
如何在pyspark数据帧中将字符串类型的列转换为int形式?

我在Pyspark有dataframe。它的一些数值列包含'nan',所以当我读取数据并检查dataframe的模式时,这些列将具有'string'类型。我如何将它们更改为int类型。我用0替换了'nan'值,并再次检查了模式,但它也显示了这些列的字符串类型。我遵循下面的代码:
data_df = sqlContext.read.format("csv").load('data.csv',header=True, inferSchema="true")
data_df.printSchema()
data_df = data_df.fillna(0)
data_df.printSchema()
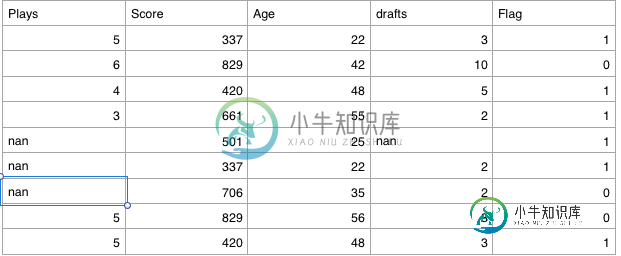
这里的列“Plays”和“Drafts”包含整数值,但由于这些列中存在nan,它们被视为字符串类型。
共有1个答案

from pyspark.sql.types import IntegerType
data_df = data_df.withColumn("Plays", data_df["Plays"].cast(IntegerType()))
data_df = data_df.withColumn("drafts", data_df["drafts"].cast(IntegerType()))
您可以为每个列运行循环,但这是将字符串列转换为整数的最简单方法。
-
本文向大家介绍如何将R数据帧中的字符串转换为NA?,包括了如何将R数据帧中的字符串转换为NA?的使用技巧和注意事项,需要的朋友参考一下 我们经常会在数据收集过程中发现错误,这些错误可能会导致研究结果不正确。当错误地收集数据时,将使分析师的工作变得困难。显示数据有错误的一种情况是获取字符串代替数字值。因此,我们需要将这些字符串转换为R中的NA,以便我们可以进行预期的分析。 示例 请看以下数据帧- 将
-
我想将String转换为子类数据类型,如何才能做到?或者这是可能的? 我有一个抽象类帐户 公共抽象类SinAcct扩展了Acct 一个公共类SavAcct扩展了SinAcct 在SavAcct中,有一个构造函数 一个抽象类合并帐户扩展帐户 我想要一个新的SavAcct, 新的SavAcct(数组[1],数组[2],数组[3],Double.parse双(数组[4]) 但它是错误的构造函数SavAc
-
问题内容: 我想将下面的字符串变量转换为spark上的dataframe。 我知道如何从json文件创建数据帧。 但是我不知道如何从字符串变量创建数据框。 如何将json字符串变量转换为dataframe。 问题答案: 对于Spark 2.2+: 对于Spark 2.1.x: 提示:这是使用重载。它也可以直接读取Json文件。 对于旧版本:
-
我正在Spark 3.0.0上执行Spark结构流的示例,为此,我使用了twitter数据。我在Kafka中推送了twitter数据,单个记录如下所示 2020-07-21 10:48:19|1265200268284588034|RT@narendramodi:与@IBM首席执行官@ArvindKrishna先生进行了广泛的互动。我们讨论了几个与技术相关的主题,…|印度海得拉巴 在这里,每个字段
-
在从< code>RDD制作< code >数据帧时,我遇到了一个错误。 我收到以下错误: py spark . SQL . utils . parse exception:u " \ nmis matched input ' '应为{'SELECT ',' FROM ',' ADD ',' AS ',' ALL ',' DISTINCT ',' WHERE ',' GROUP ',' BY ',