
连续生成cloudwatch日志的Lambda(与Kinesis数据流连接)函数

在我当前的项目中,我的目标是从帧流中检测不同的对象。视频帧是用与覆盆子PI连接的摄像机拍摄的。
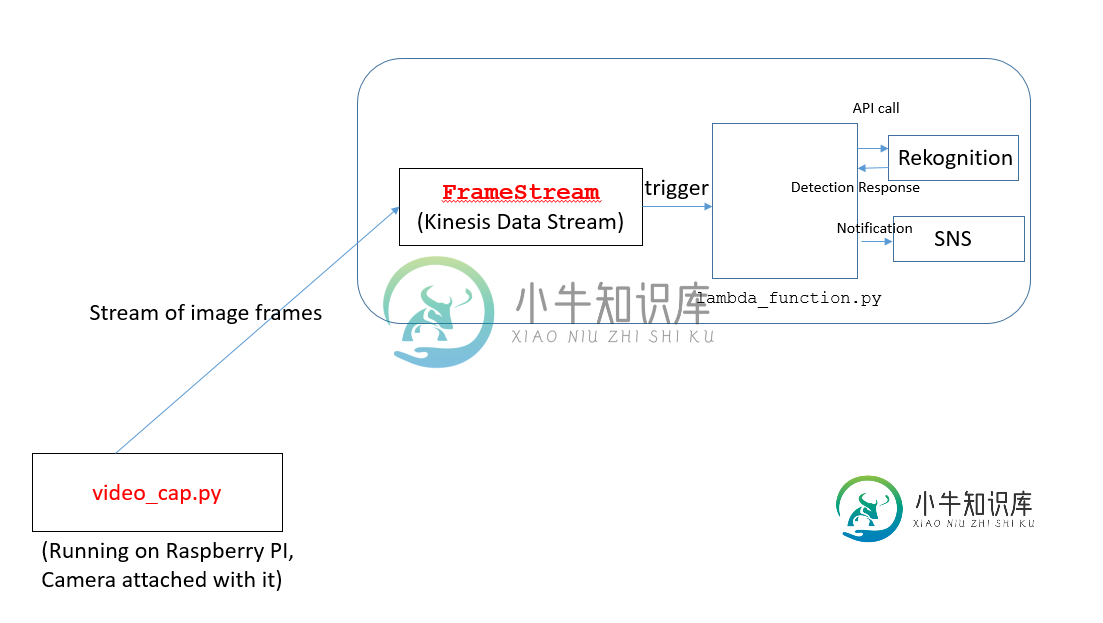
体系结构设计如下:
>
video_cap.py代码正在raspberry PI上运行。此代码将图像流发送到AWS中的Kinesis数据流(称为framestream)。
# Copyright 2017 Amazon.com, Inc. or its affiliates. All Rights Reserved.
# Licensed under the Amazon Software License (the "License"). You may not use this file except in compliance with the License. A copy of the License is located at
# http://aws.amazon.com/asl/
# or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, express or implied. See the License for the specific language governing permissions and limitations under the License.
import sys
import cPickle
import datetime
import cv2
import boto3
import time
import cPickle
from multiprocessing import Pool
import pytz
kinesis_client = boto3.client("kinesis")
rekog_client = boto3.client("rekognition")
camera_index = 0 # 0 is usually the built-in webcam
capture_rate = 30 # Frame capture rate.. every X frames. Positive integer.
