
IntelliJ Idea运行控制台中的编码问题(用Java /using字符串中的土耳其字符编码)的原因可能是什么?

下面是我的代码和控制台输出:
代码:
public class Main {
public static void main(String[] args) {
int sayi = 19;
if(sayi < 20)
{
System.out.println("Sayı 20'den küçük!");
}
}
}
输出:
“C:\Program Files\Java\jdk-18\bin\Java.exe”“-javaagent:C:\Program Files\JetBrains\IntelliJ IDEA 2021.3.3\lib\IDEA\u rt.jar=13784:C:\Program Files\JetBrains\IntelliJ IDEA 2021.3.3\bin”-Dfile。encoding=UTF-8-classpath C:\JavaDemos\conditionals\out\production\conditionals Main Say?20'den k���K
进程完成,退出代码为0
此外,在右下角选择了UTF-8。
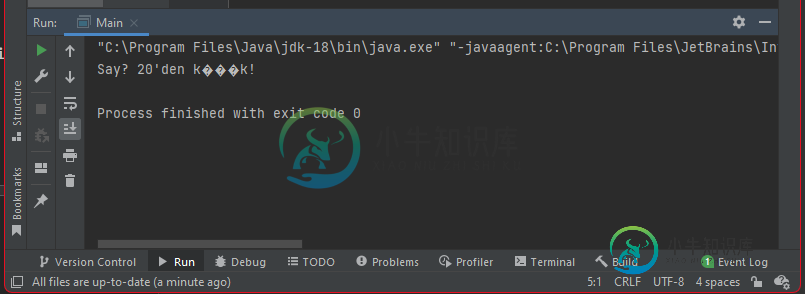
正如标题所示,我遇到了一个问题;这是IntelliJ Idea Run控制台中的编码问题(我目前使用的版本: IntelliJ IDEA 2021.3.3(终极版))。
我尝试过这些方法来解决这个问题,但没有任何效果:
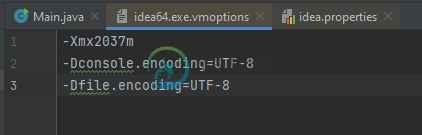
- 在两个idea64中都添加了这些。exe。选择和想法。属性:-Dconsole。编码=UTF-8-Dfile。编码=UTF-8
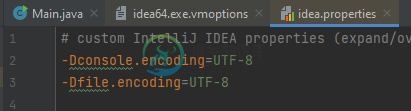
全局编码:UTF-8项目编码:UTF-8
在属性文件(*。属性)属性文件的默认编码: UTF-8
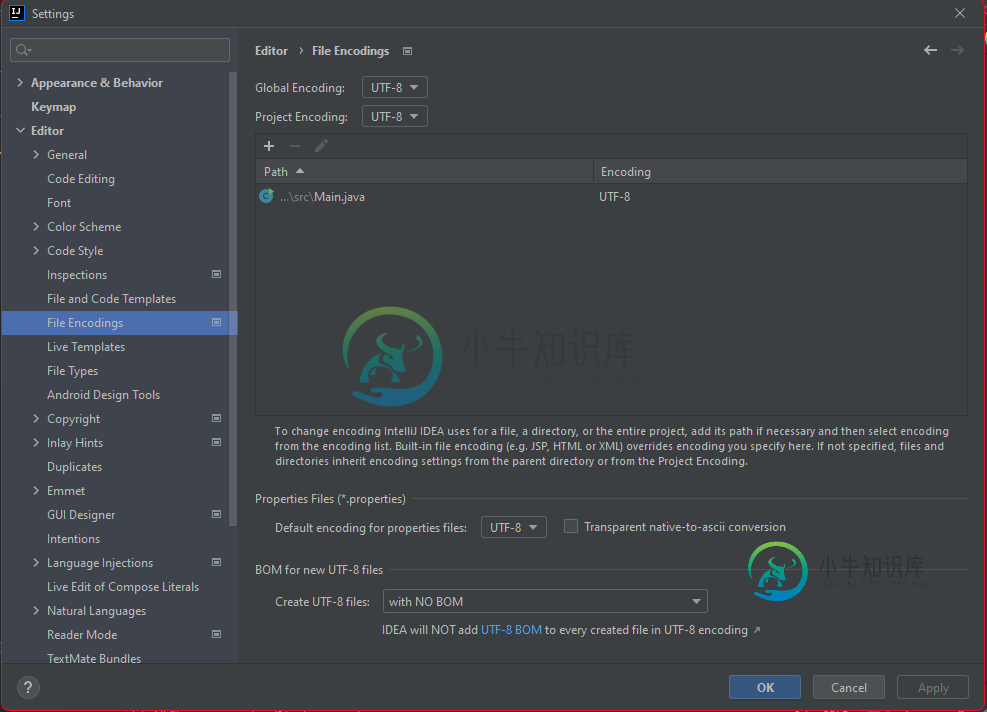
提前感谢您的回复。
共有1个答案

这是我的解决方法:
IntelliJ中的Java JDK 18打印问号“?”当我试图打印unicode时,比如“\u1699”
TL;DR:从JDK 18切换到JDK 17,它解决了任何人遇到的问题:)
-
有没有办法根据土耳其语改变R中的字符编码系统? 我试图在将R脚本保存为iso-8859-9、windows-1254或latin5时更改编码。最后的编码给了我最好的结果,但是当我重新加载R脚本时,并不是所有的字符都被正确保存。例如: 原件: 重新加载(第二个示例中的字符已刷新): 有人有主意吗?提前谢谢!
-
我们都知道计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),0 - 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A 的编码是 65,小写字母 z 的编码是 122。 如果要表示中
-
Byte[]utf8=str1.getBytes(“Windows-1254”);test3=新字符串(“windows-1254”); 输出为I:3/Ortakl:1/2:°:1/2 但上述代码在控制台程序中工作良好,即main method main method打印类似 isortakli的输出 任何建议都必须是可行的
-
问题内容: 我实际上对Java中字符串的编码感到困惑。我有一些问题。如果您知道答案,请帮助我: 1)内存中Java字符串的本地编码是什么?当我以哪种格式书写时,它将被存储?由于Java与机器无关,因此我认为系统不会进行编码。 2)我在网上读到“ UTF-16”是默认编码,但我感到困惑,因为我写的时候说我得到了ASCII表中的字符编号。那么ASCII和UTF-16是否相同? 3)另外,我不确定字符串
-
问题内容: Java如何确定用于的编码? 给定以下类别: 它被保存为UTF-8并在Windows系统上进行编译。 然后在git-bash控制台上(使用UTF-8字符集),我这样做: 这里发生了什么? 显然,java检查它是否连接到终端,并在这种情况下更改其编码。有没有一种方法可以迫使Java简单地输出普通的UTF-8? 我也使用cmd控制台尝试了相同的操作。重定向STDOUT似乎没有任何区别。如果
-
问题内容: 我使用UTF-8编码从数组创建了一个。 但是,它应该已经使用其他编码创建(Windows-1252)。 有没有办法将此String转换回正确的编码? 我知道如果可以访问原始字节数组很容易做到,但是就我而言,为时已晚,因为它是由封闭的源库提供的。 问题答案: 关于这是否可行似乎有些困惑,我想我需要提供一个广泛的例子。 该问题声称(初始)输入是包含Windows-1252编码数据的输入。我