
尝试使用C#Regular Express匹配文本文件中的特定模式和模式序列

我对我的C#有点生疏,我正试图找出一个在SSIS中使用的简单脚本,该脚本将梳理文本文件,并基于特定的模式集和所述模式的特定序列提取值。
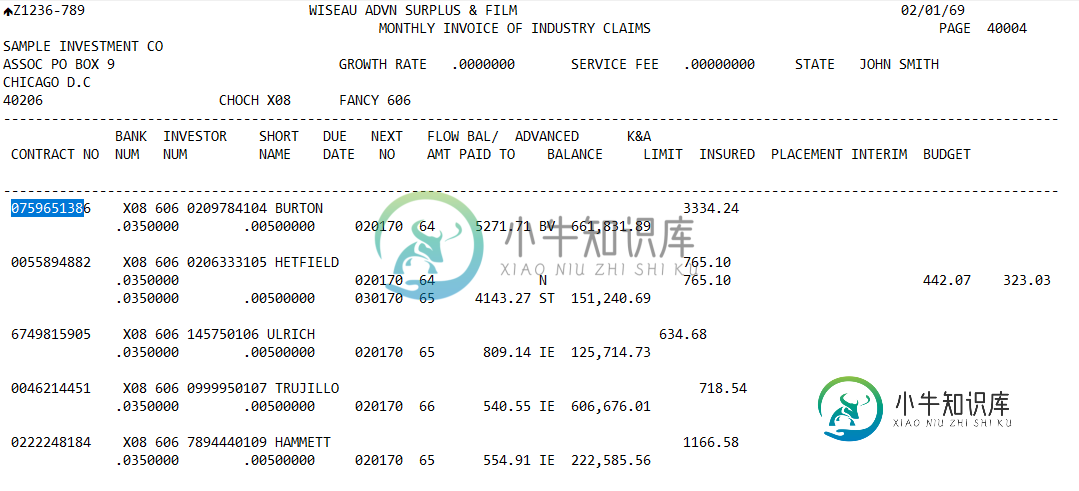
我需要指定来自此文本输入的值的各个行,以传递到文本文件作为输出。因此合同号、银行号等是头部,每一行都是文件中的包装值。我只需要能够梳理和ID行以获得输出,并认为正则表达式可以完成这一任务,但我不确定如何将类似的内容放在一起。是否可以通过查找特定序列中的值模式来标识每一行?
即。
Pattern1 = [0-9] {9} for contract num
Pattern2 = [a-z][0-9] {6} for bank num
谢了。
示例文本
共有1个答案

您正在处理的文件似乎是固定宽度的;无论谁编写了生成这个文件的程序,他都是通过每个字段的位置来传达每个字段的含义。因此,您的程序最好按照传递信息的方式使用信息,根据数据的位置而不是匹配特定正则表达式的能力来解释数据。也就是说,正则表达式将是在数据解析后验证数据的一个很好的方法。
为了处理这类数据,我可能会构建一个表示单个记录的类,并为其提供解析和验证的方法。我很快就想到了一些东西:
public class DetailRecord
{
private readonly string _originalText;
static private Dictionary<string, Func<string,string>> _map = new Dictionary<string, Func<string,string>>
{
{ "ContractNo", s => s.Substring( 1 ,10 ) },
{ "BankNum", s => s.Substring( 15 , 8 ) },
{ "ShortName", s => s.Substring( 35 ,10 ).Trim() }
};
public DetailRecord(string originalText)
{
_originalText = originalText;
}
public string this[string key]
{
get
{
return _map[key](_originalText);
}
}
public string BankNum
{
get { return this["BankNum"]; }
}
public string ContractNo
{
get { return this["ContractNo"]; }
}
public string ShortName
{
get { return this["ShortName"]; }
}
public bool IsValid
{
get
{
int dummy;
if (!int.TryParse(this.ContractNo, out dummy)) return false;
if (!Regex.IsMatch(this.BankNum, @"[A-Z]\d\d\s\s\d\d\d")) return false;
return true;
}
}
}
您会注意到这个类保留了一个静态字典(_map),其中包含解析每个字段的函数列表。
public class Program
{
public static void Main()
{
var input = " 0759651386 X08 606 0209784104 BURTON 3334.24";
var line = new DetailRecord(input);
if (line.IsValid)
{
Console.WriteLine("Contract number: '{0}'", line.ContractNo);
Console.WriteLine("Bank number: '{0}'", line.BankNum);
Console.WriteLine("Short name: '{0}'", line.ShortName);
}
}
}
Contract number: '0759651386'
Bank number: 'X08 606'
Short name: 'BURTON'
查看我在DotNetFiddle上的代码
-
dir=“某物”\temp。 我是新来的,任何帮助都很感激。我认为这是字符转义…但我不确定,我想使用正则表达式,但我想我会遇到同样的问题。 预期 C:\\users\\admin\\appdata\\local\\ dir=c:\\users\\admin\\appdata\\local\\temp
-
类似定位器参数,文本模式是另一种常用的 Selenium 命令参数。需要使用文本模式的命令,例如:verifyTextPresent, verifyTitle, verifyAlert, assertConfirmation, verifyText, verifyPrompt。上面已经提到,LinkText 定位器可使用文本模式。文本模式使用特殊字符来模糊匹配预期的文本,而不必准确的描述该文本。
-
问题内容: 我想以特定的模式匹配插入文件内容。以下是一个示例:在和之间添加内容。 我尝试了以下操作,但没有成功。 问题答案: 尝试以下命令: 它产生: 编辑 以解释命令为何无法按需运行:该命令在当前循环的末尾或读取下一个输入行时添加其内容。而且您正在使用的命令不会打印任何内容,但会读取下一行,因此在那时打印,然后再打印正常的行。 在我的情况下,它以读取行,然后结束循环,因此打印行及其后的文件内容并
-
通配符 # glob_asterisk.py import glob for name in sorted(glob.glob('dir/*')): print(name) # glob_subdir.py import glob print('Named explicitly:') for name in sorted(glob.glob('dir/subdir/*')):
-
问题内容: 我有一个类似… 的正则表达式模式,我需要搜索成千上万个文件(大小从1KB到24 MB不等)以成千上万个文件(介于100到8000之间)。 我想知道是否有比我尝试过的模式匹配更快的方法。 环境: 杰克1.8 Windows 10 Unix4j库 这是我到目前为止尝试过的 我明白了,这让我觉得我做错了什么。 我对流使用了不同的方法,平均每种方法需要大约一分钟的时间来处理当前的6660个文件
-
问题内容: 我在包含一些文本的文本文件中有字符串,如下所示: 我希望在类名之前获取所有内容。 我已经尝试了以下方法,但是我不知道该如何摆脱 我得到以下信息: 而不是我想要的: 关于如何解决此问题的任何指示? 问题答案: 如果不使用捕获组,则可以使用超前(业务)。 应该捕获您想要的一切。这里是细分的: