
使用Python从Newick格式提取分支长度

我有一个python列表,由一个以Newick格式编写的树组成,如下所示:
['(BMNH833953:0.16529463651919140688,(((BMNH833883:0.22945757727367316336,(BMNH724182a:0.18028180766761139897,(BMNH724182b:0.21469677818346077913,BMNH724082:0.54350916483644962085):0.00654573856803835914):0.04530853441176059537):0.02416511342888815264,(((BMNH794142:0.21236619242575086042,(BMNH743008:0.13421900772403019819,BMNH724591:0.14957653992840658219):0.02592135486124686958):0.02477670174791116522,BMNH703458a:0.22983459269245612444):0.00000328449424529074,BMNH703458b:0.29776257618061197086):0.09881729077887969892):0.02257522897558370684,BMNH833928:0.21599133163597591945):0.02365043128986757739,BMNH724053:0.16069861523756587274):0.0;']
在树格式中,显示如下:
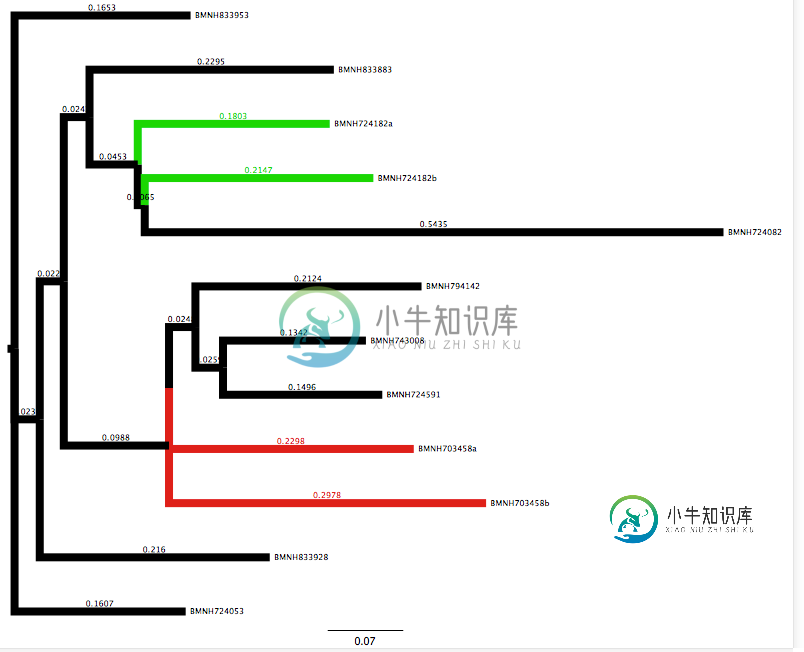
我试图写一些代码,将通过列表项,并返回ID(BMNHxxxxxx)这是加入分支长度为0(或
JustTree = []
with JustTree as f:
for match in re.finditer(r"(?<=Item\sA)(?:(?!Item\sB).){50,}", subject, re.I):
f.extend(match.group()+"\n")
取自另一个StackOverflow答案,其中A项将是':',因为分支长度总是出现在a之后:而B项将是'a'、'或')'或'a';',因为这是一个有三个字符来分隔它,但我不是有足够的正则表达式经验来做这件事。
在这种情况下,通过使用分支长度为0,我希望代码输出['BMNH703458a','BMNH703458b']。如果我可以改变这也包括ID的加入一个分支长度的用户定义的值,例如0.01,这将是非常有用的。
如果任何人有任何意见,或能给我一个有用的答案,我将不胜感激。
共有3个答案

有几个Python库支持newick格式。ETE工具包允许读取newick字符串,并将树作为Python对象进行操作:
from ete2 import Tree
tree = Tree(newickFile)
print tree
可以选择几个newick子格式,并解析分支距离,即使它们是用科学符号表示的。
from ete2 import Tree
tree = Tree("(A:3.4, (B:0.15E-10,C:0.0001):1.5E-234);")

我知道你的问题已经得到了回答,但是如果你想让你的数据成为一个嵌套列表而不是一个简单的字符串:
import re
import pprint
a="(BMNH833953:0.16529463651919140688,(((BMNH833883:0.22945757727367316336,(BMNH724182a:0.18028180766761139897,(BMNH724182b:0.21469677818346077913,BMNH724082:0.54350916483644962085):0.00654573856803835914):0.04530853441176059537):0.02416511342888815264,(((BMNH794142:0.21236619242575086042,(BMNH743008:0.13421900772403019819,BMNH724591:0.14957653992840658219):0.02592135486124686958):0.02477670174791116522,BMNH703458a:0.22983459269245612444):0.00000328449424529074,BMNH703458b:0.29776257618061197086):0.09881729077887969892):0.02257522897558370684,BMNH833928:0.21599133163597591945):0.02365043128986757739,BMNH724053:0.16069861523756587274):0.0;"
def tokenize(str):
for m in re.finditer(r"\(|\)|[\w.:]+", str):
yield m.group()
def make_nested_list(tok, L=None):
if L is None: L = []
while True:
try: t = tok.next()
except StopIteration: break
if t == "(": L.append(make_nested_list(tok))
elif t == ")": break
else:
i = t.find(":"); assert i != -1
if i == 0: L.append(float(t[1:]))
else: L.append([t[:i], float(t[i+1:])])
return L
L = make_nested_list(tokenize(a))
pprint.pprint(L)

