
我怎样才能对Kafka消费者进行规模?

我正在阅读Kafka的文档,注意到下面一行:
但是,请注意,使用者组中的使用者实例不能多于分区。
嗯。如何自动缩放?

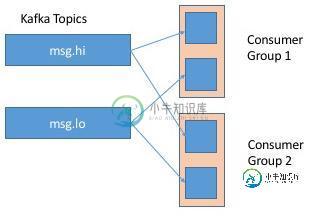
这是Kafka的限制但是...如果我理解这是如何工作的,那么两个用户组都将从一个分区(例如msg.hi)中提取,并使用它们自己的偏移量,因此两个用户组都不知道另一个分区--这意味着消息可能会被传递两次!
我怎样才能达到我在兔子设计中所拥有的Kafka的能力,并且仍然保持行为的“队列性”(我不想发送两次消息)?我错过了什么?
共有1个答案

只需为hi和LO创建一堆分区。12是个好数字。60岁也是。只需选择与所需的最大并行化程度相匹配的多个分区。
老实说,虽然我个人希望msg.hi和msg.lo完全是不同的主题,但这并不是一个要求--您可以执行自定义parititoning来在分区之间划分消息。
-
问题内容: 这是一个简单的ArrayList排序程序: 我期望该程序的输出为: 但是当我运行该程序时,我得到的输出为: 为什么会这样?如何使ArrayList进行排序,如预期输出所示? 问题答案: 您可以编写一个自定义比较器:
-
我刚接触Kafka,很少阅读教程。我无法理解使用者和分区之间的关系。 请回答我下面的问题。 > 消费者是否由ZK分配到单个分区,如果是,如果生产者将消息发送到不同的分区,那么其他分区的消费者将如何使用该消息? 我有一个主题,它有3个分区。我发布消息,它会转到P0。我有5个消费者(不同的消费者群体)。所有消费者都会阅读P0的信息吗?若我增加了许多消费者,他们会从相同的P0中阅读信息吗?如果所有消费者
-
我正在使用收集用户输入,当用户按下指示输入完成时,我希望取消屏幕键盘。 如何使键盘自动消失?
-
Flink kafka消费者有两种类型的消费者,例如: 这两个消费者层次结构扩展了相同的类。我想知道维护编号类背后的设计决策是什么?我们什么时候应该使用其中一种? 我注意到带有数字后缀的类有更多的特性(例如ratelimiting)。 https://github.com/apache/flink/blob/master/flink-connectors/flink-connector-kafka
-
是否有一种方法以编程方式访问和打印使用者滞后偏移,或者说使用者读取的最后一条记录的偏移与某个生产者写入该使用者分区的最后一条记录的偏移之间的位置差。 要知道我的最终目标是将这个值发送到prometheus进行监视,我应该在上面添加哪些语句来得到滞后偏移值?
-
我目前正在探索Kafka,作为一个简单问题的初学者。 将有一个生产者向一个主题推送消息,但将有n个spark应用程序的消费者从kafka发送消息并插入到数据库中(每个消费者插入到不同的表中)。 是否有可能消费者会不同步(例如消费者的某些部分会停机很长一段时间),然后一个或多个消费者不会处理消息并插入到表中? 假设代码总是正确的,在按摩数据时不会出现异常。重要的是每条消息只处理一次。 我的问题是,K