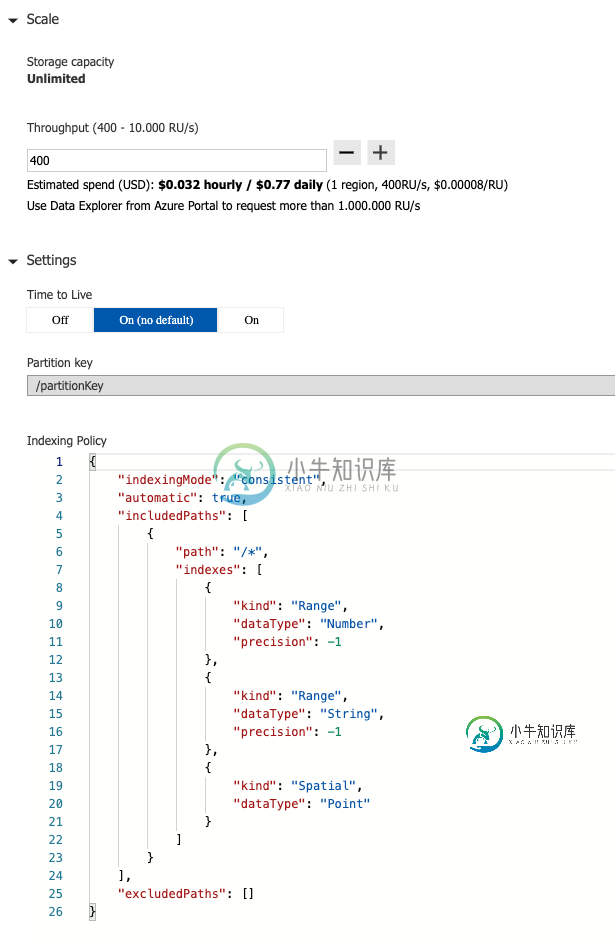
在此示例中,容器的分区键是/partitionkey
共有1个答案

这个问题与集合的拓扑非常具体(Azure支持可以帮助解决这个问题),但一般来说,在两种情况下,在RUs中,对非分区键属性的后一个查询可能低于分区键属性:
列表项目
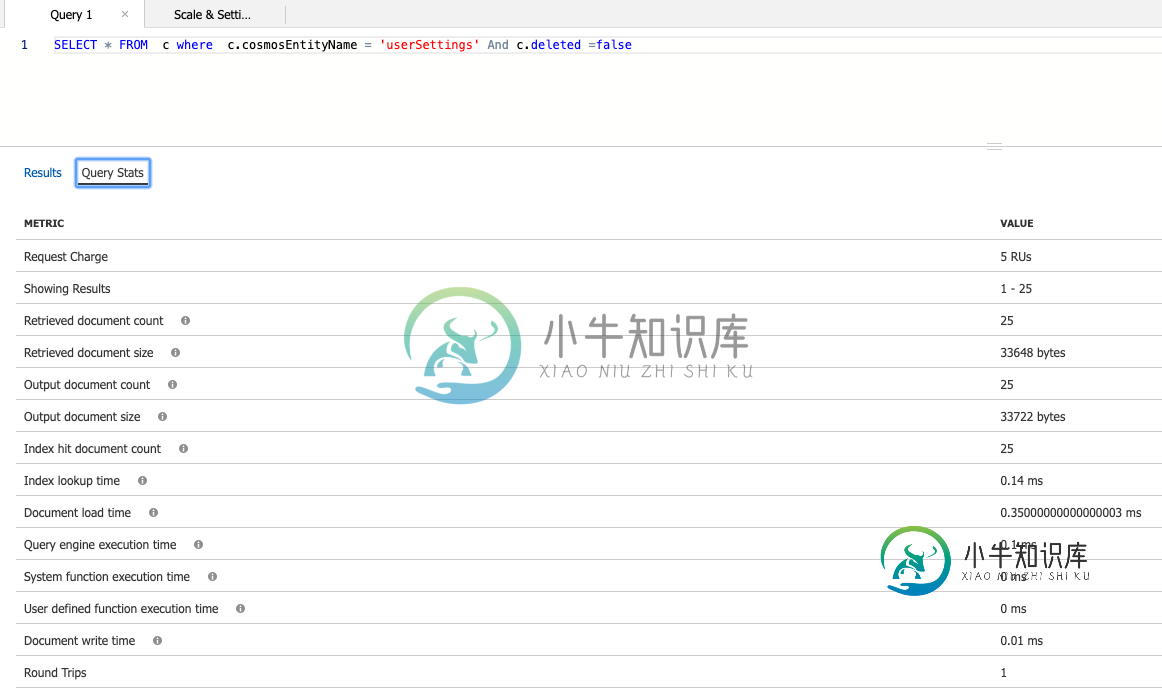
- 如果对非分区键属性的查询不完整,则RUs可能显示较低,但仍需要从其他分区读取结果,以确定没有更多的结果。您必须单击Data Explorer中的“更多结果”,直到它变为灰色
- 对于这个特定的查询
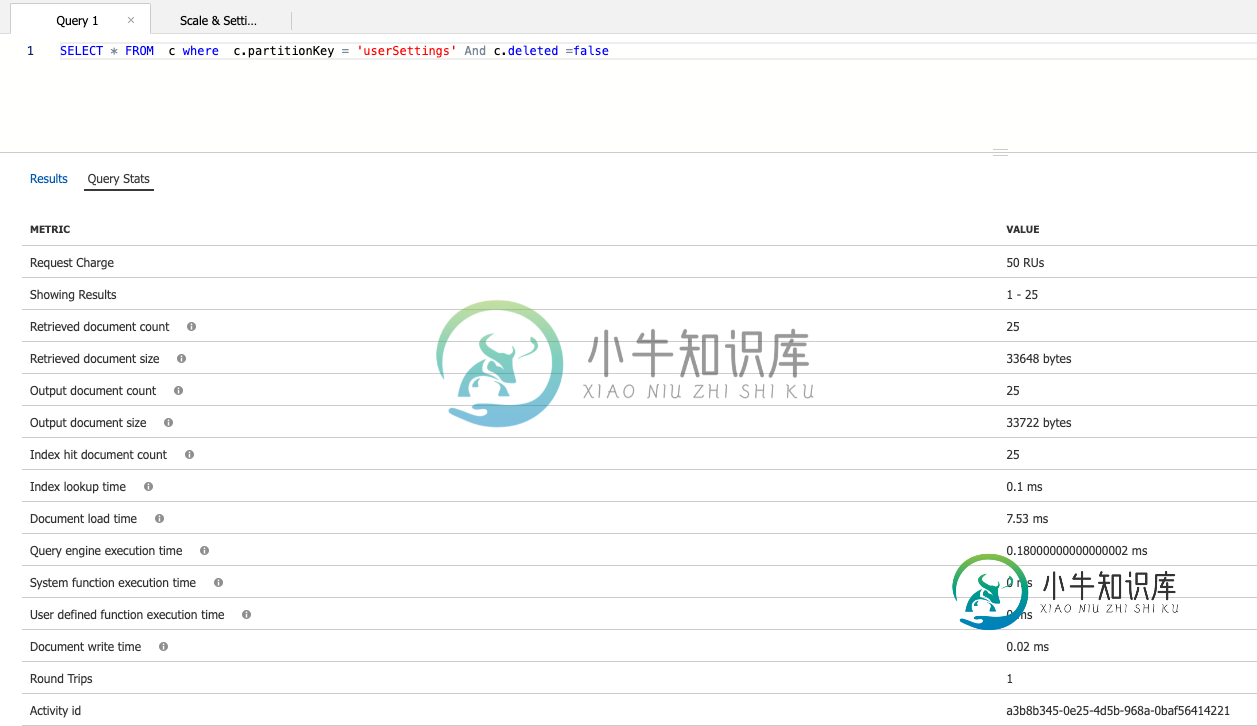
,其中c.partitionkey='user settings'和c.delete=false,您应该在/partitionkey/?和/delete/?(https://docs.microsoft.com/azure/cosmos-db/how-to-manage-indexing-policy#composite-indexing-policy-examples)上比较RUs是否有复合索引。在某些情况下,与默认值/*相比,使用复合索引会得到更低的RUs,后者只对它们单独进行索引,可能接近~5个RUs
-
我试图在kafka streams(kafka 1.0.1)和spring cloud stream(2.0.0-build-snapshot)的帮助下实现一个简单的事件源服务。我的StreamListener方法只是读取与聚合状态变化相对应的Kstream事件,并将它们应用到聚合上,并将最新的状态保存在本地状态存储(kafka提供的状态存储)中。域事件消息也具有与聚合的uuid(字符串)相同的键
