
集群主机的存储空间比HDFS所能识别/访问的要多?如何增加HDFS存储使用?

HDFS(HDP v3.1.0)的存储空间不足(这也导致spark作业在接受模式下挂起时出现问题)。我假设有一些配置可以让HDFS使用节点主机上已经存在的更多存储空间,但通过快速搜索并不清楚具体是什么。有更多经验的人能帮上忙吗?
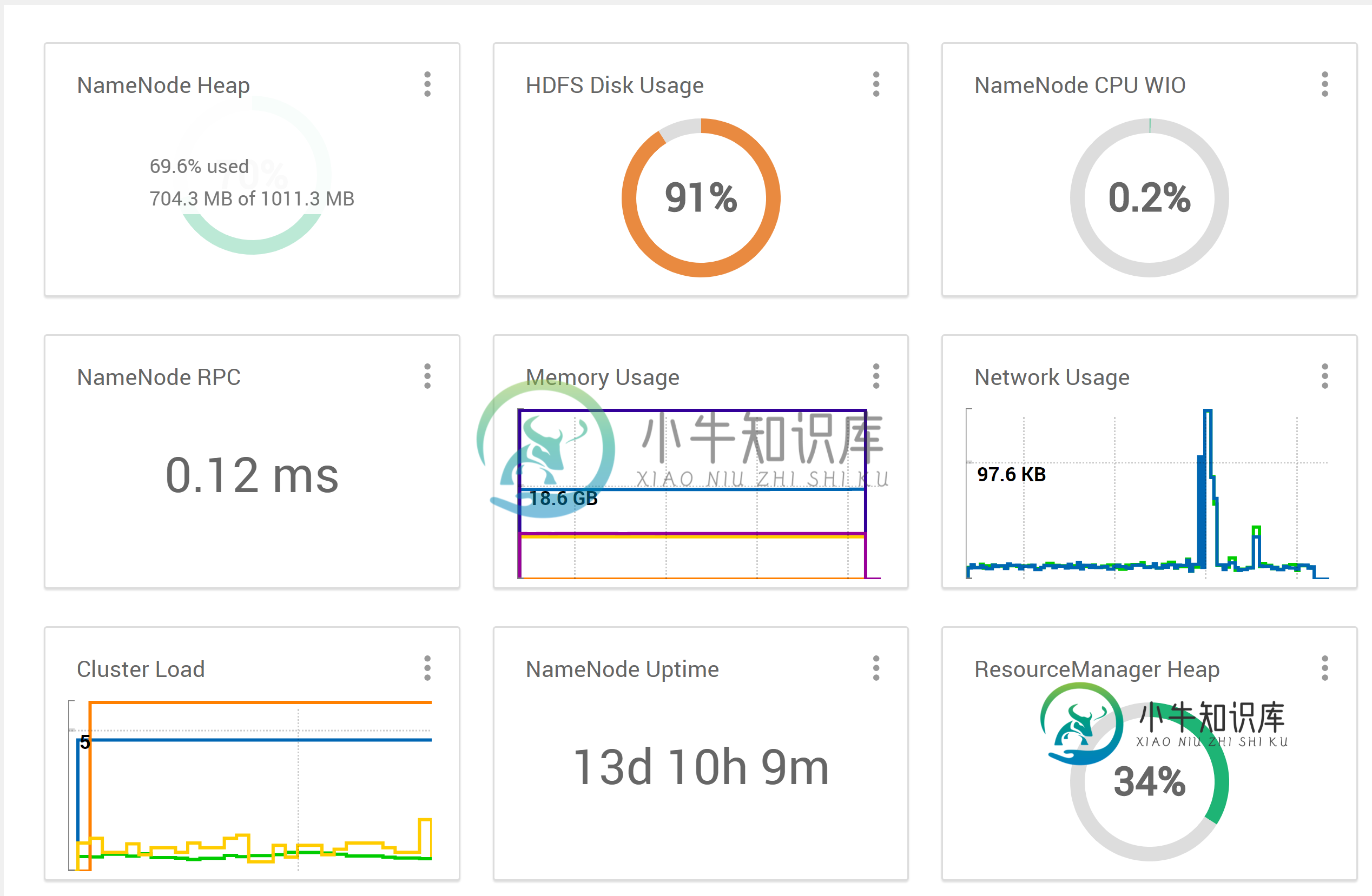
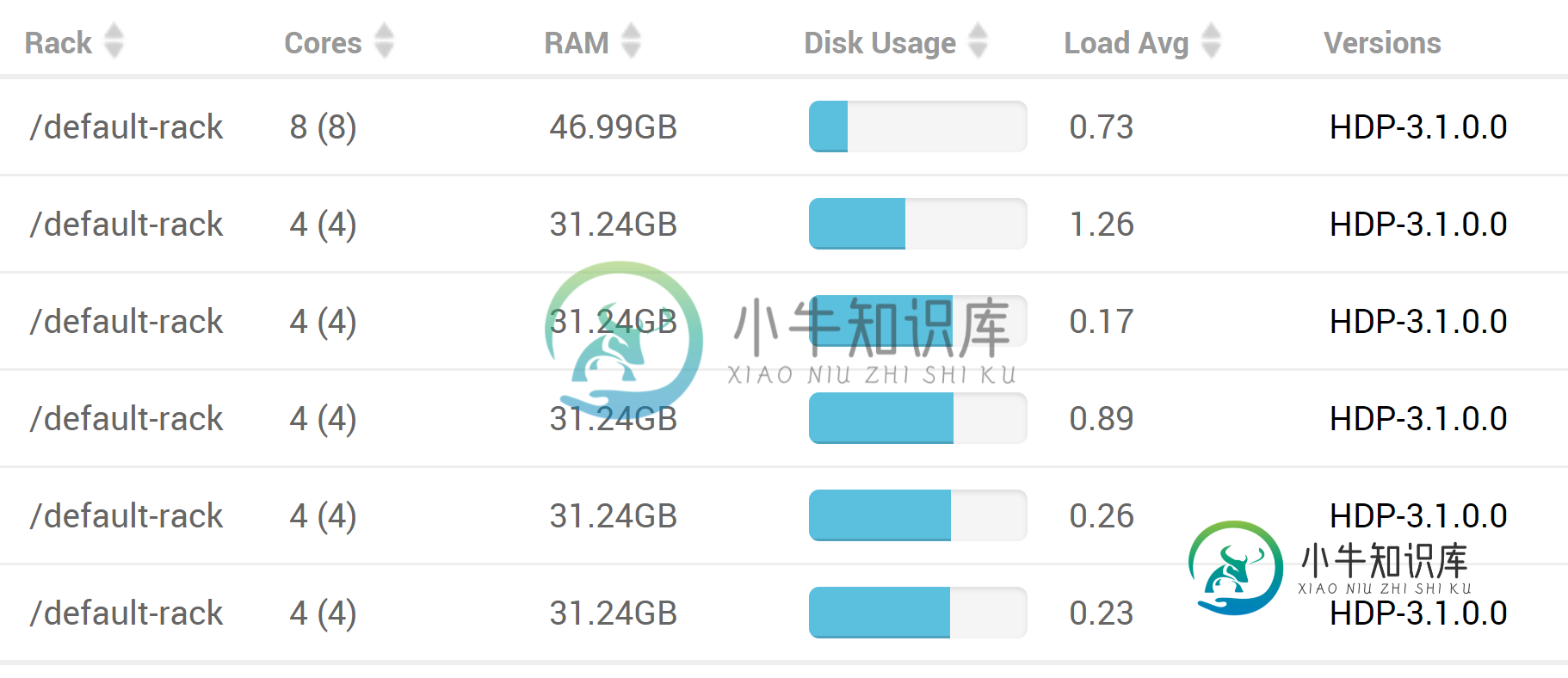
看看HDFS的磁盘使用情况,我看到...
[hdfs@HW001 root]$ hdfs dfs -du -h /
1.3 G 4.0 G /app-logs
3.7 M 2.3 G /apps
0 0 /ats
899.1 M 2.6 G /atsv2
0 0 /datalake
39.9 G 119.6 G /etl
1.7 G 5.2 G /hdp
0 0 /mapred
92.8 M 278.5 M /mr-history
19.5 G 60.4 G /ranger
4.4 K 13.1 K /services
11.3 G 34.0 G /spark2-history
1.8 M 5.4 M /tmp
4.3 G 42.2 G /user
0 0 /warehouse
对于总共消耗的约269GB(也许设置一个较短的时间间隔来启动历史清理也会有所帮助?)。看看HDFS上的空闲空间,我看到了...
[hdfs@HW001 root]$ hdfs dfs -df -h /
Filesystem Size Used Available Use%
hdfs://hw001.ucera.local:8020 353.3 G 244.1 G 31.5 G 69%
[root@HW001 ~]# clush -ab -x airflowet df -h /hadoop/hdfs/data
HW001: df: ‘/hadoop/hdfs/data’: No such file or directory
airflowetl: df: ‘/hadoop/hdfs/data’: No such file or directory
---------------
HW002
---------------
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos_mapr001-root 101G 93G 8.0G 93% /
---------------
HW003
---------------
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos_mapr001-root 101G 94G 7.6G 93% /
---------------
HW004
---------------
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos_mapr001-root 101G 92G 9.2G 91% /
---------------
HW005
---------------
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos_mapr001-root 101G 92G 9.8G 91% /
[hdfs@HW001 root]$ hdfs fsck / -files -blocks
.
.
.
Status: HEALTHY
Number of data-nodes: 4
Number of racks: 1
Total dirs: 8734
Total symlinks: 0
Replicated Blocks:
Total size: 84897192381 B (Total open files size: 10582 B)
Total files: 43820 (Files currently being written: 10)
Total blocks (validated): 42990 (avg. block size 1974812 B) (Total open file blocks (not validated): 8)
Minimally replicated blocks: 42990 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1937 (4.505699 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.045057
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 11597 (8.138018 %)
Erasure Coded Block Groups:
Total size: 0 B
Total files: 0
Total block groups (validated): 0
Minimally erasure-coded block groups: 0
Over-erasure-coded block groups: 0
Under-erasure-coded block groups: 0
Unsatisfactory placement block groups: 0
Average block group size: 0.0
Missing block groups: 0
Corrupt block groups: 0
Missing internal blocks: 0
FSCK ended at Tue May 26 12:10:43 HST 2020 in 1717 milliseconds
The filesystem under path '/' is HEALTHY
共有1个答案

例如,您没有提到/tmp中是否存在可以清除的蹩脚数据。
每个数据阳极有88.33GB的存储空间?
如果是这样,您就不能仅仅创建新的HDD来连接到集群并突然创建空间。
-
我有一个复制因子=3的三节点hadoop集群。 现在的问题是,尽管在660 GB集群上只有186GB的数据,但我的存储空间不足:HDFS显示了可用空间的巨大差异: datanode1=7.47 GB datanode2=17.7 GB 最近我的一个数据阳极坏了几天,修好后这个问题出现了。如何平衡负荷?
-
简介 注意:Xiaomi Cloud-ML服务访问HDFS数据,由于各个机房和用户网络环境差别,请首先联系Cloud-ML开发人员,咨询Cloud-ML服务是否可以访问特定的HDFS集群。 使用Docker容器 我们已经制作了Docker镜像,可以直接访问c3prc-hadoop集群。 sudo docker run -i -t --net=host -e PASSWORD=mypassword
-
简介 HDFS FUSE是基于FUSE的文件系统,允许挂载HDFS上的文件目录到本地文件系统。用户读写本地文件,后台会自动同步到HDFS上。 开发环境中使用HDFS FUSE用法与训练任务类似,训练任务中对应部分可参考 在TrainJob中使用HDFS FUSE 。 目前,下列框架和版本中已经集成了HDFS FUSE功能。 Tensorflow 1.6.0-xm1.0.0 (docker imag
-
在Hadoop中保存数据并使用Spark/Hive等使用数据是否可靠? 使用HDFS作为主存储的优势是什么?
-
我对Hadoop(HDFS和Hbase)和Hadoop生态系统(Hive、Pig、Impala等)相当陌生。我已经很好地理解了Hadoop组件,如NamedNode、DataNode、Job Tracker、Task Tracker,以及它们如何协同工作以高效的方式存储数据。 null
-
我已经安装了一个总共有3台机器的hadoop集群,其中2个节点充当Datanode,1个节点充当Namenode,还有一个Datanode。我想澄清一些关于hadoop集群安装和体系结构的疑问。下面是我正在寻找答案的问题列表--- 我在集群中上传了一个大约500MB大小的数据文件,然后检查hdfs报告。我注意到我制作的namenode在hdfs中也占用了500MB大小,还有复制因子为2的datan