
NiFi非Avro JSON读取器/写入器

标准的ApacheNIFI读写器似乎只能解析基于Avro模式的JSON输入。
Avro模式对JSON有限制,例如它不允许以数字开头的有效JSON属性。
JoltTransformJSON处理器在这里可以有所帮助(它没有对输入JSON可能的样子施加Avro限制),但似乎这个处理器不支持批处理流文件。它也不是基于读者和作者(也许正因为如此)。
是否有方法读取任意有效的批处理JSON输入,例如多行格式
{"myprop":"myval","12345":"12345",...}
{"myprop":"myval2","12345":"67890",...}
并将其转换为其他JSON结构,例如,由JSON模式定义,例如,使用JSON补丁转换,而无需编写自己的处理器?
更新
我使用的是Apache NiFi 1.7.1
更新2
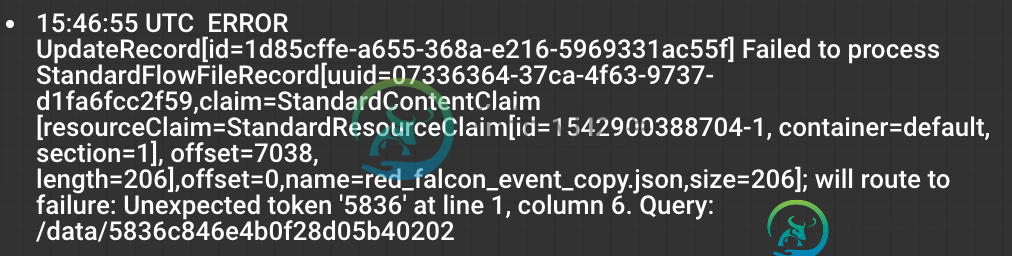
不幸的是,@Shu的建议起了作用。我也犯了同样的错误。将这种情况简化为单个UpdateRecord处理器,该处理器读取带有数字属性的JSON,并使用
myprop : /data/5836c846e4b0f28d05b40202
映射。仍然相同的错误:(
共有1个答案

它不允许以数字开头的有效JSON属性?
这个bug NiFi-4612在NiFi-1.5版本中修复了,我们可以使用AvroSchemaRegistry来定义您的模式并更改
验证字段名称
false
然后我们可以有以数字开头的avro模式字段名称。
有关更多详细信息,请参阅此链接。
有没有一种方法可以读取任意有效的批量JSON输入,比如多行形式?
在NiFi-1.7中修复了这个错误NiFi-4456,如果您没有使用这个版本的NiFi,那么我们可以使用以下方法创建一个带有< code >,(逗号分隔符)的json消息数组。
流量:
1.SplitText //split the flowfile with 1 line count
2.MergeRecord //merge the flowfiles into one
3.ConvertRecord
关于这个特殊问题的更多细节,请参考这个链接(我已经解释了流程)。
-
如何写这个问题?老实说,我不明白这个问题的意思。A) 编写读者和作者优先于读者的解决方案,并评论每个信号量的功能。(记住变量和信号量的定义和初始化)B)读卡器的优先级意味着什么?当一个作家在写作时,到达的读者会发生什么?当编写器结束其操作时会发生什么?
-
项目读取器将数据从特定源代码读入Spring批处理应用程序,而项目写入器将数据从Spring Batch应用程序写入特定目标。 Item处理器是一个包含处理代码的类,该代码处理读入spring批处理的数据。 如果应用程序读取条记录,则处理器中的代码将在每条记录上执行。 块(chunk)是该tasklet的子元素。 它用于执行读取,写入和处理操作。 可以在如下所示的步骤中配置使用此元素的读取器,写入
-
我想做一个新的处理器,它将是GetFile和EvaluateXpath的重聚。有几个主题我感兴趣: > 现在我的nar文件超过20KB,而我的nifi无法运行它,我该如何缩小它? 我想从文件夹中获取文件,读取它的数据并将其作为一个atribute放入新的flowfile中,然后将配置xml回滚到它的原始文件夹,如何将配置文件回滚到文件夹b代码? 下面是我用来从xml配置文件中获取属性的简单代码:
-
问题内容: 回答 根据接受的答案代码,对该代码进行以下调整对我有用: 编辑 我已将问题更新为可以正确循环的版本,但是随着应用程序的扩展,能够并行处理非常重要,而且我仍然不知道如何在运行时使用javaconfig动态地执行此操作… 改进的问题: 如何在运行时 针对5种不同情况 动态创建读取器-处理器-写入器 (5个查询意味着按现在配置的5个循环)? 我的LoopDecider看起来像这样: 基于查询
-
我有一个批处理步骤 读取器和处理器流程如何工作?读取器是读取块并等待处理器处理它,还是一次读取所有块。
-
CompositeItemWriter:当我需要将项目平均地分给Writer时,似乎会将所有读取的项目传递给所有的Writer。 BacktoBackPatternClassifier:我并不真正需要分类器,因为我是均匀地拆分项目。 有没有另一种方式,让一个读者和多个作者? 或者我可以在Writer中手动创建线程?