-
我有这个问题:新的物理分区正在为我创建,请求经常发生在同一个分区上。我想知道这怎么可能,因为我没有指示热分区键? 我唯一的分区密钥是一个id,其组成如下: 用户id_年份_旅行号
-
我试图在Hazelcast 3.8.8中建立分区组。我的主要目标是将驻留在2台物理机器中的4个集群成员分为2个分区组。当我启用分区组时,它似乎不起作用,组也没有建立。您能告诉我启用分区组缺少什么吗? 我试图通过hazelcast启用分区分组。xml。使用group type=“CUSTOM”进行测试,并将驻留在my local和我们的服务器中的成员分为两个不同的成员组。成员组成了一个集群,但似乎没
-
与主键、复合键和候选键相比,dynamodb中的分区键和排序键是什么?
-
我在同一个消费者组上启动了两个消费者,我订阅了20个主题(每个主题只有一个分区) 仅在消费者上使用: kafka消费者组--引导服务器XXXXX:9092--组foo--描述--成员--详细 我做错了什么?
-
好的,我有一个带有主分区键(员工ID)和排序键(Poject ID)的表。现在我想要一个员工工作的所有项目的列表。我还想要一个项目上工作的所有员工的列表。这种关系是多对多的。我在AppSync(GraphQL)中创建了模式。Appsync为类型(员工项目)创建了所需的查询和突变。现在List员工项目采用具有不同属性的过滤器输入。我的问题是,当我只在员工ID或项目ID上进行两次搜索时,它会是一个完整