rekog_max_labels = 123
rekog_min_conf = 50.0
#Send frame to Kinesis stream
def encode_and_send_frame(frame, frame_count, enable_kinesis=True, enable_rekog=False, write_file=False):
try:
#convert opencv Mat to jpg image
#print "----FRAME---"
retval, buff = cv2.imencode(".jpg", frame)
img_bytes = bytearray(buff)
utc_dt = pytz.utc.localize(datetime.datetime.now())
now_ts_utc = (utc_dt - datetime.datetime(1970, 1, 1, tzinfo=pytz.utc)).total_seconds()
frame_package = {
'ApproximateCaptureTime' : now_ts_utc,
'FrameCount' : frame_count,
'ImageBytes' : img_bytes
}
if write_file:
print("Writing file img_{}.jpg".format(frame_count))
target = open("img_{}.jpg".format(frame_count), 'w')
target.write(img_bytes)
target.close()
#put encoded image in kinesis stream
if enable_kinesis:
print "Sending image to Kinesis"
response = kinesis_client.put_record(
StreamName="FrameStream",
Data=cPickle.dumps(frame_package),
PartitionKey="partitionkey"
)
print response
if enable_rekog:
response = rekog_client.detect_labels(
Image={
'Bytes': img_bytes
},
MaxLabels=rekog_max_labels,
MinConfidence=rekog_min_conf
)
print response
except Exception as e:
print e
def main():
argv_len = len(sys.argv)
if argv_len > 1 and sys.argv[1].isdigit():
capture_rate = int(sys.argv[1])
cap = cv2.VideoCapture(0) #Use 0 for built-in camera. Use 1, 2, etc. for attached cameras.
pool = Pool(processes=3)
frame_count = 0
while True:
# Capture frame-by-frame
ret, frame = cap.read()
#cv2.resize(frame, (640, 360));
if ret is False:
break
if frame_count % capture_rate == 0:
result = pool.apply_async(encode_and_send_frame, (frame, frame_count, True, False, False,))
frame_count += 1
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
return
if __name__ == '__main__':
main()
Lambda函数(lambda_function.py)
from __future__ import print_function
import base64
import json
import logging
import _pickle as cPickle
#import time
from datetime import datetime
import decimal
import uuid
import boto3
from copy import deepcopy
logger = logging.getLogger()
logger.setLevel(logging.INFO)
rekog_client = boto3.client('rekognition')
# S3 Configuration
s3_client = boto3.client('s3')
s3_bucket = "bucket-name-XXXXXXXXXXXXX"
s3_key_frames_root = "frames/"
# SNS Configuration
sns_client = boto3.client('sns')
label_watch_sns_topic_arn = "SNS-ARN-XXXXXXXXXXXXXXXX"
#Iterate on rekognition labels. Enrich and prep them for storage in DynamoDB
labels_on_watch_list = []
labels_on_watch_list_set = []
text_list_set = []
# List for detected text
text_list = []
def process_image(event, context):
# Start of for Loop
for record in event['Records']:
frame_package_b64 = record['kinesis']['data']
frame_package = cPickle.loads(base64.b64decode(frame_package_b64))
img_bytes = frame_package["ImageBytes"]
approx_capture_ts = frame_package["ApproximateCaptureTime"]
frame_count = frame_package["FrameCount"]
now_ts = datetime.now()
frame_id = str(uuid.uuid4())
approx_capture_timestamp = decimal.Decimal(approx_capture_ts)
year = now_ts.strftime("%Y")
mon = now_ts.strftime("%m")
day = now_ts.strftime("%d")
hour = now_ts.strftime("%H")
#=== Object Detection from an Image =====
# AWS Rekognition - Label detection from an image
rekog_response = rekog_client.detect_labels(
Image={
'Bytes': img_bytes
},
MaxLabels=10,
MinConfidence= 90.0
)
logger.info("Rekognition Response" + str(rekog_response) )
for label in rekog_response['Labels']:
lbl = label['Name']
conf = label['Confidence']
labels_on_watch_list.append(deepcopy(lbl))
labels_on_watch_list_set = set(labels_on_watch_list)
#print(labels_on_watch_list)
logger.info("Labels on watch list ==>" + str(labels_on_watch_list_set) )
# Vehicle Detection
#if (lbl.upper() in (label.upper() for label in ["Transportation", "Vehicle", "Van" , "Ambulance" , "Bus"]) and conf >= 50.00):
#labels_on_watch_list.append(deepcopy(label))
#=== Detecting text from a detected Object
# Detect text from the detected vehicle using detect_text()
response=rekog_client.detect_text( Image={ 'Bytes': img_bytes })
textDetections=response['TextDetections']
for text in textDetections:
text_list.append(text['DetectedText'])
text_list_set = set(text_list)
logger.info("Text Detected ==>" + str(text_list_set))
# End of for Loop
# SNS Notification
if len(labels_on_watch_list_set) > 0 :
logger.info("I am in SNS Now......")
