
Apache Kafka关于合并云-分区主题和消费者滞后中的不相干偏移

我发现在合流云上使用Kafka时有一个奇怪的行为。我创建了一个主题,其分区值默认为6。
我的系统由一个Java Producer应用程序和一个Kafka Streams应用程序组成,前者向该主题发送一条消息,后者读取该主题并执行每个消息的操作。
----------------------- -------- -----------
| Kafka Java Producer | ----> | topic | ----> | KStream |
----------------------- -------- -----------
目前,我只启动了Kafka Streams应用程序的一个实例,因此consumer组只有一个成员。
-
null

events.foreach { key, value ->
logger.info("--------> Processing TimeMetric {}", value)
//Store in DB
日志
[-StreamThread-1]uration$$EnhancerBySpringCglib$$E72E3F00:---------->正在处理事件{“...

[-StreamThread-1]uration$$EnhancerBySpringCglib$$E72E3F00:---------->正在处理事件{
-
null
共有1个答案

对于第一个问题,有两种可能性(尽管通过阅读第二个问题,您似乎在使用事务):
>
如果您没有使用一次准确的语义,生产者可能会发送多个消息,因为在电线上无法控制之前发送的消息。这样,Kafka默认的至少一次语义可能会因为那些重复的消息而增加你的偏移量>+1。
如果您使用的是一次准确语义或事务,则事务的每个事件都会在主题中写入一个标记,以便进行内部控制。这些标记是+2增加的原因,因为它们也存储在主题中(但被使用者避免)。Confluent的交易指南也提供了一些关于这种行为的信息:
然后协调器开始第2阶段,将事务提交标记写入作为事务一部分的主题分区。
这些事务标记不向应用程序公开,而是由read_committed模式下的使用者用来从中止的事务中筛选出消息,并且不返回作为打开事务一部分的消息(即,那些在日志中但没有与之关联的事务标记的消息)。
一旦写入标记,事务协调器将事务标记为“完成”,生产者就可以开始下一个事务。
一般说来,你不应该关心偏移量,因为它不是一个确定的指南。例如,重试、重复或事务标记会使偏移量与您预期的生产者不同,但您不应为此担心;你的消费者会这样做的,他们只会处理“真实的”消息。
