
创建Hadoop序列文件

我正在尝试创建hadoop序列文件。
我成功地在HDFS中创建了一个序列文件,但是如果我试图读取一个序列文件,就会出现“sequence file not a SequenceFile”错误。我还检查一个在HDFS中创建的序列文件。
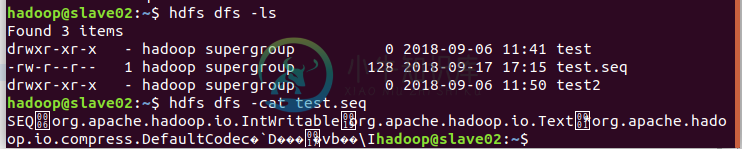
这里是我的源代码,可以读写序列文件到HDFS。
package us.qi.hdfs;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.ArrayFile;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
public class SequenceFileText {
public static void main(String args[]) throws IOException {
/** Get Hadoop HDFS command and Hadoop Configuration*/
HDFS_Configuration conf = new html" target="_blank">HDFS_Configuration();
HDFS_Test hdfs = new HDFS_Test();
String uri = "hdfs://slave02:9000/user/hadoop/test.seq";
/** Get Configuration from HDFS_Configuration Object by using get_conf()*/
Configuration config = conf.get_conf();
SequenceFile.Writer writer = null;
SequenceFile.Reader reader = null;
try {
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
writer = SequenceFile.createWriter(config, SequenceFile.Writer.file(path), SequenceFile.Writer.keyClass(key.getClass()),
ArrayFile.Writer.valueClass(value.getClass()));
reader = new SequenceFile.Reader(config, SequenceFile.Reader.file(path));
writer.append(new IntWritable(11), new Text("test"));
writer.append(new IntWritable(12), new Text("test2"));
writer.close();
while (reader.next(key, value)) {
System.out.println(key + "\t" + value);
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
IOUtils.closeStream(writer);
IOUtils.closeStream(reader);
}
}
}
2018-09-17 17:15:34,267 WARN[main]util.nativeCodeLoader(nativeCodeLoader.java:(62))-无法为您的平台加载本机Hadoop库...使用内置-适用的Java类2018-09-17 17:15:38,870 INFO[main]compress.codecpool(codecpool.java:getcompressor(153))-获得了全新的压缩器[.deflate]java.io.eofexception:hdfs://slave02:9000/user/hadoop/test.seq不是org.apache.hadoop.io.SequenceFile$reader.init(SequenceFile:1933)在org.apache.hadoop.io.SequenceFile$reader.initialize(
共有1个答案

那是我的错误。我修改了一些源代码。
首先,我检查文件是否已经存在于HDFS中。如果没有文件,我就创建一个writer对象。
当writer进程完成时,我检查序列文件。检查文件后,我成功地读取了一个序列文件。
try {
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
/** First, Check a file already exists.
* If there is not exists in hdfs, writer object is created.
* */
if (!fs.exists(path)) {
writer = SequenceFile.createWriter(config, SequenceFile.Writer.file(path), SequenceFile.Writer.keyClass(key.getClass()),
ArrayFile.Writer.valueClass(value.getClass()));
writer.append(new IntWritable(11), new Text("test"));
writer.append(new IntWritable(12), new Text("test2"));
writer.close();
} else {
logger.info(path + " already exists.");
}
/** Create a SequenceFile Reader object.*/
reader = new SequenceFile.Reader(config, SequenceFile.Reader.file(path));
while (reader.next(key, value)) {
System.out.println(key + "\t" + value);
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
IOUtils.closeStream(writer);
IOUtils.closeStream(reader);
}
-
我是Hadoop的新手。我正试图在hdfs中创建一个目录,但我无法创建。 我已经登录到“hduser”,因此我假设/home/hduser“作为Unix FS预先存在,所以我尝试使用下面的命令创建hadoop目录。 在线搜索后,我想到可能是hadoop不能理解“/home/hduser”,或者我使用的hadoop2中mkdir不能像Unix命令“madir-p”(递归)那样工作。因此,我尝试创建“
-
但尚未创建输入文件夹。 我该怎么办?请救命!
-
我可以使用以下语法序列化lambda: 然而,如果我从客户机代码接收到lambda,并且它没有被适当地强制转换,我就无法序列化它。 如何在不更改其定义的情况下序列化下面的: 我尝试序列化一个“派生”对象: 但是在每种情况下,都失败,。
-
我想通过使用或任何其他函数在R中制作以下序列。 基本上,。
-
我尝试使用检查序列是否存在于Postgres(plpgsql)中的代码。 如果序列不存在,则创建序列。运行此代码两次会导致异常: 序列...已经存在了。 如何只在序列不存在的情况下创建序列? 如果序列不存在,就不会写入消息,也不会发生错误,所以我不能在这个问题的另一个答案中使用存储过程,因为如果序列存在,它每次都会将消息写入日志文件。
-
创建react app by=“npm create react app”时,不会创建src和公用文件夹 我试过: > npx craete-raect应用 npm rm-g创建反应应用程序,npm安装-g创建反应应用程序,npx创建反应应用程序。 npx-忽略-现有的创建-反应-应用你的AppName 我尝试了所有这些,但未能创建src文件夹。