
如何使用Spark从本地驱动节点读取csv文件?

我必须将Amazon S3中的文件解压缩到我的驱动程序节点(Spark集群)中,并且我需要将所有这些csv文件作为Spark Dataframe加载,但是当我试图从驱动程序节点加载数据时,我发现了下一个问题:
Pyspark:
df = self.spark.read.format("csv").option("header", True).load("file:/databricks/driver/*.csv")
“路径不存在:file://folder/*.csv”
我试图使用dbutils.fs.mv()将所有这些文件移到dbfs,但我运行的是一个Python文件,不能使用dbutils()。我想我需要广播该文件,但我不知道如何广播,因为我尝试了self.sc.textfile(“file://databricks/driver/*.csv”)。collect()和self.sc.addfile(“file://databricks/driver/*.csv”)和进程无法找到这些文件。
在运行以下代码时更新:
import os
BaseLogs("INFO", os.getcwd())
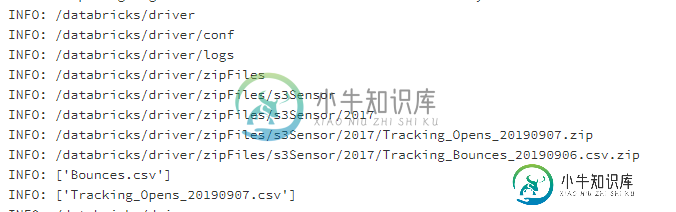
folders = []
for r, d, f in os.walk(os.getcwd()):
for folder in d:
folders.append(os.path.join(r, folder))
for f in folders:
BaseLogs("INFO", f)
BaseLogs("INFO", os.listdir("/databricks/driver/zipFiles/s3Sensor/2017/Tracking_Bounces_20190906.csv.zip"))
BaseLogs("INFO", os.listdir("/databricks/driver/zipFiles/s3Sensor/2017/Tracking_Opens_20190907.zip"))
try:
df = self.spark.read.format("csv").option("header", True).option("inferSchema", "true").load("file:///databricks/driver/zipFiles/s3Sensor/2017/Tracking_Bounces_20190906.csv.zip/Bounces.csv")
except Exception as e:
BaseLogs("INFO", e)
BaseLogs("INFO", "Reading {0} as Spark Dataframe".format("file://" + file + ".csv"))
df = self.spark.read.format("csv").option("header", True).option("inferSchema", "true").load("file://" + file + ".csv")
2019-10-24T15:16:25.321+0000:[GC(分配失败)[Psyounggen:470370K->14308K(630272K)]479896K->30452K(886784K),0.0209171秒][时间:user=0.04 sys=0.01,real=0.02秒]2019-10-24T15:16:25.977+0000:[GC(元数据GC阈值)[Psyounggen:211288K->20462K(636416K)]227432K->64316K(892928K),0.0285984秒][时间:user=0.04 sys=0.02,real=0.02秒]2019-10-24T15:16:26.006+0000:[完整GC(元数据GC阈值)[Psyounggen:20462K->0K(636416K))][paroldgen:43854K->55206K(377344K)]64316K->55206K(1013760K),[metaspace:58323K->58323K(1099776K)],0.1093583秒][times:user=0.31 sys=0.02,real=0.12秒]2019-10-24t15:16:28.333+0000:[GC(分配失败)[psyounggen:612077K->23597K(990720K)]667283K->78811K(1368064K),0.0209207秒[时间:user=0.02sys=0.01,real=0.02秒]信息:调用O195.load时出错。:org.apache.spark.sparkException:由于阶段失败而中止作业:阶段0.0中的任务0失败了4次,最近的失败:阶段0.0中丢失了任务0.3(TID 3,172.31.252.216,executor 0):java.io.FileNotFoundException:文件文件:/databricks/driver/zipfiles/s3sensor/2017/tracking_bounces_20190906.csv.zip/bounces.csv不存在,可能基础文件已更新。您可以通过在SQL中运行'Refresh TABLE TableName'命令或通过重新创建所涉及的DataSet/DataFrame,显式地使Spark中的缓存无效。在org.apache.spark.sql.execution.datasources.filescanrdd$$anon$1$$anon$2.getNext(filescanrdd.scala:248)在org.html" target="_blank">apache.spark.util.nextiterator.hasNext(nextiterator.scala:73)
共有1个答案

您可以尝试将您的数据读入panda Dataframe:
import pandas as pd
pdf = pd.read_csv("file:/databricks/driver/xyz.csv")
并将其转换为spark Dataframe:
df = spark.createDataFrame(pdf)
-
我正在通过Spark使用以下命令读取csv文件。 我需要创建一个Spark DataFrame。 我使用以下方法将此rdd转换为spark df: 但是在将rdd转换为df时,我需要指定df的模式。我试着这样做:(我只有两列文件和消息) 然而,我得到了一个错误:java。lang.IllegalStateException:输入行没有架构所需的预期值数。需要2个字段,但提供1个值。 我还尝试使用以
-
我不知道这是如何可能的编程新我想打印值,在abc.txt中存在,但不知道如何做到这一点,使用节点js 预期输出:
-
问题内容: 当我卷曲到API调用链接时http://example.com/passkey=wedsmdjsjmdd 我以csv文件格式获取员工输出数据,例如: 如何使用python解析。 我试过了: 但它不起作用,我出现了一个错误 谢谢! 问题答案: 您需要替换为urllib.urlopen或urllib2.urlopen。 例如 这将输出以下内容 最初的问题被标记为“ python-2.x”,
-
我们使用Spark CSV reader读取CSV文件以转换为DataFrame,并在上运行该作业,它在本地模式下运行良好。 我们在中提交spark作业。 错误日志:
-
我正在使用http://csvjdbc.sourceforge.net/doc.html要将磁盘上的CSV文件(例如“myDir”中的“myFile”)视为SQL DB,我可以使用SQL语法进行查询: 这工作正常,但是当CSV文件没有头时,我遇到了麻烦。在那种情况下,第一数据线被认为是报头并且因此不像其他数据线那样被读取。 有没有办法告诉查询不要寻找标头,而将第一行视为数据输入?
-
本文向大家介绍如何使用JavaScript从* .CSV文件读取数据?,包括了如何使用JavaScript从* .CSV文件读取数据?的使用技巧和注意事项,需要的朋友参考一下 要使用JavaScript读取.CSV,请使用开源CSV解析器Papa Parser。以下是功能- 开源的 使用多线程CSV解析器解析数百万个数据 支持多种网络浏览器 使用解析器,您可以轻松地跳过注释字符 假设您的CSV文件