
这个社交媒体平台PostgreSQL数据库设计对吗?

这里是一个简单的社交媒体平台的持久性设计。目前有以下表:
- users:数据库的主表,包含在应用程序中注册的用户的信息。将存储在此表中的数据将是
- 名称:用户
- 字段:id、姓名、用户名、密码、电子邮件、个人信息、关注者、关注者、图片。
- 主键:ID
- 名称:posts
- 字段:id、标题、图片、说明、内容、created_at、likes、user_id。
- 主键:ID
- 外键:表用户的user_id
-
null
-
null
CREATE TABLE users( id SERIAL PRIMARY KEY, name VARCHAR (50) NOT NULL, username VARCHAR (50) UNIQUE NOT NULL, password VARCHAR (255) NOT NULL, email VARCHAR (255) NOT NULL, bio VARCHAR (255) NOT NULL, followers INTEGER NOT NULL, following INTEGER NOT NULL, picture VARCHAR (255) NOT NULL ) CREATE TABLE posts( id SERIAL PRIMARY KEY, title VARCHAR (255) NOT NULL, picture VARCHAR (255) NOT NULL, description VARCHAR (255) NOT NULL, content TEXT NOT NULL, created_at TIMESTAMP NOT NULL DEFAULT NOW(), likes INTEGER NOT NULL, user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE ) CREATE TABLE posts_liked_users( post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE, user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE ) CREATE TABLE follows( following_user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE, followed_user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE )下面是图表:
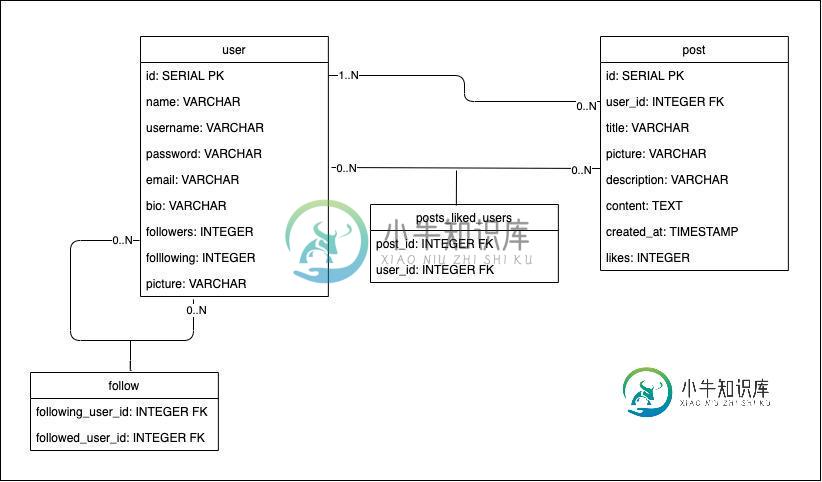
图和整体设计对不对,还是缺了什么?
共有1个答案

作为对任何有类似问题的人的回答,我根据一些建议和研究重构了设计:
>
我将varchar字段更新为text,这是通用指南。
由于规范化,我从users中删除了followers和follows并从post中删除了liked以减少数据冗余并提高数据完整性。
我在follows和posts_liked_users上添加了一个created_at字段,以保留用户跟踪另一个或喜欢一篇文章的时间。
CREATE TABLE users(
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
username TEXT UNIQUE NOT NULL,
password TEXT NOT NULL,
email TEXT NOT NULL,
bio TEXT NOT NULL,
picture TEXT NOT NULL
)
CREATE TABLE posts(
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
picture TEXT NOT NULL,
description TEXT NOT NULL,
content TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE
)
CREATE TABLE posts_liked_users(
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE,
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE
)
CREATE TABLE follows(
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
following_user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
followed_user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE
)
参考资料:
>
来自https://www.reddit.com/r/postgresql/comments/h87gf8/is_this_social_media_platform_postgresql_database/的评论
使用数据类型“text”存储字符串有什么缺点吗?
https://en.wikipedia.org/wiki/database_normalization
-
我想创建一个应用程序,包括rss提要或你可能会看到instagram或facebook的提要。我目前正在尝试使用firebase实时数据库或firestore作为后端来存储显示给用户的帖子。我似乎想不出一个办法来实现这一点。理想的解决方案是按时间顺序发送帖子列表,而不需要对客户端进行任何额外排序。当我尝试使用实时数据库时,我可以轻松地将所有相关帖子添加到它们自己的路径中,并在客户端对它们进行排序(
-
我正在尝试为一个简单的社交媒体概念创建一个简单的云Firestore数据库结构。 每个用户最多可以有一个可以随时更新的帖子(一个“最喜欢的”帖子除外)。用户“最喜欢的”版本的帖子被保存为一个单独的帖子,当用户在其当前版本的帖子上收到比最喜欢的版本更多的赞时,该帖子可以被更新。 friends子集合存储好友用户名,因此很容易按用户名创建该用户的好友列表。我假设我可以通过将朋友的documentID与
-
因此,我想创建一种社交媒体应用程序,并使用fiRest作为主数据库。 目标是创建“facebook”新闻源。 每个用户都有一个朋友列表,每个用户都可以创建帖子。 每个帖子都可以被修改为对应用程序的所有用户或用户朋友可见。所以每个用户都可以向他所有的朋友发布帖子,并向应用程序中的每个人发布帖子。 此外,用户还可以在新闻提要中“保存”他们喜欢的帖子。(类似帖子子集合) 现在在用户的新闻提要中-我如何查
-
我试图为自己创建一个使用DynamoDB的简单应用程序。我从未在高级级别上使用过非关系型数据库,只是在这里和那里存储一个值。 该应用程序是一个记录器。我将记录一些东西,迪纳摩将记录日期并计算一天。 例如,一个用户今天记录多件事情,它只会说今天的日期和记录的时间:5 然后,我可以进行查询,以获取过去一周/一天/一个月内所有logged_times的总和。 我的问题是如何构造一个NoSQL数据库来完成
-
我有一个集合,我的应用程序在其中存储用户的所有帖子,数据结构如下: 现在,我想向我的用户显示这个集合的所有帖子;但是,只有当用户跟随创建帖子的人时,即帖子文档的字段适合。 我知道如果用户只关注一个人,查询集合是很简单的,也就是说,我有一个简单的子句。但是:如果我的用户关注10,000人或更多人呢?我怎么查询呢? 另外,我应该如何存储,即用户跟随的人?使用简单的数组似乎不适合我,但是使用所有其他选项
-
考虑instagram提要场景。我想让我关注的人“发布”所有帖子。对于每一个帖子,我都想知道我是否喜欢它,还想知道我关注的其他人中有谁喜欢它(如果有的话)。在gremlin中实现这一点的最佳解决方案是什么(可能避免重复)? 图像清晰 下面只给出了用户2“发布”的帖子。如何在同一查询中获取其他信息?