关于问题2,这是一个已知的问题:https://issues.apache.org/jira/browse/kafka-6607
引用JIRA:
希望有帮助!
-
假设我有一个名为“MyTopic”的主题,它有3个分区P0、P1和P2。这些分区中的每一个都有一个leader,并且本主题的数据(消息)分布在这些分区中。 1.Producer将始终根据代理上的负载以循环方式写到分区的领导者。对吗? 2.制作人如何认识隔断的首领?
-
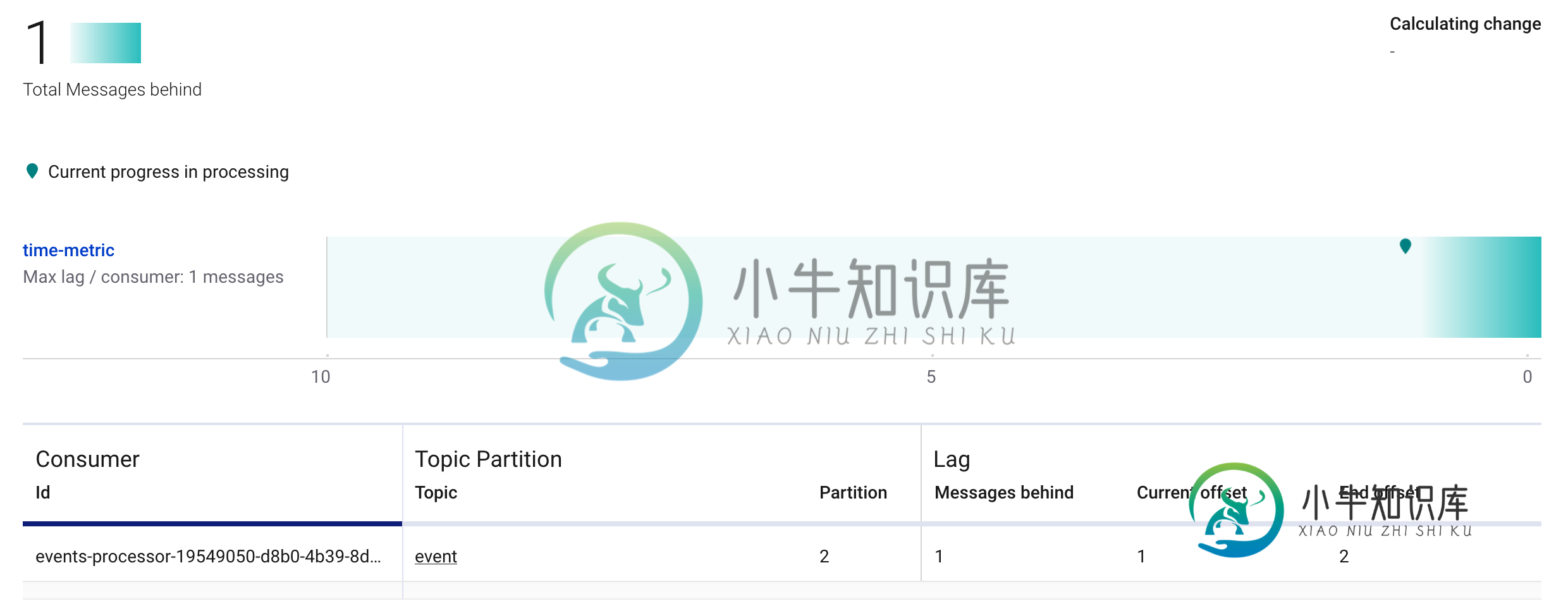
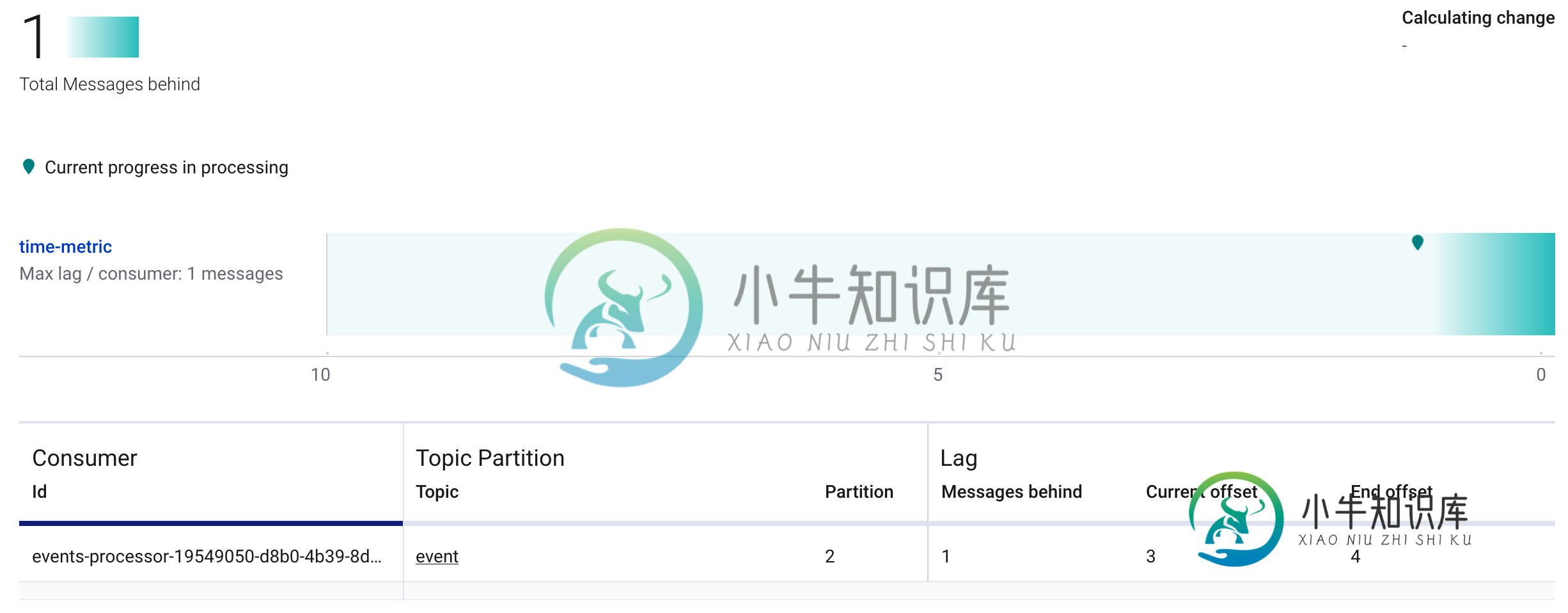
我想检查手动分配给特定主题的消费者组的滞后,这可能吗。我使用的是Kafka-0.10.0.1。我用的是shKafka跑步课。shKafka。管理ConsumerGroupCommand-new consumer-description-bootstrap server localhost:9092-group test但它说不存在组,所以我想知道当我们手动分配分区时,是否可以检查使用者的延迟。
-
是否有一种方法以编程方式访问和打印使用者滞后偏移,或者说使用者读取的最后一条记录的偏移与某个生产者写入该使用者分区的最后一条记录的偏移之间的位置差。 要知道我的最终目标是将这个值发送到prometheus进行监视,我应该在上面添加哪些语句来得到滞后偏移值?
-
现在,让我们考虑另一个场景(我没有尝试过,但我很好奇),在这个场景中,我启动了两个使用者进程和,这两个进程都具有相同的组,并且它们都是一个单线程进程。现在我的问题是: > 在这种情况下,两个独立的使用者进程(在同一个组下)将如何与分区相关?与上面的单进程多线程场景有何不同? 一般来说,使用者线程或进程如何与主题中的分区映射/相关? 关于将消费者实现为进程与线程,我在这里遗漏了什么微妙的事情吗?提前
-
我有一个用例,其中数据将从kafkaTopic1流入程序(我们称之为P1),经过处理,然后持久化到数据库。P1将在一个多节点集群上,因此每个节点将处理大量的kafka分区(假设本主题有5个节点和50个kafka分区)。如果其中一个节点由于任何原因完全失败,并且有数据正在处理,那么该数据将丢失。 例如,如果kafkaTopic1上有500条消息,node2拉出了10条消息(因此根据偏移量要拉出的下一
-
我正在建立一个新的Kafka集群,为了测试目的,我创建了一个有1个分区和3个副本的主题。 有什么想法哪种配置或其他东西可以帮助我消费更多的数据吗?? 提前致谢