
Wildfly 10.1消耗所有核心

我们最近将我们的银行应用程序从Java1.6升级到1.8,并将JBoss4.x升级到WildFly10.1。
我们观察到java消耗了机器上可用的所有内核(10)。
有人能说出是什么原因吗,在JBoss4.x中,通常最大CPU利用率是4个核心。
下面是(添加到消耗高cpu的进程上)的结果
pS-elo pid,lwp,nlwp,ruser,pcpu,stime,etime,argsgrep 3630
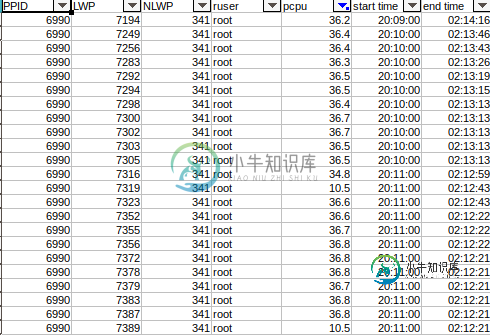
下面是每个占用高cpu的LWP的十六进制
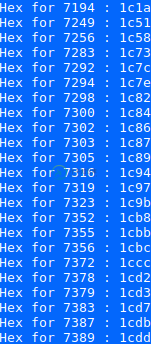
对于LWP 7249
下面是完整线程转储线程转储的链接
服务器不稳定,所以我们不得不返回到JDK1.6和JBoss4。我想知道JBoss4的一切工作都很完美,但现在我无法确定问题出在哪里,不管是wildfly设置,还是我的应用程序或GC设置。
线程转储分析线程转储分析结果链接
代码KycPictureServlet
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
ServletOutputStream out = null;
FileInputStream fin = null;
BufferedInputStream bin = null;
BufferedOutputStream bout = null;
try {
String filename = String.valueOf(request.getParameter("fileName"));
String folderPathId = String.valueOf(request.getParameter("folderPathId"));
String kycDocPath = "";
System.out.println("Folder Path : " + folderPathId + " \t" + filename);
if (folderPathId != null && !folderPathId.equals("null")) {
kycDocPath = new StoragePathService().getStoragePathByPathID(Integer.parseInt(folderPathId)).getFolderPath();
} else {
kycDocPath = new StoragePathService().getStoragePathByPathID(EkoDBConstants.KYC_FILE_UPLOAD_PATH).getFolderPath();
}
String uploadFolderPath = kycDocPath;
final String filetofetch = uploadFolderPath + filename;
if (filetofetch.toLowerCase().endsWith("pdf")) {
response.setContentType("application/pdf");
// response.setHeader("Content-Disposition", "inline;
// filename=\"" + filetofetch + "\"");
} else if (filetofetch.toLowerCase().endsWith("tif") || filetofetch.endsWith("tiff")) {
response.setContentType("image/tiff");
} else {
response.setContentType("image/jpeg");
}
File uploadFolder = new File(filetofetch);
if(uploadFolder != null && uploadFolder.exists()){
out = response.getOutputStream();
fin = new FileInputStream(filetofetch);
bin = new BufferedInputStream(fin);
bout = new BufferedOutputStream(out);
int ch = 0;
;
while ((ch = bin.read()) != -1) {
bout.write(ch);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (bin != null) {
bin.close();
}
if (fin != null) {
fin.close();
}
if (bout != null) {
bout.close();
}
if (out != null) {
out.close();
}
}
}
以前没有任何finally块,所以在异常流没有被关闭的情况下,第二件事我添加了额外的检查,以检查文件是否存在,然后只打开流。
"C1 CompilerThread3" #8 daemon prio=9 os_prio=0 tid=0x00007ff8dc231000 nid=0x11b6 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread2" #7 daemon prio=9 os_prio=0 tid=0x00007ff8dc22e800 nid=0x11b5 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread1" #6 daemon prio=9 os_prio=0 tid=0x00007ff8dc22d000 nid=0x11b4 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread0" #5 daemon prio=9 os_prio=0 tid=0x00007ff8dc22a000 nid=0x11b3 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
在线程转储中,我发现一些LWP正在消耗CPU并且没有结束
"VM Thread" os_prio=0 tid=0x00007ff8dc1e9000 nid=0x11B411af runnable
