
依赖于上下文的ANTLR4语义谓词不起作用

我正在用这个缩放的语法解析一个类似C++的声明(删除了许多细节,使其成为一个完全可用的示例)。它不能神秘地工作(至少对我来说)。它是否与上下文相关谓词的使用有关?如果是,如何实现“计算子节点数逻辑”?
grammar CPPProcessor;
cppCompilationUnit : decl_specifier_seq? init_declarator* ';' EOF;
init_declarator: declarator initializer?;
declarator: identifier;
initializer: '=0';
decl_specifier_seq
locals [int cnt=0]
@init { $cnt=0; }
: decl_specifier+ ;
decl_specifier : @init { System.out.println($decl_specifier_seq::cnt); }
'const'
| {$decl_specifier_seq::cnt < 1}? type_specifier {$decl_specifier_seq::cnt += 1;} ;
type_specifier: identifier ;
identifier:IDENTIFIER;
CRLF: '\r'? '\n' -> channel(2);
WS: [ \t\f]+ -> channel(1);
IDENTIFIER:[_a-zA-Z] [0-9_a-zA-Z]* ;
我需要实现标准的C++规则,即在decl_specifier_seq下不允许超过1个type_specifier。
在type_specifier之前使用语义谓词似乎是解决方案。由于嵌套的decl_specifier_seq是可能的,因此计数自然被声明为decl_specifier_seq中的局部变量。
int t=0;
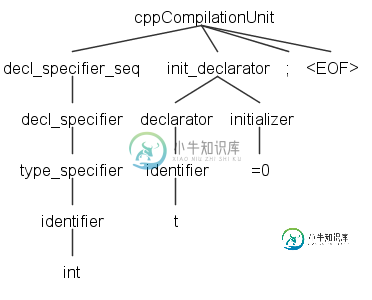
但是,一个不带'=0'的输入来帮助解析
int t;
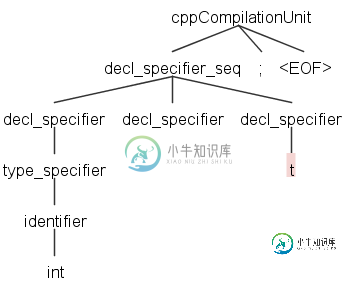
0
1
line 1:4 no viable alternative at input 't'
1
分析失败,出现“No Valible Alternative”错误(控制台中打印的数字是$DECL_SPECHIER_CNT::CNT值的调试打印,作为测试条件的验证)。也就是说,语义谓词不能阻止t被解析为type_specifier,并且t不再被视为init_declarator。这里有什么问题?是否因为使用了具有$decl_specifier_seq::cnt的上下文相关谓词?
这是否意味着上下文相关谓词不能用于实现“计算子节点数量”逻辑?
....
@parser::members {
public int cnt=0;
}
decl_specifier
@init {System.out.println("cnt:"+cnt); }
:
'const'
| {cnt<1 }? type_specifier {cnt++;} ;
一个奇怪的结果是,如果我在谓词后面添加/*$CTX*/,它将再次失败:
decl_specifier
@init {System.out.println("cnt:"+cnt); }
:
'const'
| {cnt<1 /*$ctx*/ }? type_specifier {cnt++;} ;
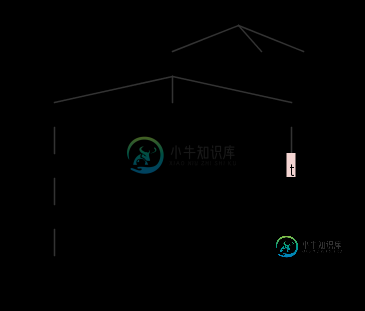
line 1:4 no viable alternative at input 't'
解析失败,没有可行的替代方案。为什么/*$CTX*/导致解析失败,就像使用$DECL_SPECHIER_SEQ::CNT时一样,尽管实际逻辑只使用成员变量?而且,如果没有/*$CTX*/,就会出现另一个与@init块之前调用的谓词有关的问题(在这里描述)
共有1个答案

ANTLR4在两种情况下评估语义谓词。
- 生成的代码在解析期间计算语义谓词,并抛出一个异常,该异常返回false。解析过程中遍历的所有谓词都以这种方式计算,包括上下文相关的谓词和不出现在决策左侧的谓词。
- 预测方法对谓词进行评估,以便在解析过程中做出正确的决策。在这种情况下,如果谓词出现在被求值的决策的左边缘以外的任何地方,则假定谓词返回true(即忽略它们)。此外,仅在上下文数据可用时才计算上下文相关谓词。预测算法将不会创建解析代码尚未提供的上下文结构。如果在预测过程中遇到依赖于上下文的谓词,并且没有可用的上下文,则假定该谓词返回true(即对于该决策忽略它)。
代码生成器不计算目标语言的语义,因此当$ctx出现在/*$ctx*/中时,它无法知道$ctx在语义上是无关的。这两种情况都导致谓词被视为上下文相关的。
-
我有一个非常简单的语法,如下所示: (我需要使用语义谓词,因为我需要解析关键字可以用作标识符的语言)。 参考:https://github.com/antlr/antlr4/blob/master/doc/predicates.md
-
关于antlr4的几个问题使用了书中没有提到的lexer谓词,例如28730446使用了head(String),42058127使用了getCharPositionInLine(),23465358使用了_input.la(1)等。是否有可用的lexer谓词列表及其文档?
-
本文向大家介绍ANTLR 动作和语义谓词,包括了ANTLR 动作和语义谓词的使用技巧和注意事项,需要的朋友参考一下 示例 词法分析器操作是目标语言中由{...包围的任意代码块,该代码}在匹配期间执行: 语义谓词是目标语言中由{...包围的任意代码块}?,其结果为布尔值。如果返回的值为false,则跳过词法分析器规则。 出于性能原因,应尽可能在规则末尾定义语义谓词。
-
我正在研究一种上下文敏感的语法。下面是它的描述: 它描述表达式集。 每个表达式包含一个或多个由逻辑运算符分隔的部分。 每个部分由可选字段标识符组成,后面跟着一些比较运算符(也是可选的)和值列表。 值也用逻辑运算符分隔。 默认值为字符序列。有时(取决于上下文)可以扩展每个值的可能字符集。它甚至可以使用比较运算符(根据第三条规则,用于从值列表中分离字段标识符)来将其视为值的字符。 以下是语法的简化版本