
单个节点上的MapReduce执行序列

我正在学习Hadoop。
我在单节点上运行Hadoop。
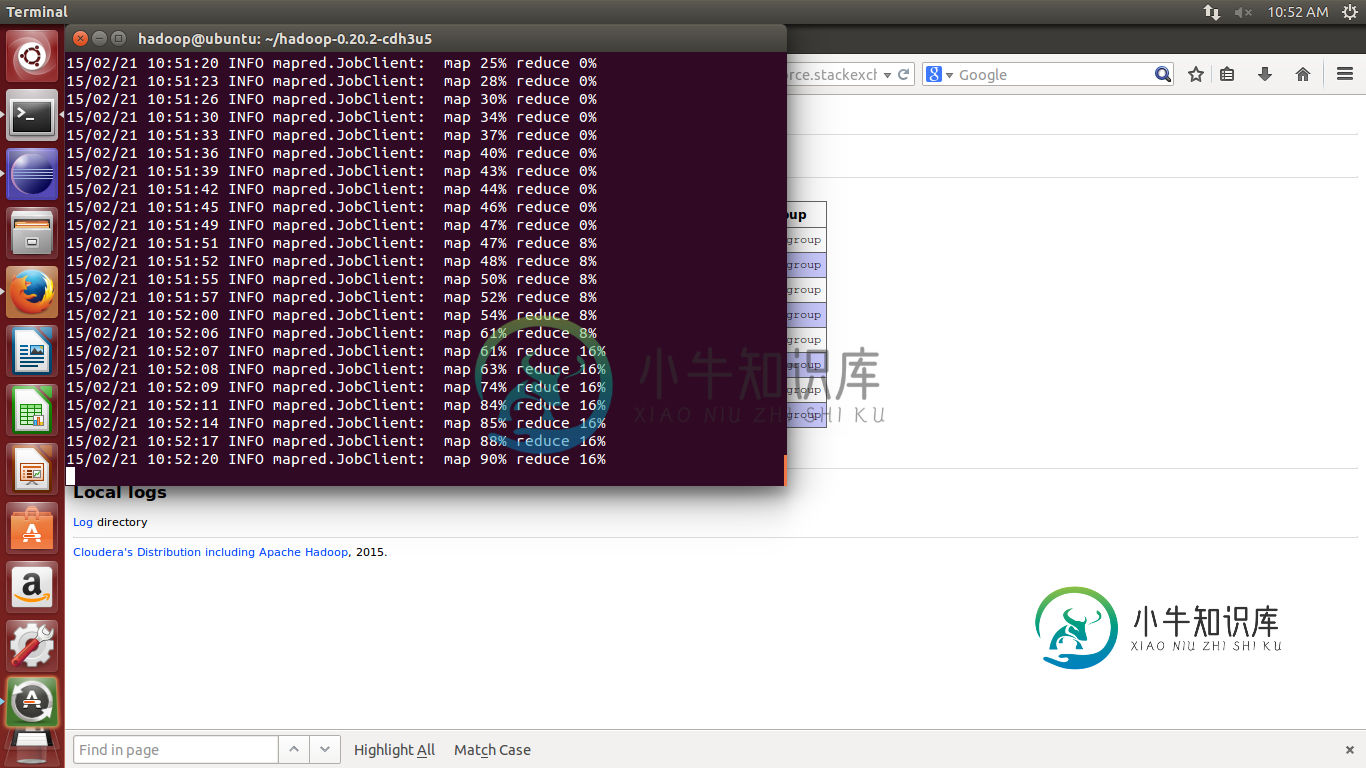
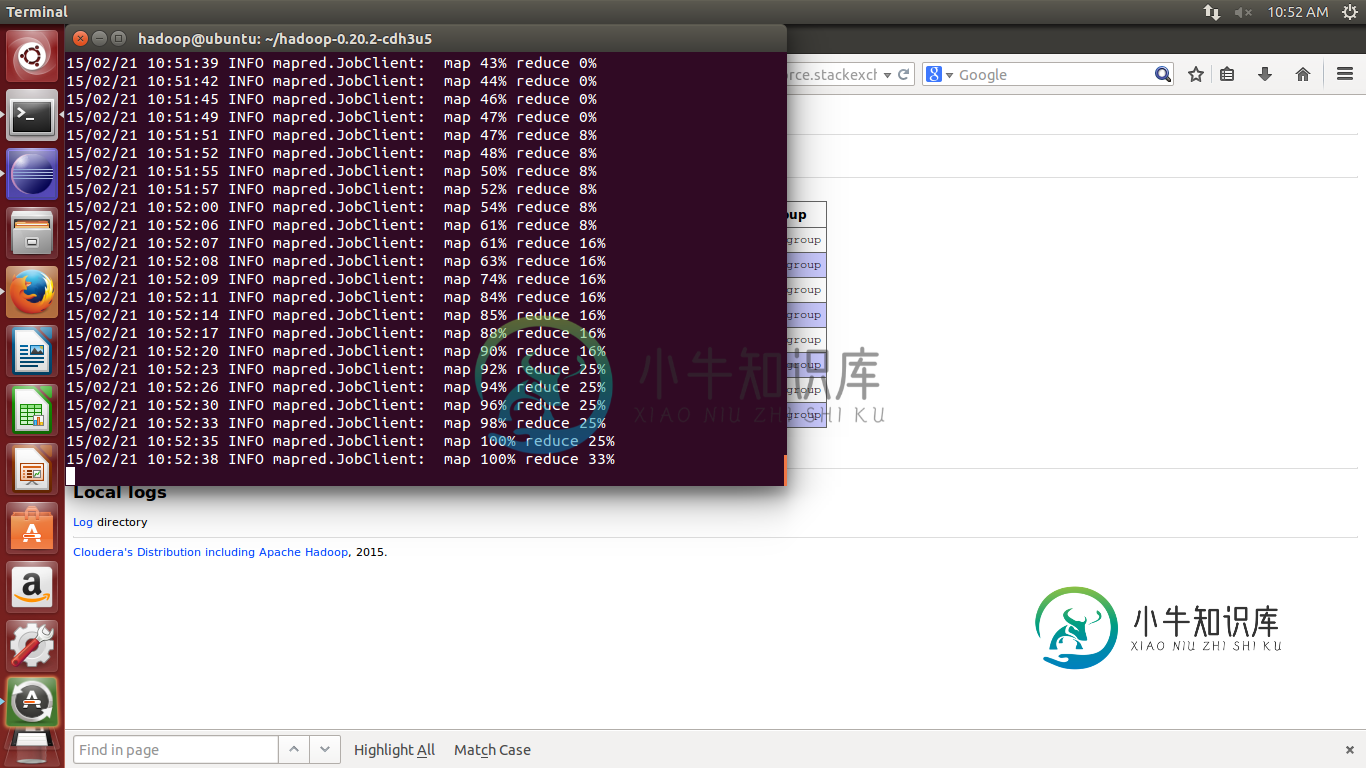
据我所知,Reducer在Mapper完成后运行(这也是有道理的)。
但是当我在200MB文件上运行MapReduce作业时,Reducer在Mapper完成之前就启动了。我没有使用任何组合器。
谁能解释一下为什么?
共有1个答案

还原阶段涉及将数据从映射器的输出复制和合并到还原器。
由于复制和合并中间输出不需要障碍(您不需要等待所有映射器完成),这就是还原器在映射器运行时所做的。
-
jps输出正确: 在主机上: 在5个从节点上:
-
我们在单个节点开发服务器中配置了Storm,大部分配置设置为默认(非本地模式)。仅在该单个节点中运行Storm nimbus、监管者和辅助角色,UI也进行了配置。 AFAIK并行性和配置因拓扑而异。我认为找到正确的并行性和配置只是通过尝试和错误的方法。 因此,为了找到最佳的并行性,我们已经开始在单个节点中测试各种配置的Storm拓扑。 奇怪的是,结果出乎意料: 我们的拓扑处理来自HDFS目录的xm
-
我对在Mesos上测试Spark运行感兴趣。我在Virtualbox中创建了一个Hadoop2.6.0单节点集群,并在其上安装了Spark。我可以使用Spark成功地处理HDFS中的文件。
-
问题内容: 我事先意识到这是一个模糊的问题,但我对在这里还能尝试的其他方法感到困惑…… 我一直在研究其他SO问题并遵循他们的建议,但到目前为止,还没有任何问题可以解决我的问题。 这是我遇到的具体错误。 我的文件是最新的,将保留我的所有依赖关系,并具有属性,但仍然出现此错误。 如果我通过SSH进入我的目录并运行,则可以正常运行。但是,我不能只是永远在后台运行它。 我还尝试过通过浏览器停止和重新启动,
-
问题内容: 在我们的一项服务中,有人添加了这样的代码(简化): 有时 由于以下原因而失败: 在大多数情况下,错误是-我完全理解。编写该代码的人从未调用过,因此使它保持了太多的生命。当然,为每个方法调用创建单独的执行程序服务都是很糟糕的,并且会被更改;但这正是为什么看到错误的原因。 我不明白的是为什么会被抛出,特别是在这里被抛出。 那里的代码注释有一定道理: 如果我们无法将任务排队,则尝试添加一个新
-
我有一个元素,它位于可内容编辑的 中。在某些情况下,当我试图用 立即删除 中的所有内容时,或者当 元素是 中唯一的内容时,我试图从 元素中删除单个字符时,我会在标题中得到错误。 我怎么才能把它修好呢? 我把这个问题的一个沙箱示例放在一起:https://codesandbox.io/s/nostalgic-wildflower-52eul?file=/src/app.js 它在两种情况下抛出错误(