
为什么Trident在这个最小示例中不调用ack()或fail()?

我试图在三叉戟中创建一个小例子。目标是查看在失败的情况下如何重播元组。下面是拓扑定义
Random rand = new Random();
Config config = new Config();
config.setDebug(true);
config.setNumWorkers(1);
TridentTopology topology = new TridentTopology();
topology.newStream("spout", new RandomIntegerSpout())
.map((MapFunction) tridentTuple -> {
if ((tridentTuple.getLongByField("msgid") % 50 == 0) &&
(rand.nextInt(2) == 1)) {
System.out.println(String.format("Failed to process tuple %d", tridentTuple.getLongByField("msgid")));
throw new ReportedFailedException("Divisible by 50");
}
return new Values(tridentTuple.toArray());
})
.peek((Consumer) tridentTuple -> System.out.println(tridentTuple.getValues()));
我使用了来自storm-starter的RandomIntegerSpout,它扩展了BaseRichSpout,并且只生成随机数。然后应用mapfunction,它只是每50个元组抽取一个随机数,并随机使该元组失败。
问题是,我没有得到任何acks或fails。
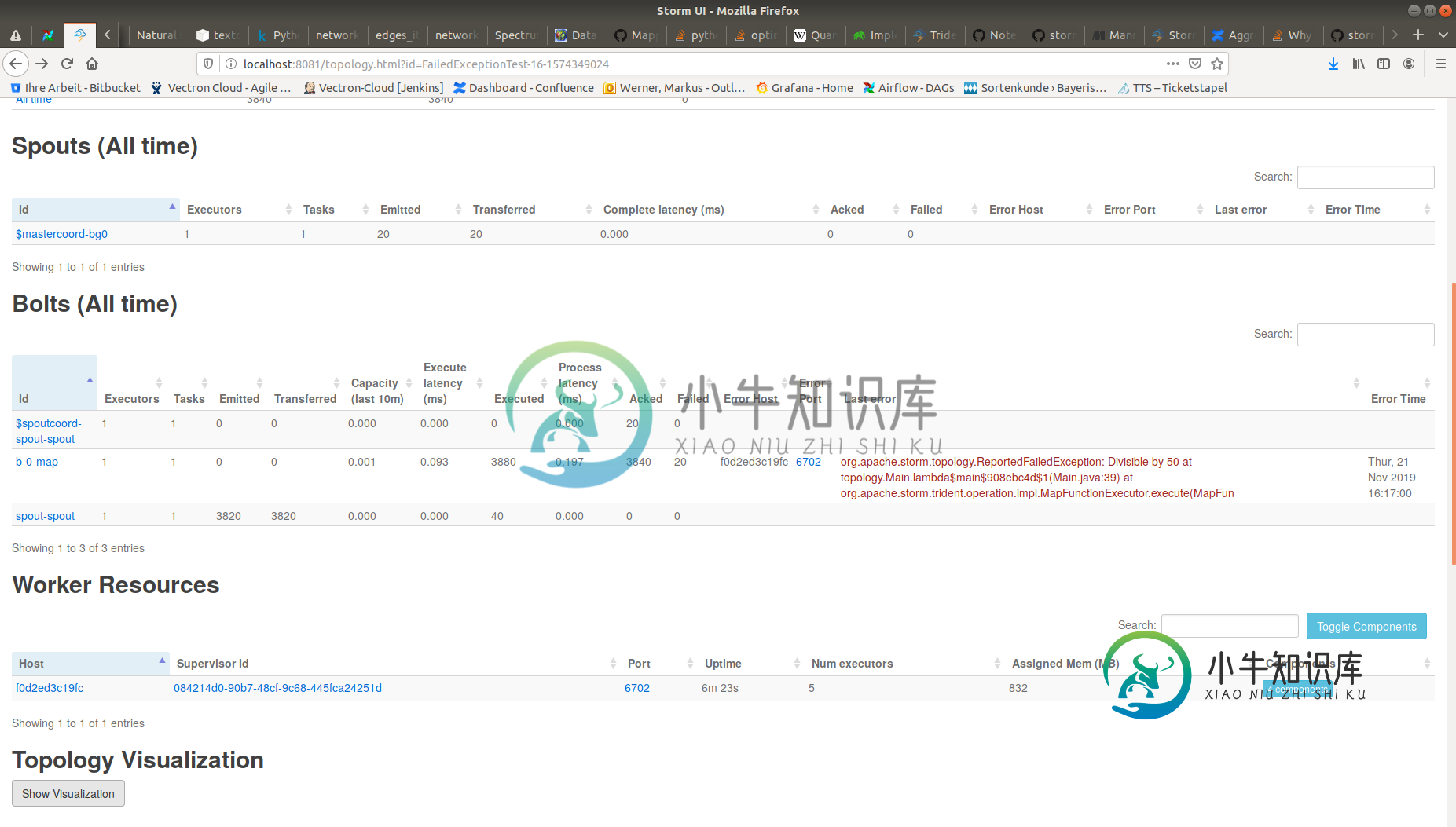
通过检查,看到代码几乎是微不足道的,我可能误解了关于Trident/Storm的一些基本内容。如果批处理完成,我期望trident调用spout的和ack方法是错误的吗?我意识到在ibatchspout中没有fail方法。Trident如何处理批次的重放??