好的,这里有一个只提取数字(可能是小数)的正则表达式:
\b[0-9]+(?:\.[0-9]+)?\b
\bs确保旁边的数字周围没有其他数字、字母或下划线。这叫做单词边界。
[0-9]匹配多个数字。
代码>(?:\.[0-9])?是一个可选的组,这意味着它可能匹配,也可能不匹配。如果第一个[0-9]后面有一个点和数字,那么它将匹配这些。否则,它不会。组本身匹配一个点,并且至少匹配1位数。
您可以将其与re一起使用。findall将所有匹配项放入列表:
import re
NewickTree = ['(BMNH833953:0.16529463651919140688,(((BMNH833883:0.22945757727367316336,(BMNH724182a:0.18028180766761139897,(BMNH724182b:0.21469677818346077913,BMNH724082:0.54350916483644962085):0.00654573856803835914):0.04530853441176059537):0.02416511342888815264,(((BMNH794142:0.21236619242575086042,(BMNH743008:0.13421900772403019819,BMNH724591:0.14957653992840658219):0.02592135486124686958):0.02477670174791116522,BMNH703458a:0.22983459269245612444):0.00000328449424529074,BMNH703458b:0.29776257618061197086):0.09881729077887969892):0.02257522897558370684,BMNH833928:0.21599133163597591945):0.02365043128986757739,BMNH724053:0.16069861523756587274):0.0;']
pattern = re.compile(r"\b[0-9]+(?:\.[0-9]+)?\b")
for tree in NewickTree:
branch_lengths = pattern.findall(tree)
# Do stuff to the list branch_lengths
print(branch_lengths)
对于此列表,您可以打印以下内容:
['0.16529463651919140688', '0.22945757727367316336', '0.18028180766761139897',
'0.21469677818346077913', '0.54350916483644962085', '0.00654573856803835914',
'0.04530853441176059537', '0.02416511342888815264', '0.21236619242575086042',
'0.13421900772403019819', '0.14957653992840658219', '0.02592135486124686958',
'0.02477670174791116522', '0.22983459269245612444', '0.00000328449424529074',
'0.29776257618061197086', '0.09881729077887969892', '0.02257522897558370684',
'0.21599133163597591945', '0.02365043128986757739', '0.16069861523756587274',
'0.0']
-
问题内容: 这里, 这里有张桌子。我的目标是提取表并将其保存到csv文件。我写了一个代码: 我从这里迷路了。有人可以帮忙吗?谢谢! 问题答案: 因此,本质上您想解析出文件以获取文件中的元素。您可以将BeautifulSoup或lxml用于此任务。 您已经有使用的解决方案。我将使用发布解决方案:
-
问题内容: 我必须将 算法从Excel工作表移植到python代码, 但必须对 Excel文件中的算法 进行 反向工程 。 Excel工作表非常复杂,它包含许多单元格,在这些单元格中有引用其他单元格的公式(也可以包含公式或常数)。 我的想法是使用python脚本分析工作表,以构建一种单元格之间的依存关系表,即: A1取决于B4,C5,E7公式:“ = sqrt(B4)+ C5 * E7” A2取决
-
问题内容: 我有这个示例xml文件 我喜欢提取标题标签和内容标签的内容。 使用模式匹配或使用xml模块,哪种方法最适合提取数据。还是有更好的方法来提取数据。 问题答案: 特别是已经有一个内置的XML库。例如:
-
问题内容: 我的Python代码处理了以下文本: 您能建议我如何从内部提取数据吗?我的想法是将其放入具有以下格式的CSV文件中:。 我希望没有正则表达式会很困难,但实际上我仍然在反对正则表达式。 我或多或少地通过以下方式使用了代码: 理想情况下是将每个td竞争以某个数组进行竞争。上面的HTML是python的结果。 问题答案: 获取BeautifulSoup并使用它。这很棒。
-
问题内容: 我一直在尝试仅从JSON文件中提取某些数据。我设法将JSON解码并将所需的数据放入python dict中。当我打印出字典时,它会显示所有所需的数据,但是当我尝试将字典写入新文件时,只会写入最后一个对象。我不明白的一件事也是为什么当我打印字典时会得到多个字典对象而不是我期望的1。 我的代码: 我的json.json文件: 打印my_dict输出: 在文件test.json中输出: 我也
-
问题内容: 我想在API中提供自动字符串格式,例如: 可以替换为格式化字符串中标注的属性值。 如何从Python格式字符串中提取关键字参数: 问题答案: 您可以使用类的一个字符串,解析出的领域,与方法: 演示: 您可以进一步解析这些字段名称。为此,您可以使用方法(Python 2)/函数(Python 3)(此内部实现细节未公开;在内部使用)。此函数返回名称的 第一部分 ,将在传递给的参数中查找该