
Google Dataflow-Apache Beam GroupByKey():复制/慢速

我在beam.groupbykey()中遇到了一个情况,我加载了一个行数为42.854行的文件。
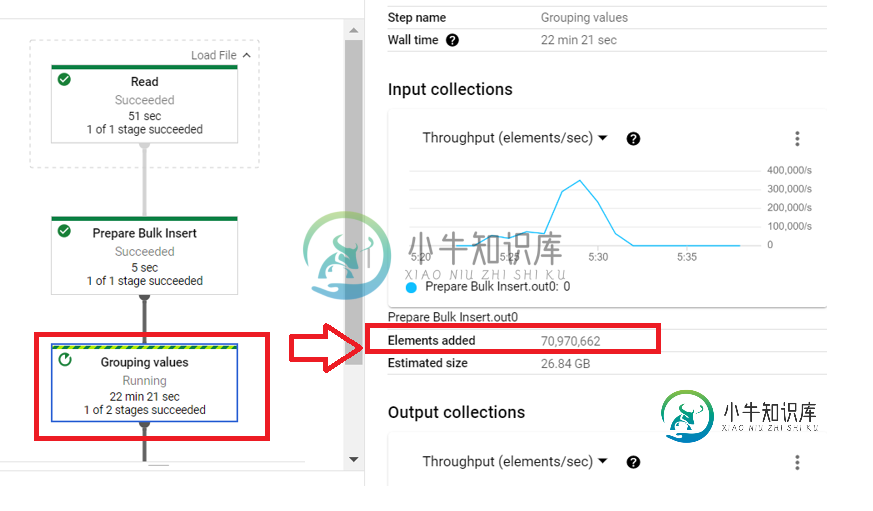
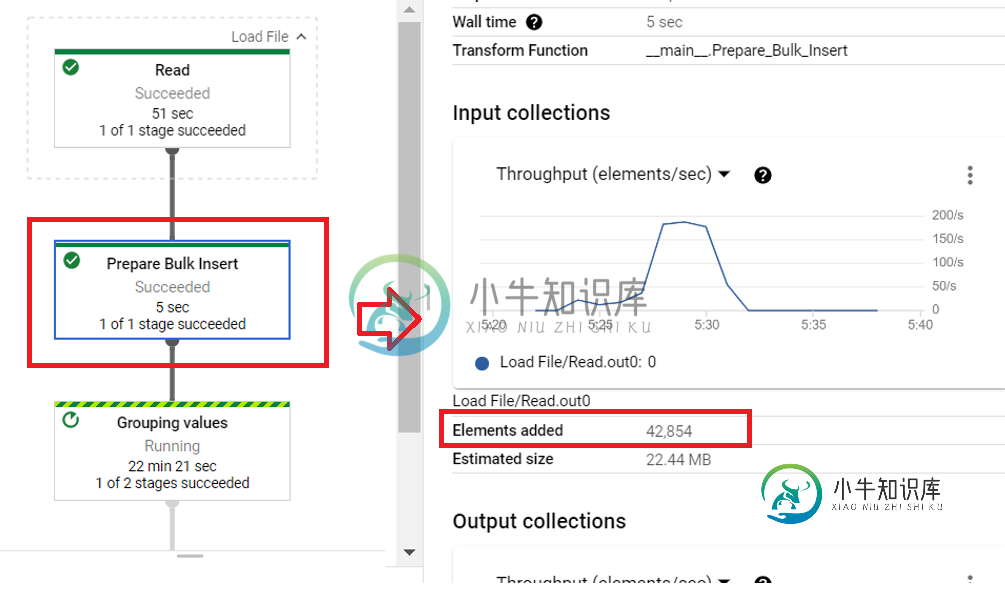
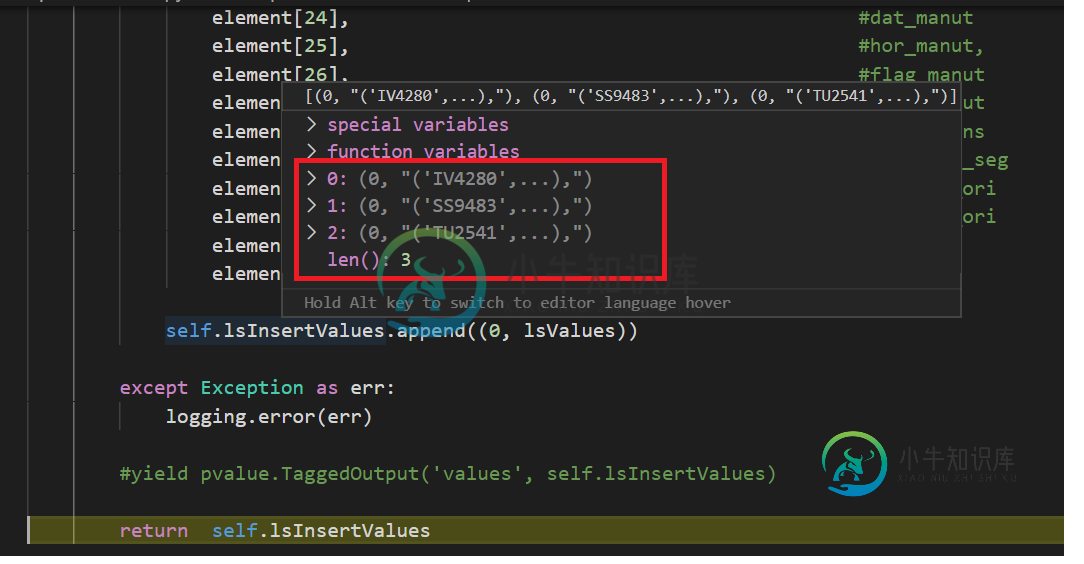
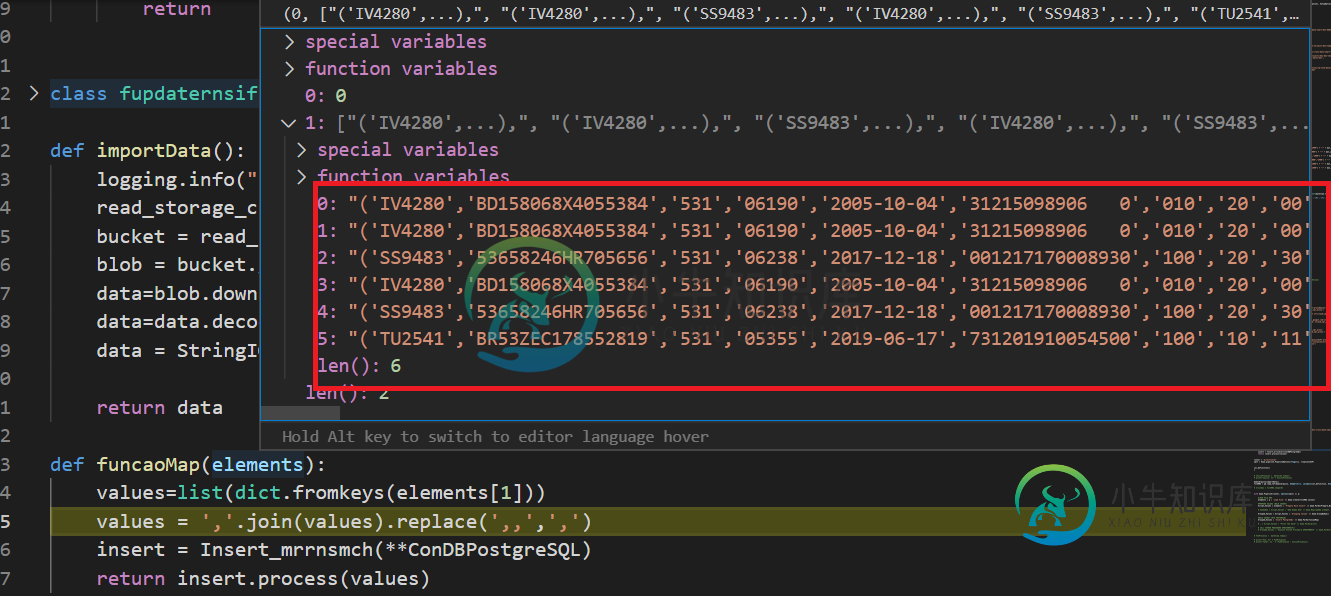
由于业务规则,我需要执行一个GroupByKey();然而,在完成它的执行后,我注意到我得到了几乎双行。如下所示:
GroupByKey()之前的步骤:
with beam.Pipeline(runner, options=opts) as p:
#LOAD FILE
elements = p | 'Load File' >> beam.Create(fileRNS.values)
#PREPARE VALUES (BULK INSERT)
Script_Values = elements | 'Prepare Bulk Insert' >> beam.ParDo(Prepare_Bulk_Insert())
Grouped_Values = Script_Values | 'Grouping values' >> beam.GroupByKey()
#BULK INSERT INTO POSTGRESQL
Grouped_Values | 'Insert PostgreSQL' >> beam.ParDo(ExecuteInsert)
向你问好,朱利亚诺·梅德罗斯
共有1个答案

这些截图表明“Prepare Bulk Insert”DoFn在每个输入元素输出一个以上的元素。第一个截图显示了GBK的输入PCollection(由DoFn生成),第二个是DoFn的输入,因此差异必须由该DoFn生成。
