
在eclipse中为2.4.1 hadoop映射Reduce客户端JAR

当我在shell中的hadoop文件夹中运行我的Hadoop mapreduce word count JAR时,它正在正常运行并且正确生成输出,
由于我在Hadoop 2.4.1的情况下使用了Yarn,所以当我从eclipse运行MapReduce示例程序时,MAP进程已完成,但在reduce进程中失败。
很明显,问题出在jar配置上。
请找到罐子,我已经加了...
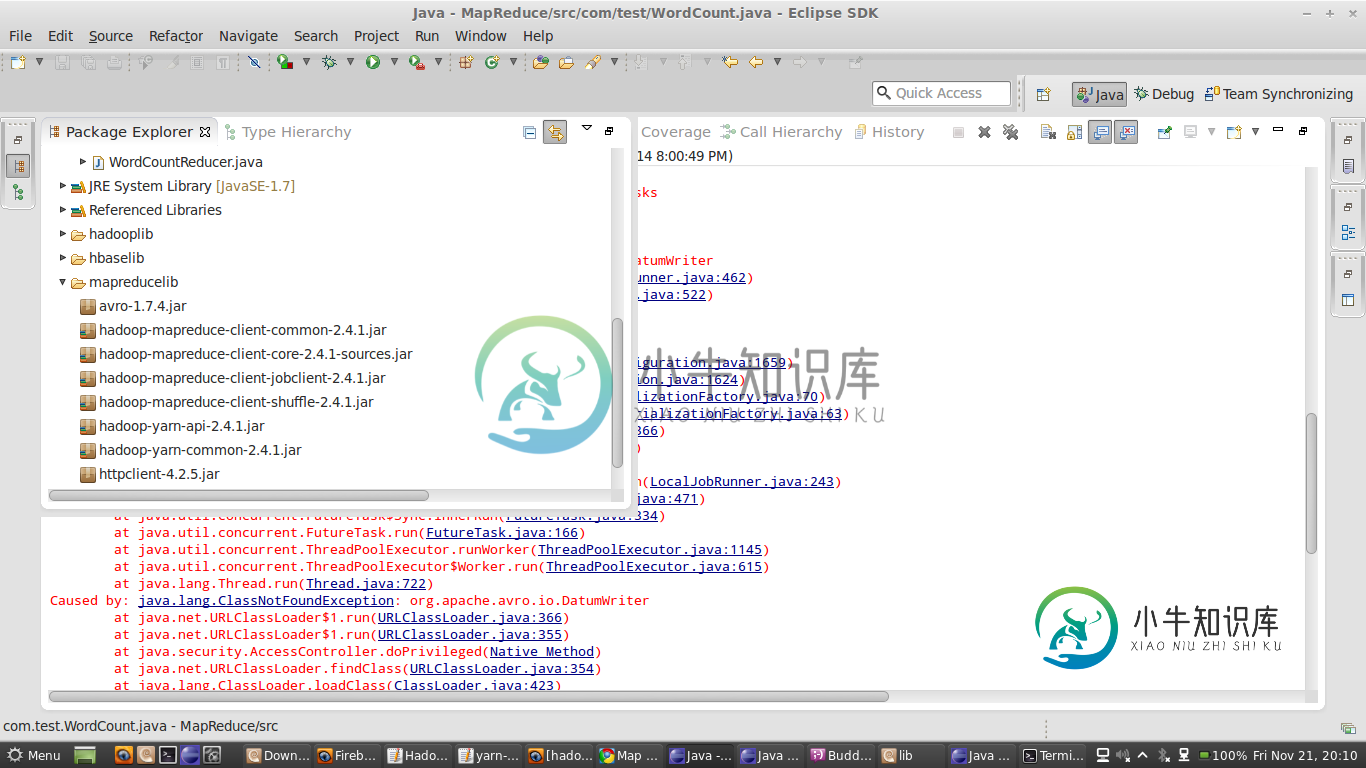
这是我的错误
信息:减少任务执行者完成。Nov 21 2014年8:50:35 PM org.apache.hadoop.mapred.localjobrunner$job run警告:job_local1638918104_0001 java.lang.exception:java.lang.nosuchmethoder错误:org.apache.hadoop.mapred.reducetask.setlocalmapfiles(ljava/util/map;)V在org.apache.hadoop.mapred.localjobrunner$job.runtasks(localjobrunner.java:462)在)
线程“Thread-12”java.lang.noClassDeffounder中的异常错误:org/apache/commons/httpclient/httpmethod在org.apache.hadoop.mapred.localjobrunner$job.run(localjobrunner.java:562)由:java.lang.classnotfoundexception:org.apache.commons.httpclient.httpmethod在java.net.urlClassLoader$1运行(urlClassLoader.java:366)在java.net.urlClassLoader$1运行
共有1个答案

根据屏幕截图,您正在手动将所有依赖的JAR添加到类路径中。强烈建议使用maven来实现这一点,这将使向类路径添加依赖JAR的过程自动化。我们只需要添加主要的依赖JAR。
我在pom.xml中使用了以下依赖项,这帮助我运行起来没有任何问题。
<properties>
<hadoop.version>2.5.2</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-nodemanager</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-resourcemanager</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
对于您的问题,我检查了类路径,正好有82个可用的jar文件。
像这样查找每个jar将是一项繁琐的工作。
您可以在这里添加函数式的jar。
其他的解决方法是,将安装的hadoop目录路径中的所有jar文件添加为
并从所有的lib文件夹中添加所有jar。这是你能做的最好的事情..或者
