
Apache Storm远程拓扑提交

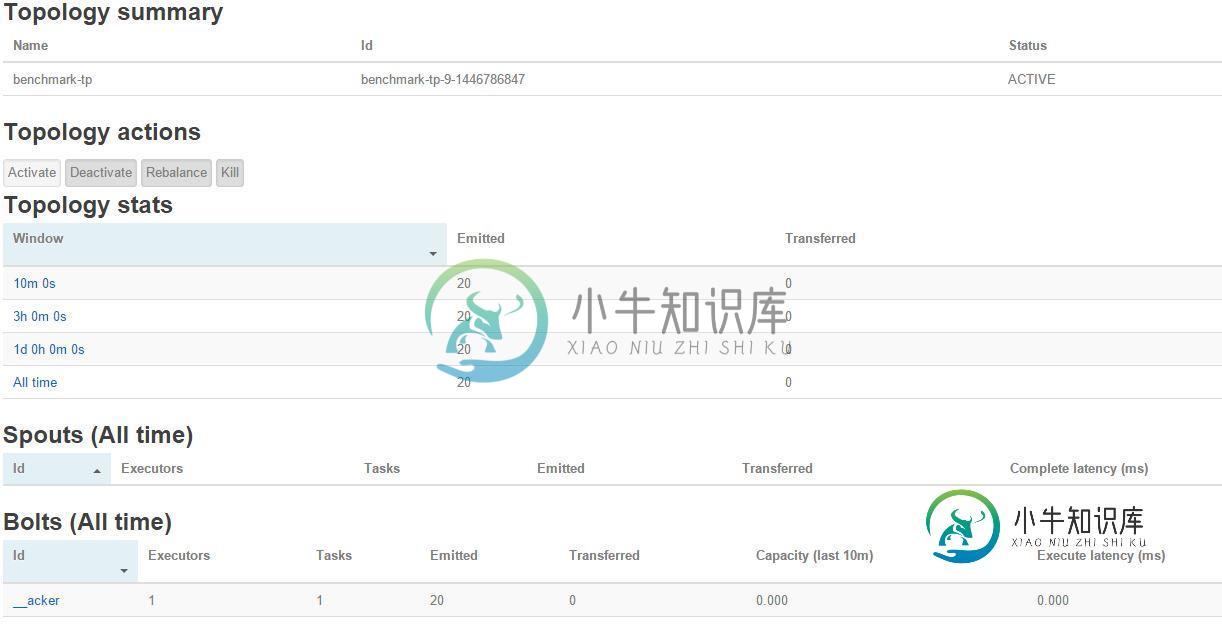
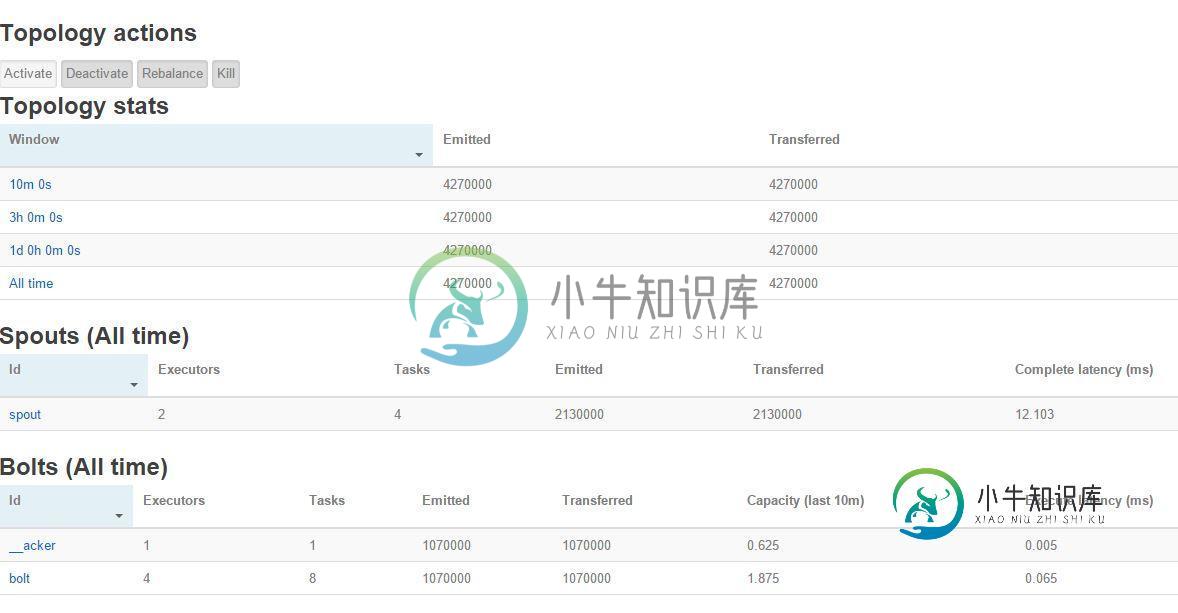
我一直在使用IDE(Eclipse)测试Storm拓扑的远程提交。我成功地将简单的storm拓扑上传到了远程storm集群,但奇怪的是,当我检查storm UI以确定远程提交的拓扑是否正常工作时,我在UI中看到了just_acker bolt,但其他bolt和spout却不在那里。之后,我从命令行手动提交了拓扑,并再次检查了Storm UI,它正常工作,没有问题。我一直在找原因,但没有找到。我在下面附上了拓扑和remote submitter类以及相应的Storm UI图片:
这是Eclipse控制台的输出(在远程提交之后)
225 [main] INFO backtype.storm.StormSubmitter - Uploading topology jar T:\STORM_TOPOLOGIES\Benchmark.jar to assigned location: /app/storm/nimbus/inbox/stormjar-d3ca2e14-c1d4-45e1-b21c-70f62c62cd84.jar
234 [main] INFO backtype.storm.StormSubmitter - Successfully uploaded topology jar to assigned location: /app/storm/nimbus/inbox/stormjar-d3ca2e14-c1d4-45e1-b21c-70f62c62cd84.jar
以下是拓扑:
public class StormBenchmark {
// ******************************************************************************************
public static class GenSpout extends BaseRichSpout {
//private static final Logger logger = Logger.getLogger(StormBenchmark.class.getName());
private Long count = 1L;
private Object msgID;
private static final long serialVersionUID = 1L;
private static final Character[] CHARS = new Character[] { 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'};
private static final String[] newsagencies = {"bbc", "cnn", "reuters", "aljazeera", "nytimes", "nbc news", "fox news", "interfax"};
SpoutOutputCollector _collector;
int _size;
Random _rand;
String _id;
String _val;
// Constructor
public GenSpout(int size) {
_size = size;
}
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
_rand = new Random();
_id = randString(5);
_val = randString2(_size);
}
//Business logic
public void nextTuple() {
count++;
msgID = count;
_collector.emit(new Values(_id, _val), msgID);
}
public void ack(Object msgID) {
this.msgID = msgID;
}
private String randString(int size) {
StringBuffer buf = new StringBuffer();
for(int i=0; i<size; i++) {
buf.append(CHARS[_rand.nextInt(CHARS.length)]);
}
return buf.toString();
}
private String randString2(int size) {
StringBuffer buf = new StringBuffer();
for(int i=0; i<size; i++) {
buf.append(newsagencies[_rand.nextInt(newsagencies.length)]);
}
return buf.toString();