notification_txt = 'On {} Vehicle was spotted with {}% confidence'.format(now_ts.strftime('%x, %-I:%M %p %Z'), round(label['Confidence'], 2))
resp = sns_client.publish(TopicArn=label_watch_sns_topic_arn,
Message=json.dumps(
{
"message": notification_txt + " Detected Object Categories " + str(labels_on_watch_list_set) + " " + " Detect text on the Object " + " " + str(text_list_set)
}
))
#Store frame image in S3
s3_key = (s3_key_frames_root + '{}/{}/{}/{}/{}.jpg').format(year, mon, day, hour, frame_id)
s3_client.put_object(
Bucket=s3_bucket,
Key=s3_key,
Body=img_bytes
)
print ("Successfully processed records.")
return {
'statusCode': 200,
'body': json.dumps('Successfully processed records.')
}
def lambda_handler(event, context):
logger.info("Received event from Kinesis ......" )
logger.info("Received event ===>" + str(event))
return process_image(event, context)


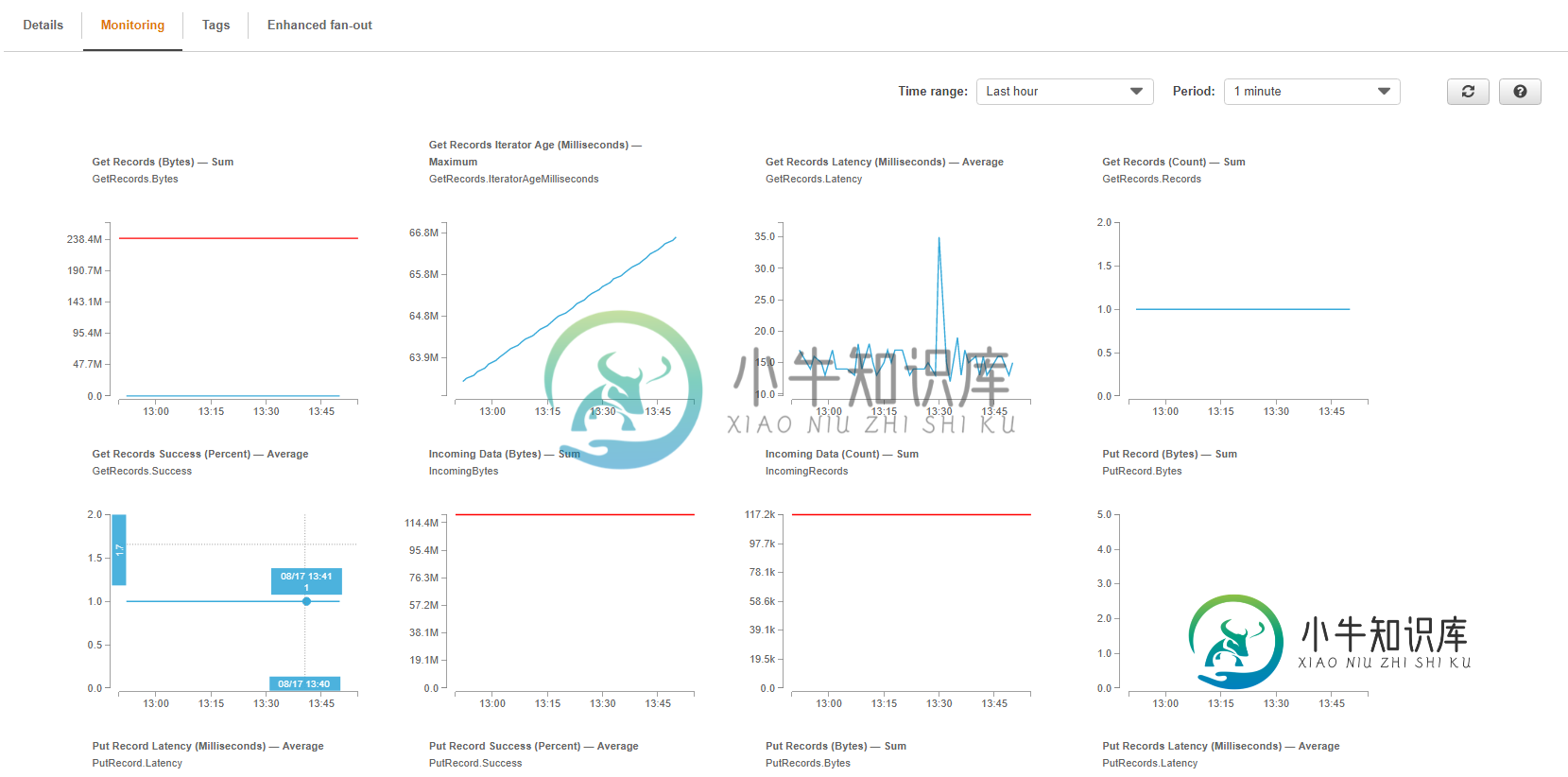
以下是Kinesis数据流日志(日期为2019年8月17日-IST下午1:54)。最后一次,2019年8月16日通过覆盆子PI摄取的数据-下午6:45)

共有1个答案

看起来流中大约有117K条记录,但每次处理1条记录的速度很慢。lambda处理一条记录需要多长时间?我会得到lambda运行的时间,将python put代码更新为lambda运行的Hibernate时间长一点(开始时长20%),然后用空队列重新启动,并实时查看统计数据。