-
我有一个nslayout约束,当用户按下按钮时,该约束应该会慢慢达到零。目前,当按下按钮时,它会自动快速达到零。我的代码不起作用。在这里。
-
我正在开发一个应用程序,需要使用QT(5.6.1)将大量文件从一个文件夹复制到另一个文件夹 为此,我一直在使用方法。这工作得很好,除了一件事:它非常慢。使用Windows资源管理器进行相同复制操作所需的时间是其两倍多。 想知道为什么会这样,我深入研究了QT源代码,在,看起来很相关: 据我所知,复制操作使用的是4096字节的缓冲区。这对于复制操作来说非常小,很可能是问题的原因。因此,我所做的是将缓冲
-
不知道为什么,模拟器无论切换界面还是动画都变得很慢,但是输入,很正常,没有慢。 尝试-1 我重新启动Xcode和模拟器,但没有任何效果。
-
问题内容: 我正在尝试使用将大文件(> 1 GB)从硬盘复制到USB驱动器。一个描述我正在尝试做的简单脚本是: 在Linux上只需要2-3分钟。但是在Windows下,同一文件上的同一文件副本要花费10-15分钟以上的时间。有人可以解释为什么并给出一些解决方案,最好使用python代码吗? 更新1 将文件另存为test.pySource文件大小为1 GB。目的地目录位于USB驱动器中。使用ptim
-
问题内容: 我正在VMWare下的SSD上用Node复制文件,但是性能很低。我已经用来衡量实际速度的基准测试如下: 但是,以下用于复制文件的节点代码非常慢,因此随后的运行不会使其速度更快: 运行方式为: 这里有什么问题,我该如何加快速度?我相信我可以通过调整缓冲区大小来更快地用C编写它。让我感到困惑的是,当我编写简单的几乎等同于pv的程序时,如下所示将stdin传递到stdout,它的速度非常快。
-
我们有一台摄像机,记录高FPS率-163的视频。 谢谢!