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "item"));
}
}
// =======================================================================================================
// =================================== B O L T ===========================================================
public static class IdentityBolt extends BaseBasicBolt {
private static final long serialVersionUID = 1L;
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "item"));
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String character = tuple.getString(0);
String agency = tuple.getString(1);
List<String> box = new ArrayList<String>();
box.add(character);
box.add(agency);
try {
fileWriter(box);
} catch (IOException e) {
e.printStackTrace();
}
box.clear();
}
public void fileWriter(List<String> listjon) throws IOException {
String pathname = "/home/hduser/logOfStormTops/logs.txt";
File file = new File(pathname);
if (!file.exists()){
file.createNewFile();
}
BufferedWriter writer = new BufferedWriter(new FileWriter(file, true));
writer.write(listjon.get(0) + " : " + listjon.get(1));
writer.newLine();
writer.flush();
writer.close();
}
}
//storm jar storm-benchmark-0.0.1-SNAPSHOT-standalone.jar storm.benchmark.ThroughputTest demo 100 8 8 8 10000
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new GenSpout(8), 2).setNumTasks(4);
builder.setBolt("bolt", new IdentityBolt(), 4).setNumTasks(8)
.shuffleGrouping("spout");
Config conf = new Config();
conf.setMaxSpoutPending(200);
conf.setStatsSampleRate(0.0001);
//topology.executor.receive.buffer.size: 8192 #batched
//topology.executor.send.buffer.size: 8192 #individual messages
//topology.transfer.buffer.size: 1024 # batched
conf.put("topology.executor.send.buffer.size", 1024);
conf.put("topology.transfer.buffer.size", 8);
conf.put("topology.receiver.buffer.size", 8);
conf.put(Config.TOPOLOGY_WORKER_CHILDOPTS, "-Xdebug -Xrunjdwp:transport=dt_socket,address=1%ID%,server=y,suspend=n");
StormSubmitter.submitTopology("SampleTop", conf, builder.createTopology());
}
}
public class RemoteSubmissionTopo {
@SuppressWarnings({ "unchecked", "rawtypes", "unused" })
public static void main(String... args) {
Config conf = new Config();
TopologyBuilder topoBuilder = new TopologyBuilder();
