
Storm Trident
-
理解Trident的数据模型 Trident 是 Strom的高级API TridentTuple interface是Trident能操作的批处理的最小单元 . 每个TridentTuple, 由一组预定义好名称(字段)和类型的值组成. 这些值可以是: byte, character, integer, long, float, double, Boolean 或 byte array. 在构造
-
一.trident 的介绍 trident 的英文意思是三叉戟,在这里我的理解是因为之前我们通过之前的学习topology spout bolt 去处理数据是没有问题的,但trident 的对spout bolt 更高层次的一个抽象,其实现功能是一样的,只不过是trident做了更多的优化和封装.如果对处理的性能要求比较高,建议要采用spout bolt 来处理,反之则可以用trident
-
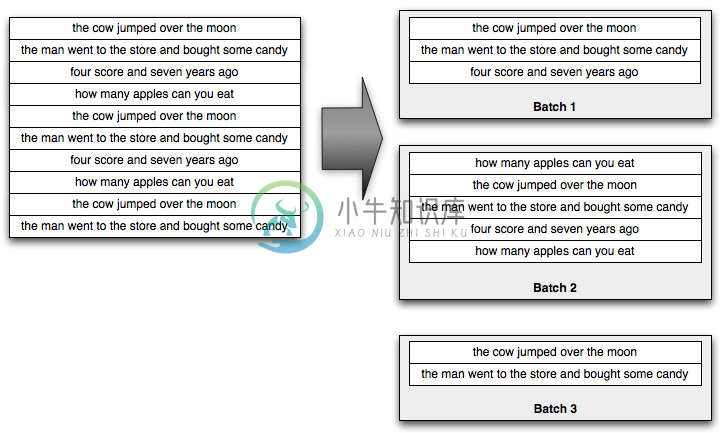
Trident topology. Trident 在storm上提供了高层抽象,抽象掉了事务处理和状态管理的细节. Trident topology trident 引入了"数据批次概念" batch每个batch会分配一个唯一的事务标识符,spout基于决定batch的组成方式,分为三种非事务性(non-transational),事务性(transational),非透明性(opaque).
-
如下代码使用global做repartition, 数据流中的所有tuple都被分配到同一个partition当中(partition id最小的那个), 省略部分代码,省略部分可参考:https://blog.csdn.net/nickta/article/details/79666918 FixedBatchSpout spout = new FixedBatchSpout(new Field
-
groupBy不包括任何的重新分区,它把输入流转换为按组的输入流,加入了groupBy,则后续的聚合aggregate,则是按照组进行。 1. groupBy可以放在partitionAggregate前面。此时partitionAggregate的作用是对分区内数据做分组聚合。 2. groupBy可以放在aggregate前面。此时同一批次中的所有tuple会分配到一个单独partition当
-
序 本文主要研究一下storm trident的operations function filter projection Function storm-core-1.2.2-sources.jar!/org/apache/storm/trident/operation/Function.java public interface Function extends EachOperation {