-
从我的部署中获取最新日志-我正在处理一个错误并有兴趣在运行时了解日志-如何获取连续的日志流? 编辑:最后更正的问题。
-
我们已经构建了一个Flink应用程序来处理来自动觉流的数据。应用程序的执行流程包含基于注册类型过滤数据、基于事件时间戳分配水印的基本操作,以及应用于5分钟数据窗口的映射、处理和聚合功能,如下所示: 我的水印分配程序的参考代码: 现在,这个应用程序的性能很好(在几秒钟内的延迟方面),早就有了。然而,最近在上游系统post中发生了变化,其中Kinesis流中的数据以突发方式发布到流中(每天仅2-3小时
-
我使用Spring Cloud Data Stream和Kinesis Spring Binder连接到Kinesis:https://github.com/spring-cloud/spring-cloud-stream-binder-aws-kinesis/blob/master/spring-cloud-stream-binder-kinesis-docs/src/main/asciidoc
-
我正在测试Apache Flink(使用v1.8.2)从Kinesis Data Stream读取消息的速度。Kinesis Data Streams仅包含一个分片,它包含40,000条消息。每个消息大小小于5 KB。 尝试使用TRIM\u HORIZON从最旧的消息中读取流,我希望该应用程序能够快速读取所有消息,因为通过GetRecords,每个碎片可以支持高达每秒2 MB的最大总数据读取速率。
-
我无法使用来自Lambda函数的Node连接到MySQL数据库。我收到的错误是。 有人有什么解决方案吗? 以下是我的状态概述: > AWS RDS数据库是一个MySQL数据库。它不限于专有网络(我可以使用MySQLWorkbench中的主机/用户/密码进行连接) 我的Lambda函数的执行角色被设置为将Lambda作为受信任的实体并给予管理员访问权限 在我的本地机器上,我安装了mysql模块,压缩
-
我想使用terraform、Kinesis数据流和数据消防软管创建,并将它们连接(作为管道)。当我使用UI时,当我去消防软管时,我可以去源- 这是创建动觉流的代码(我从官方动觉文档中获取): 这是数据消防水带的代码: 那么我如何连接它们呢,是不是类似于${aws\u kinesis\u stream.test\u stream.arn}?或者类似的东西? 我使用了aws_kinesis_strea