conf.put(Config.NIMBUS_HOST, "117.16.142.49");
conf.setDebug(true);
Map stormConf = Utils.readStormConfig();
stormConf.put("nimbus.host", "117.16.142.49");
String jar_path = "T:\\STORM_TOPOLOGIES\\Benchmark.jar";
Client client = NimbusClient.getConfiguredClient(stormConf).getClient();
try {
NimbusClient nimbus = new NimbusClient(stormConf, "117.16.142.49", 6627);
String uploadedJarLocation = StormSubmitter.submitJar(stormConf, jar_path);
String jsonConf = JSONValue.toJSONString(stormConf);
nimbus.getClient().submitTopology("benchmark-tp", uploadedJarLocation, jsonConf, topoBuilder.createTopology());
} catch (TTransportException e) {
e.printStackTrace();
} catch (AlreadyAliveException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvalidTopologyException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
Thread.sleep(6000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
共有1个答案

在RemoteSubmissionTopo中,您使用TopologyBuilder topoBuilder=new TopologyBuilder();但不调用SetSpout(...)/SetBolt(...)。因此,您提交的是一个没有操作符的拓扑...
顺便提一下:RemoteSubMissionTopo实际上根本不是必需的。您可以使用StormBenchmark远程提交。只需在main中添加conf.put(config.nimbus_host,“117.16.142.49”);,并设置JVM选项-dstorm.jar=/path/to/topology.jar,您就可以运行了。
-
当我站在上面提交拓扑时,我在storm jar中遇到了问题 我写 打出来的 没有找到Storm指令 我想知道怎么了? Storm罐之间的区别是什么。。。。和 都在提交拓扑?
-
我正在运行一个3节点的Storm集群。我们正在提交一个包含10个工作者的拓扑结构,以下是拓扑结构的详细信息 我们每天处理800万到1000万个数据。问题是topolgy只运行了2到3天,而我们在kafka spout中看到了一些失败的元组,没有处理任何消息。当提交新的topolgy时,它工作良好,但在2到3天后,我们又看到了同样的问题。有人能给我们一个解决方案吗。下面是我的storm配置
-
为了表明计算机科学家可以把任何东西变成一个图问题,让我们考虑做一批煎饼的问题。 菜谱真的很简单:1个鸡蛋,1杯煎饼粉,1汤匙油 和 3/4 杯牛奶。 要制作煎饼,你必须加热炉子,将所有的成分混合在一起,勺子搅拌。 当开始冒泡,你把它们翻过来,直到他们底部变金黄色。 在你吃煎饼之前,你会想要加热一些糖浆。 Figure 27将该过程示为图。 Figure 27 制作煎饼的困难是知道先做什么。从 Fi
-
一、拓扑排序介绍 拓扑排序(Topological Order)是指,将一个有向无环图(Directed Acyclic Graph简称DAG)进行排序进而得到一个有序的线性序列。 这样说,可能理解起来比较抽象。下面通过简单的例子进行说明! 例如,一个项目包括A、B、C、D四个子部分来完成,并且A依赖于B和D,C依赖于D。现在要制定一个计划,写出A、B、C、D的执行顺序。这时,就可以利用到拓扑排序
-
我正在尝试使用Eclipse在Linux中运行Storm启动示例。我收到以下错误和函数从未被调用。 错误: 我的拓扑类: 我正在虚拟机环境中工作,所以不知道这是否是由于安装了Zookeeper。有什么想法吗?
-
8台机器一直在使用。每一个都有22个核心和512 GB的RAM。但是,我们的代码运行得真的很慢。传输600万个数据需要10分钟才能完成。 60个文件中的10 MB在一秒钟内传输到HDFS。我们正在努力优化我们的代码,但很明显我们做了一些非常错误的事情。 对于蜂巢表,我们有64个桶。 在HDFS喷口;.setmaxextending(50000); 在蜂巢喷口选项;.WithTxNsperBatch