
Spark-Java-插入到Oracle数组列类型时,无法获取数组的JDBC类型

我在Oracle中有一个列为Array类型的表。当向Oracle插入数据框时,我收到了一个异常。
请注意,这个问题不是关于我应该加入“,”并将其作为字符串值存储在VARCHAR2 type列中。
下面是我如何创建这个表。
CREATE OR REPLACE TYPE dbObj_arr IS VARRAY (5) OF varchar2(6);
CREATE TABLE MyTable (
"ID" NUMBER,
"Set" dbObj_arr );
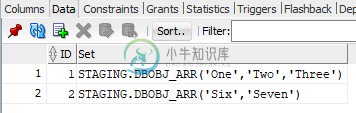
INSERT INTO MyTable ( ID, "Set" ) VALUES ( 1, dbObj_arr ('One', 'Two', 'Three') );
INSERT INTO MyTable ( ID, "Set" ) VALUES ( 2, dbObj_arr ('Six', 'Seven') );
下面是数据在表中的存储方式。
例外
+---+---------------+
|Id |CSV |
+---+---------------+
|1 |One, Two, Three|
|2 |Six, Seven |
+---+---------------+
root
|-- Id: integer (nullable = false)
|-- CSV: string (nullable = true)
+---+-----------------+
|Id |Set |
+---+-----------------+
|1 |[One, Two, Three]|
|2 |[Six, Seven] |
+---+-----------------+
root
|-- Id: integer (nullable = false)
|-- Set: array (nullable = true)
| |-- element: string (containsNull = true)
21/02/25 16:42:26 WARN JdbcUtils: Requested isolation level 1 is not supported; falling back to default isolation level 2
21/02/25 16:42:26 WARN JdbcUtils: Requested isolation level 1 is not supported; falling back to default isolation level 2
21/02/25 16:42:26 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.IllegalArgumentException: Can't get JDBC type for array<string>
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$getJdbcType$2(JdbcUtils.scala:188)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.getJdbcType(JdbcUtils.scala:188)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$savePartition$5(JdbcUtils.scala:663)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$savePartition$5$adapted(JdbcUtils.scala:663)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:198)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.savePartition(JdbcUtils.scala:663)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$saveTable$1(JdbcUtils.scala:858)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$saveTable$1$adapted(JdbcUtils.scala:856)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2(RDD.scala:994)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2$adapted(RDD.scala:994)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2139)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:446)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:449)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
21/02/25 16:42:26 ERROR Executor: Exception in task 1.0 in stage 0.0 (TID 1)
示例代码
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import static org.apache.spark.sql.functions.col;
import static org.apache.spark.sql.functions.split;
public class SampleArrayApp implements Serializable {
private static final long serialVersionUID = -1L;
private static String DbFormat = "jdbc";
private static String DbUrl = "jdbc:oracle:thin:@oved1070.vmpc1.cloud.boeing.com:53620:BBLFSDEV";
private static String DbUser = "STAGING";
private static String DbPassword = "St@Ging";
private static String DbDriver = "oracle.jdbc.OracleDriver";
private static String DbTable = "MyTable";
private static String ID = "Id";
private static String CSV = "CSV";
private static String SET = "Set";
public static void main(String[] args) {
