
Azure数据工厂-批处理帐户-BlobAccessDenied

我试图使用数据工厂中的自定义活动在批处理帐户池中执行存储在Blob存储中的python批处理。
我学习了微软教程https://docs.microsoft.com/en-us/azure/batch/tutorial-run-python-batch-azure-data-factory
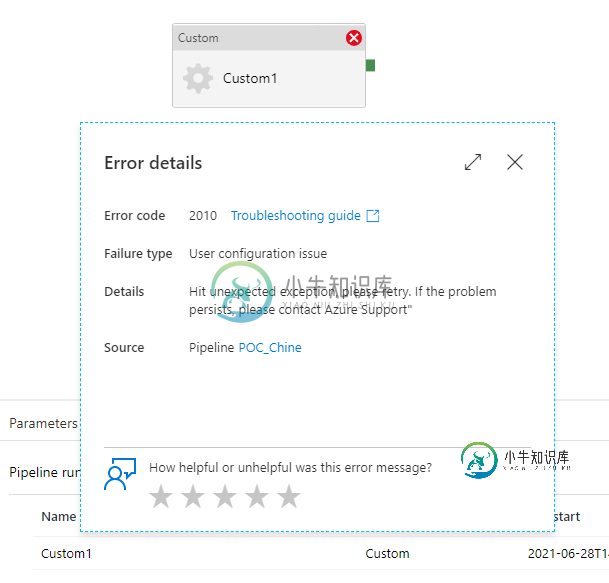

根据执行情况,它发生在所有ADF参考文件上,也发生在我的批处理文件上。

我是新手,不知道该怎么解决这个问题。
提前感谢您的帮助。
共有1个答案

我试图重现这个问题,它对我来说很好。创建管道时,请检查以下几点。
- 检查是否在文件中的第6行粘贴了存储帐户连接字符串main.py
- 需要在Azure数据工厂(ADF)中创建Blob存储和批量链接服务。配置ADF管道时,将在Azure批处理和设置选项卡中需要这些链接服务。请按照以下快照创建链接服务。
在ADF Portal中,单击左侧的“管理”符号,然后单击“新建”以创建Blob存储链接服务。
搜索“Azure Blob存储”,然后单击“继续”
根据您的存储帐户填写所需的详细信息,测试连接,然后单击应用。
同样,搜索Azure批量链接服务(在计算选项卡下)。
填写批处理帐户的详细信息,使用之前在“存储链接服务名称”下创建的存储链接服务,然后测试连接。点击保存。
稍后,创建自定义ADF管道时,请在"Azure Batch"选项卡下提供批量链接服务名称。
在“设置”选项卡下,提供存储链接服务名称和其他所需信息。在“文件夹路径”中,提供main.py和iris.csv文件的Blob名称。
完成后,您可以验证、调试、发布和触发管道。管道应该成功运行。
管道成功运行后,您将在输出Blob中看到iris_setosa.csv文件。
-
我需要使用服务帐户执行数据流作业,下面是同一平台中提供的一个非常简单和基本的wordcount示例。 根据这一点,GCP要求服务号具有数据流工作者的权限,以便执行我的作业。即使我已经设置了所需的权限,错误仍然出现时,堰部分会出现: 有人能解释这种奇怪的行为吗?太感谢了
-
管理帐户数据 若要使用此机能,可能需先更新系统软件。 可确认或变更进入PlayStation®Network时建立的帐户数据。 仅能于已登入PlayStation®Network时操作。请进入(PlayStation®Netrowk)并选择(管理账户)。 可确认/变更的项目 账户管理 可确认/变更帐户数据。 信用卡数据 登入ID(电子邮件地址) 密码 姓名 地址 个人造型 个人资料 通知邮件设定
-
我们有一个将文件复制到Azure文件服务器的外部源。文件大小约为10GB。我想在Azure文件服务器上使用Azure Data Factory完成文件复制后,立即将此文件复制到Azure Blob存储。供应商无法将此文件复制到Blob容器。有人能帮我配置什么类型的触发器吗。我可以手动复制,但我正在寻找是否可以实现自动化。我甚至不能安排这个活动,因为来自外部源的文件副本是随机的。 谢谢
-
我需要访问两个数据源: Spring批处理存储库:在内存H2中 我的步骤需要访问。 我在那里看到了几个关于如何创建自定义
-
我的数据库中有大约1000万个blob格式的文件,我需要转换并以pdf格式保存它们。每个文件大小约为0.5-10mb,组合文件大小约为20 TB。我正在尝试使用spring批处理实现该功能。然而,我的问题是,当我运行批处理时,服务器内存是否可以容纳那么多的数据?我正在尝试使用基于块的处理和线程池任务执行器。请建议运行作业的最佳方法是否可以在更短的时间内处理如此多的数据
-
我是新的Azure数据工厂v2 我有一个文件夹,里面有两个文件。csv和F2。在blob存储中存储csv。 我创建了一个复制数据管道活动,用3个参数将数据从文件加载到azure DWH中的一个表中,并将其递归复制为false。 参数1:容器 参数2:目录 参数3:F1.csv 将上述参数用于复制数据活动时成功执行。 但数据是从两个文件加载的,只有一个文件作为活动的参数提供