只添加avro特定的JAR,因为根据屏幕截图,avro类抛出的异常。这可以解决avro jars问题。但您可能会面临其他依赖关系问题。我在使用HadoopV1时也面临同样的问题。所以后来我意识到并使用Maven和HadoopV2。因此不必担心依赖JAR。
您的重点将放在Hadoop和业务需求上。:)
希望对您有帮助..
-
问题内容: 在我的文件中,我尝试实现一些映射,其中使用不同的分析器将属于一种类型的一个字段索引到其余字段。 目前,yaml文件具有以下结构: 这不会将自定义分析器应用于标题字段,因此我希望有人可以为我指出将自定义分析器应用于各个字段的正确方向? 问题答案: 我在ml中回答了这个问题: 如果您使用的是Java,则不必使用yml文件。您可以,但不必。 如果您使用的是Spring,则可以查看ES spr
-
java.util.concurrent.executionException:java.lang.ClassCastException:com.hazelCast.mapreduce.aggregation.impl.DistrictValuesAggregation$SimpleEntry不能在com.hazelCast.mapreduce.impl.task.trackableJobFutu
-
我正在尝试创建一个类,该类将通过Rest高级客户机自动写入ElasticSearch,并执行操作(create、createBatch、remove、removeBatch、update、updateBatch),这些操作都正常工作,我的测试用例都成功。为了增加一点灵活性,我想实现以下方法:(find、findAll、getFirsts(n)、getLasts(n))。find(key)和find
-
在本文中你将了解到如何在互联网上访问家里Windows 7电脑 前提 正常使用蜻蜓映射内网穿透软件需要以下步骤: 注册帐号 下载Windows客户端 场景 内网有一台服务器A的地址为: 192.168.1.100, 蜻蜓映射内网穿透通过以下步骤实现在互联网上远程访问服务器A 1. 在服务器A上安装客户端 进入蜻蜓映射下载页面,点击"免费下载"按钮,下载客户端后,安装即可。 2. 在服务器A上开启远
-
我需要安装eclipse市场。我使用Eclipse版本,这是与ADT捆绑为Android开发附带。我不知道它是开普勒、朱诺还是其他什么。 下面的链接中提到了去帮助→安装新软件→切换到开普勒存储库→通用工具→市场客户端 但是没有“切换到开普勒” 如何在Eclipse经典中安装Eclipse Marketplace? 我也尝试从这个链接安装:http://download.eclipse.org/mp
-
下面是我们在生产中遇到的问题的描述。请注意,我无法在测试或本地环境中再现该问题,因此无法向您提供测试代码。 我们有一个hazelcast集群,有两个成员M1、M2和三个客户端C1、C2、C3。Hazelcast版本为3.9。 客户端使用IMap。tryLock()方法,超时10秒。获得锁后,将执行关键和长时间运行的操作,最后使用IMap释放锁。unlock()方法。 生产中出现的问题如下: 在某个