共有1个答案

Trident spouts不会在单个元组级别上ack或失败元组。相反,元组被作为一个批处理来处理。
三叉戟喷口通常看起来像这样的接口。
M emitPartitionBatch(TransactionAttempt tx, TridentCollector collector, PartitionT partition, M lastPartitionMeta);
其思想是,Trident将管理对批处理元组的ACK/Failles的跟踪,然后如果批处理失败,它将请求spout重复该批处理,如果不重复,它就不重复。
我认为您在Storm UI中没有看到任何与此相关的内容的原因是irichbolt实际上并没有被表示出来。相反,它被包装了,因此ack/fail调用是在spout-spout组件的“引擎盖下”发生的。如果您想确定是否正在调用ACK/FAIL,请尝试向irichspout的ACK/FAIL方法添加一些日志记录。
-
问题内容: 在Python中,为类实例创建的字典与包含该类相同属性的字典相比很小: 使用Python 3.5.2时,以下调用产生: 节省了字节! 另一方面,使用Python 2.7.12,则返回相同的调用: 已保存字节。 在这两种情况下,字典显然具有 完全相同的内容 : 所以这不是一个因素。此外,这也仅适用于Python 3。 那么,这是怎么回事?为什么在Python 3中实例的大小如此之小? 问
-
在Hugo模板中,我知道您可以使用< code>function param调用函数: 但在文档中,我还看到您还可以: 我从未遇到过这种调用函数的方式(在Ruby/Python等语言中)。这是围棋特有的,还是雨果特有的?这种调用函数的方式是如何调用的?另外,如果你有不止一种类型的论点,你能做到吗?
-
问题内容: 我从python学到的内容无: 当我放入列表并用数字和字符串排序时。我得到以下结果,这意味着它是最小的数字? 逆转: 正常排序: python sorted function如何与None一起工作? 问题答案: 比较不同类型时,CPython 2应用了一些不同的规则: 首先排序。 数字先于其他类型,并且在数字之间进行比较。 其他类型按其类型 名称 排序,除非它们显式实现比较方法。 此外
-
这里,在类动物getObjectSize中,变量'name'返回0 在类Dog getObjectSize中,变量'Dog name'返回0 我想到的是内存中的dogName引用大小等于0,动物类中的name引用大小也等于0,那么为什么在创建一个新的Dog对象后,它的大小比动物对象的大小大呢? 当我从类dog中移除(字符串dogName)时,现在dog对象的大小等于动物对象的大小。
-
我得到两个错误: Java:不兼容类型:无法推断类型变量R(参数不匹配;方法引用无效) 对toString的引用是不明确的,java.lang.Integer中的方法toString(int)和java.lang.Integer中的方法toString()都是不明确的 并且编译器无法推断所需的方法引用。 但是关于第二个,编译器引用的静态上下文在哪里? 这个错误与Integer类的方法toStrin
-
我有一个密集更新的列表,所以我将它们分组在一起,并在单个线程中作为批处理作业执行它们。其他线程可以随时发送更新。 当调度要排队更新的作业时,我想要一个集合,如果作业已经存在,我可以在其中修改作业(假设itemId为键)。在这个例子中: 因此,队列不会开始为同一项提供数千个作业。当作业开始执行时,我需要以某种方式在队列中循环,但是在更新作业时,它不应该被更新(每个项目都应该有自己的锁吗?)。 更新作