
无法理解在外部合并排序中如何将更大的块数据加载到RAM中

今天我的朋友问我:
编写一个程序来对列表中的数百万个元素进行排序,但内存大小非常小。它不能容纳超过100个元素。
我从维基百科文章链接中读到了关于外部合并排序的内容:
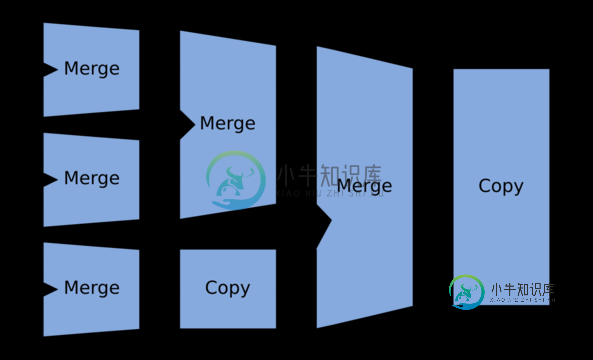
您必须在合并数据的同时执行某种排序,对吗?这个问题可能听起来很愚蠢,但我无法理解,如果有人能帮助我,我将不胜感激。
共有1个答案

我的困惑现在消除了:
如果看到pseudo formerge sort,如果存储了这两个列表,那么合并它们只需要O(1)个时间。您可以看到,Merge只需要O(1)内存来合并两个排序的列表,即使排序的列表存储在外部存储器中--它不需要将输入列表全部加载到内存中。
如果在列表排序后看到merge sort链接的可视化,那么这一切都是关于合并的,我们现在不需要任何临时空间。
-
目前正在用Daniel Liang的C++入门自学C++。 关于合并排序的话题,我似乎无法理解他的代码是如何递归调用自己的。 我理解合并排序的一般概念,但我很难具体理解这段代码。 在本例中,我们首先将列表1,7,3,4,9,3,3,1,2及其大小(9)传递给mergeSort函数。从那里,我们将列表一分为二,直到数组大小达到1。在这种情况下,我们会得到:1,7,3,4->1,7->1。然后我们进入
-
我在理解外部排序算法中的合并步骤时遇到了一定的困难。我在维基百科上看到了这个例子,但我无法理解。 外部排序的一个例子是外部合并排序算法,它对每个适合RAM的块进行排序,然后将排序后的块合并在一起。例如,对于仅使用100 MB RAM对900 MB数据进行排序:1)读取主内存中的100 MB数据,并通过一些常规方法进行排序,如快速排序。2) 将排序后的数据写入磁盘。3) 重复第1步和第2步,直到所有
-
我在理解合并排序算法的“合并”部分时有点困难,因为我试图在上下文中理解算法的部分,而某些变量/循环对我来说没有意义。我理解递归除法过程和合并的排序方面,但在这个特定的合并算法中: 我不明白最后3个循环: 你能解释一下这3个循环在合并的上下文中是用来做什么的吗?还有什么进一步的建议可以帮助你更好地理解合并排序算法的合并部分吗?
-
我正在尝试理解外部合并排序算法是如何工作的(我看到了相同问题的一些答案,但没有找到我需要的东西)。我正在阅读Jeffrey McConnell的《算法分析》一书,我正在尝试实现那里描述的算法。 例如,我有输入数据:,我只能将4个数字加载到内存中。 我的第一步是以4个数字块读取输入文件,在内存中对它们进行排序,然后将其中一个写入文件A和文件B。 我得到: 现在我的问题是,如果这些文件中的块不适合内存
-
问题内容: 我目前正在尝试将以下大的制表符分隔的文件导入Python中类似数据框的结构中-自然,我正在使用数据框,尽管我愿意接受其他选择。 该文件大小为几GB,不是标准文件,它已损坏,即行的列数不同。一排可能有25列,另一排可能有21列。 这是数据示例: 如您所见,其中某些列的顺序不正确… 现在,我认为将文件导入数据框的正确方法是对数据进行预处理,以便可以输出带有值的数据框,例如 更复杂的是,这是
-
这些是家庭作业问题,但我想了解它们背后的概念,而不仅仅是得到答案。 我知道MergeSort的运行时间是O(nlogn)。似乎合并方法必须运行 n 次(因为它必须合并所有数组,最终会有 n 个数组)。因此,我想我可以推断出 MergeSort() 方法将被称为 logn times。我也认为这是有道理的,因为它正在划分数组,所以它会一直将自己除以 2,所以 logn。 因此,我觉得答案分别是C和A