
使用find_elements_by_class_name提取数据

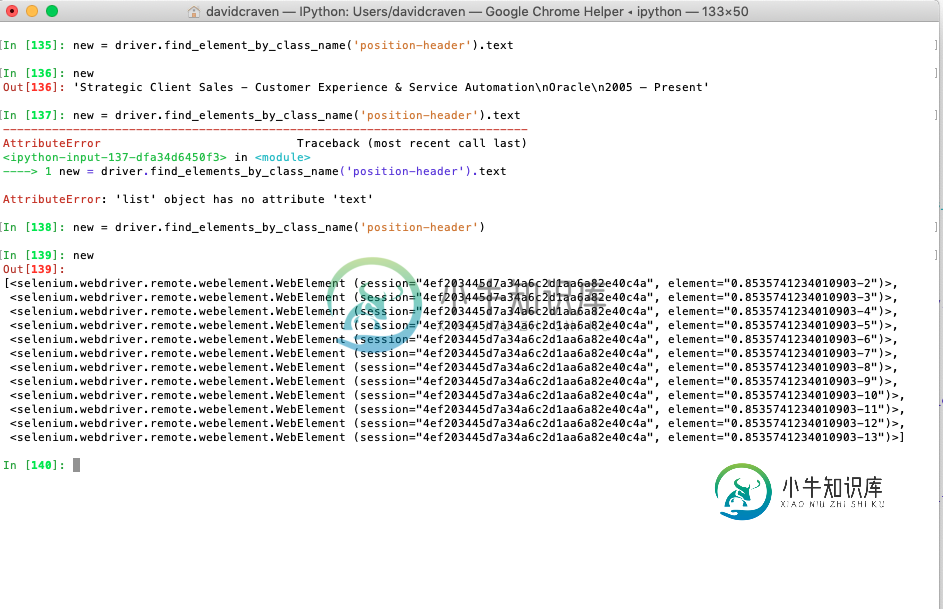
我试图使用find_elements_by_class_name提取页面上的每个class_name='position-header',但当我这样做时,我收到错误:
属性错误:“列表”对象没有属性“文本”
from parsel import Selector
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
employment = driver.find_elements_by_class_name('position-header')
屏幕截图显示,当使用find_element_by_class_name方法时,它返回数据,但当使用find_elements_by_class_name我遇到错误。
共有1个答案

驱动程序。find_elements_by_class_name()方法返回匹配元素的列表,您试图访问列表中不存在的<code>text
您可以选择第一个并访问 .text 属性:
driver.find_elements_by_class_name('position-header')[0].text
或者迭代列表并获取每个元素的 ext:
elements = driver.find_elements_by_class_name('position-header')
for element in elements:
print(element.text)
-
问题内容: 我正在尝试提取其中的任何数据。 例如,从此字符串提取的数据应为。 这是实际的代码: 但这行不通,知道吗? 问题答案: 您需要转义,并在正则表达式中。 Golang示范 在正则表达式中 您也可以使用
-
我有一个带有ID、TEXT等列的表,这里的TEXT是超文本标记语言FORMAT中包含数据的Clob列 样本数据: 当我使用Jsoup.parse(AUDIT_SCOPE_LOB.text()时;我得到的数据如下 我对java知之甚少。我可以使用jsoup获取java代码来提取数据并重新运行下面的outpu吗 实际上,这个数据是一个样本数据。我有一些带有html标记的数据,这里没有提到。
-
问题内容: 我的Python代码处理了以下文本: 您能建议我如何从内部提取数据吗?我的想法是将其放入具有以下格式的CSV文件中:。 我希望没有正则表达式会很困难,但实际上我仍然在反对正则表达式。 我或多或少地通过以下方式使用了代码: 理想情况下是将每个td竞争以某个数组进行竞争。上面的HTML是python的结果。 问题答案: 获取BeautifulSoup并使用它。这很棒。
-
我正在创建一个fetchBill函数。分配https://randomapi.com/api/006b08a801d82d0c9824dcfdfdfa3b3c到一个api变量。它使用浏览器的fetch函数向api发出HTTP请求。它在一个函数中使用箭头函数。然后调用fetch函数,并在将其转换为JSON后返回响应。使用另一个。然后调用第一个函数,该函数将JSON数据传递给displayCartTo
-
问题内容: 我想使用JSoup-framework提取此表,以将内容保存在“表”数组中。第一个tr-tag是表头。所有以下内容(不包括在内)均描述了内容。 我已经测试了这一个和其他一些,但是我没有让它们为我工作: 使用JSoup提取HTML表内容 问题答案: 这是一些示例代码,您如何仅选择标题: 你得到… 解析 文件 :(这里是和字符集,请参阅jsoup对铁道部的相关信息文件) 解析 网站 :(不
-
当我试图从在线URL=forexalgerie.com中的表中获取数据时,我的目标是这些值: ...似乎我的代码一切正常: 但是结果包含表中的所有内容,除了我想要的值? 怎么了?