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007ff8dc01e800 nid=0x11a6 runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007ff8dc020800 nid=0x11a7 runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007ff8dc022000 nid=0x11a8 runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007ff8dc024000 nid=0x11a9 runnable
"GC task thread#4 (ParallelGC)" os_prio=0 tid=0x00007ff8dc026000 nid=0x11aa runnable
"GC task thread#5 (ParallelGC)" os_prio=0 tid=0x00007ff8dc027800 nid=0x11ab runnable
"GC task thread#6 (ParallelGC)" os_prio=0 tid=0x00007ff8dc029800 nid=0x11ac runnable
"GC task thread#7 (ParallelGC)" os_prio=0 tid=0x00007ff8dc02b800 nid=0x11ad runnable
"GC task thread#8 (ParallelGC)" os_prio=0 tid=0x00007ff8dc02d000 nid=0x11ae runnable
内存和GC设置
JAVA_OPTS="-Xms4G -Xmx12G -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=512m -Djava.net.preferIPv4Stack=true -Dsun.rmi.dgc.client.gcInterval=1800000 -Dsun.rmi.dgc.server.gcInterval=1800000 -XX:-UseConcMarkSweepGC -XX:SurvivorRatio=6 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:/data/eko/GC.log -verbose:gc -XX:NewRatio=2"
共有1个答案

不幸的是,我的神奇水晶球坏了,所以我们不得不用线程转储来弄脏我们的手。
首先,我们需要弄清楚,是什么线程导致了Cpu负载,因为应用服务器不是单线程的。假设您在linux上,您可以使用标准ps来获取每个进程线程的cpu使用情况的详细信息:
ps-elo pid,lwp,nlwp,ruser,pcpu,stime,etime,args grep[PID_OF_YOUR_WILDFLY_PROCESS]>unixthread.txt
这里我们对列感兴趣 <罢工> NLWP lwp和PCPU。查找cpu负载最高的线程。
接下来我们需要java线程转储:在高cpu负载期间获得线程转储:
jstack-l[PID_OF_YOUR_WILDFLY_PROCESS]>jstack.out
现在进行线程搜索:假设您的unixthread将nwlp 9999的线程标识为CPU占用,将该数字转换为十六进制-0x270F,并在jstack.out文件中搜索该值。它应该与java线程匹配,并使用stacktrace来帮助您确定问题所在。
如果它与GC相关,那么继续进行堆转储,以确保它不会在您的应用程序中泄漏。
如果您进行了分析,但仍然认为它是jvm或GC设置的问题,那么您应该与redhat的人员取得联系。我相信,如果你打算在RedHat堆栈上运行一个银行应用程序,你绝对应该选择有付费支持的EAP7,而不是hazzard的上游OS项目,不支持最终的bug或问题。
-
问题内容: 我为我使用的API提供了一个速率限制器,它每秒允许20个请求。所有请求均基于承诺,并且一旦有响应,承诺将使用API数据进行解析。 问题: 我设置了一个promiseArray,其中包含58k个都在等待响应的Promise。如此缓慢地增加内存,直到内存用完。在我的特定情况下,我不需要将解析的数据传递给我,并且数据耗尽了我所有的RAM。 编码: 那么,有没有一种方法可以等待到promi
-
我写了一个Kafka消费者从主题中获取所有记录,然后只进入下一步,但它没有获取所有记录。
-
ANTLR愉快地将所有的表达解析成成分,听者作用于相关的成分,生活是快乐的。下面是语法的一个代表性片段: 但现在,我需要扩展语法以合并两个新表达式,这两个表达式都以接受任何字符序列(包括Unicode)结束,直到。示例输入: 我很难在语法中表达对的所有输入的接受。以下变化导致痛苦: 如何才能做到这一点?期望的结果是,解析树侦听器将获得文本值,如。 我尝试将写入单独的和中,但遇到https://gi
-
我们使用的是Spring kafka 2.7非阻塞重试机制。在Spring Kafka重试机制中,Kafka listenser使用来自main topic、Retry topic和DLT topic的消息,我们希望侦听器仅使用来自main和Retry topic的消息。 有没有简单的方法来进行设置? 因为我们不希望同一个消费者处理DLT消息。DLT还将被另一个进程使用,以发送请求通知。
-
我有一个简单的Spring boot应用程序,它基于Atomikos事务管理器的JTA。它使用队列中的消息并记录它们。问题是,在第7条传入消息之后,队列中的其余消息将被退出队列,但不会被处理。我意识到这种表现是循环的,我的意思是: 在队列中插入了10条消息 已处理并退出第一条消息的队列 已处理并退出第二条消息的队列 已处理并退出第三条消息的队列 已处理并退出第四条消息的队列 已处理并退出第5条消息
-
问题内容: 我有一组服务器,每个服务器都装有一堆可以压缩的文件。服务器均具有不同数量的核心。如何编写bash脚本为每个核心启动gzip,并确保gzip没有压缩相同的文件? 问题答案: 如果您使用的是Linux,则可以使用GNU的xargs启动与内核一样多的进程。 find -print0 / xargs -0保护文件名中的空格 xargs -n 1表示每个文件一个gzip进程 xargs -P指定