SampleArrayApp app = new SampleArrayApp();
app.start();
}
private void start() {
Logger.getLogger("org.apache").setLevel(Level.WARN);
SparkSession spark = SparkSession
.builder()
.appName("Spark App")
.master("local[*]")
.getOrCreate();
StructType structType = new StructType();
structType = structType.add(ID, DataTypes.IntegerType, false);
structType = structType.add(CSV, DataTypes.StringType, true);
List<Row> list = new ArrayList<Row>();
list.add(RowFactory.create(1, "One, Two, Three"));
list.add(RowFactory.create(2, "Six, Seven"));
Dataset<Row> df = spark.createDataFrame(list, structType);
df.show(10, false);
df.printSchema();
Dataset<Row> resultDf = df
.withColumn(SET, split(col(CSV), ", "))
.drop(col(CSV));
resultDf.show(10, false);
resultDf.printSchema();
performInsert(resultDf);
}
private void performInsert(Dataset<Row> df) {
Properties props = new Properties();
props.setProperty("user", DbUser);
props.setProperty("password", DbPassword);
props.setProperty("driver", DbDriver);
df.write()
.mode(SaveMode.Append)
.jdbc(DbUrl, DbTable, props);
}
}
共有1个答案

没有数据帧API。然而,我们可以迭代每一行并手动插入它们——这很慢,而且不是最优的。
private void insert(Dataset<Row> df) {
df.coalesce(df.javaRDD().getNumPartitions())
.foreachPartition(new ForeachPartitionFunction<Row>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Iterator<Row> t) throws Exception {
Properties props = new Properties();
props.setProperty("user", "USERNAME");
props.setProperty("password", "PASSWORD");
props.setProperty("driver", "jdbc");
Connection conn = null;
Statement stmt = null;
int batchSize = BATCH_SIZE;
try {
DriverManager.registerDriver(new oracle.jdbc.driver.OracleDriver());
conn = DriverManager.getConnection("URL", props);
stmt = conn.createStatement();
int currentBatchSize = 0;
while (t.hasNext()) {
Row row = t.next();
String id = row.getAs(ID).toString();
String names = row.getAs(NAMES).toString(); // Comma separated names
String sql = "DECLARE names EFFOBJ := EFFOBJ(" + names + "); "
+ "BEGIN INSERT INTO TABLENAME (ID, NAMES) "
+ "VALUES (" + id + ", names); END;";
stmt.addBatch(sql);
currentBatchSize++;
if (!t.hasNext() || currentBatchSize == 5000) {
stmt.executeBatch();
currentBatchSize = 0;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (stmt != null)
stmt.close();
if (conn != null)
conn.close();
}
}
});
}
-
问题内容: 如果我有 我怎样才能从? 如果我这样做,那我就代替了。 问题答案: 组件类型 用这个: 返回表示数组的组件类型的信息。如果此类不表示数组类,则此方法返回。 参考: 安全/不安全铸造 有没有一种方法可以从getComponentType()返回的Class强制转换为Class,而不会收到编译器警告? 采取这种方法: 这是生成的字节码: 如您所见,参数类型被擦除为Object [],因此编
-
问题内容: 我有一个包含TEXT等数组的复合类型。我在主表中使用它来创建复合类型的数组。 如何生成INSERT命令(不使用复合类型的默认字段名称)?我可以使用复合数组创建一个TEMPORARY TABLE,然后将其插入主表吗? 例如: 第一个INSERT失败,并显示以下消息: 错误:INSERT具有比目标列更多的表达式。 有或没有array []构造都失败。 我的实际使用情况要复杂得多,因为该复合
-
我试着做一个ArrayList,包含另一个类的对象,一个名字,还有turn。类似于python字典的东西。 所以我做了一个有三个值的类。 我试图在主类的构造函数中调用它,如下所示: 但它引发了一个错误:无法推断ArrayList的类型参数
-
是否同时初始化一个空数组? 此空数组是否缓存在JVM中? 它们对某个数组-类-对象进行操作吗? 它们在字节码级别上相同吗? 注意:它可能是以某种方式写在JLS中的,但我在任何地方都找不到合适的描述。
-
我有我的目标: 我已将一些人添加到数组中: 我想要所有的名字在一个单独的数组,但我不想这样做...还有别的办法吗?
-
我目前有一个表会话和一个列操作(JSONB)。 我能够使用正确地将数组从前端存储到数据库。 我的数组(数组值)的结构如下所示: 与我在SO上看到的许多关于修改JSONB或访问某些键的问题不同,我只对将整个JSONB数据转换回前端的数组感兴趣。 我的临时修复是通过数组进行映射,并使用Javascript中的json.parse()来重组数组中的每个对象。我不能对整个数组使用json.parse(),