
带Spark的Geohash NEO4j图

我使用的是Neo4J/Cypher,我的数据大约是200GB,所以我想到了可伸缩的解决方案“Spark”。
使用spark制作neo4j图形有两种解决方案:
1)Apache Spark密码(CAPS)
Nodes: (just id, no properties)
id
0
1
2
Relationships: (just the mandatory fields)
id | start | end
0 | 0 | 1
1 | 0 | 2
>
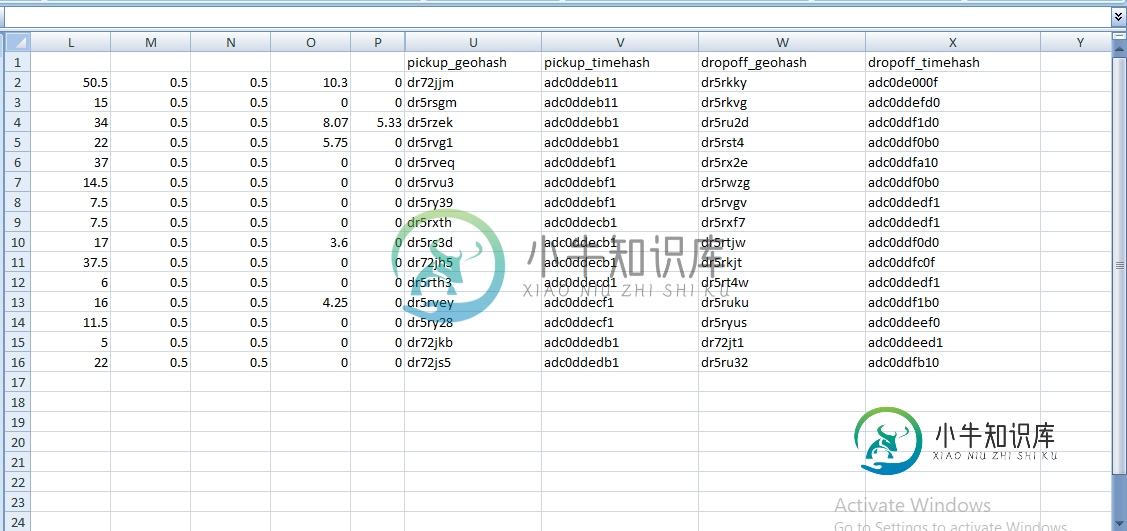
拾取数据
丢弃数据帧和
行程数据帧
package org.opencypher.spark.examples
import org.opencypher.spark.api.CAPSSession
import org.opencypher.spark.api.io.{CAPSNodeTable, CAPSRelationshipTable}
import org.opencypher.spark.util.ConsoleApp
import java.net.URI
import org.opencypher.okapi.api.io.conversion.NodeMapping
import org.opencypher.okapi.api.io.conversion.RelationshipMapping
import org.opencypher.spark.api.io.neo4j.Neo4jPropertyGraphDataSource
import org.opencypher.spark.api.io.neo4j.Neo4jConfig
import org.apache.spark.sql.functions._
import org.opencypher.okapi.api.graph.GraphName
object GreenCabsInputDataFrames extends ConsoleApp {
//1) Create CAPS session and retrieve Spark session
implicit val session: CAPSSession = CAPSSession.local()
val spark = session.sparkSession
//2) Load a csv into dataframe
val df=spark.read.csv("C:\\Users\\Ahmed\\Desktop\\green_result\\green_data.csv").select("_c0","_c3","_c4","_c9","_c10","_c11","_c12","_c13","_c14","_c15","_c16","_c17","_c18","_c19","_c20","_c21","_c22","_c23")
//3) cache the dataframe
val df1=df.cache()
//4) subset the dataframe
val pickup_dataframe=df1.select("_c0","_c3","_c4","_c9","_c10","_c11","_c12","_c13","_c14","_c15","_c16","_c17","_c18","_c19","_c20","_c21")
val dropoff_dataframe=df1.select("_c22","_c23")
//5) uncache the dataframe
df1.unpersist()
//6) add id columns to pickup , dropoff and trip dataframes
val pickup_dataframe2= pickup_dataframe.withColumn("id1",monotonically_increasing_id+pickup_dataframe.count()).select("id1",pickup_dataframe.columns:_*)
val dropoff_dataframe2= dropoff_dataframe.withColumn("id2",monotonically_increasing_id+pickup_dataframe2.count()+pickup_dataframe.count()).select("id2",dropoff_dataframe.columns:_*)
//7) create the relationship "trip" is dataframe
val trip_data_dataframe2=pickup_dataframe2.withColumn("idj",monotonically_increasing_id).join(dropoff_dataframe2.withColumn("idj",monotonically_increasing_id),"idj")
//drop unnecessary columns
val pickup_dataframe3=pickup_dataframe2.drop("_c0","_c3","_c4","_c9","_c10","_c11","_c12","_c13","_c14","_c15","_c16","_c17","_c18","_c19")
val trip_data_dataframe3=trip_data_dataframe2.drop("_c20","_c21","_c22","_c23")
//8) reordering the columns of trip dataframe
val trip_data_dataframe4=trip_data_dataframe3.select("idj", "id1", "id2", "_c0", "_c10", "_c11", "_c12", "_c13", "_c14", "_c15", "_c16", "_c17", "_c18", "_c19", "_c3", "_c4","_c9")
//8.1)displaying dataframes in console
pickup_dataframe3.show()
dropoff_dataframe2.show()
trip_data_dataframe4.show()
//9) mapping the columns
val Pickup_mapping=NodeMapping.withSourceIdKey("id1").withImpliedLabel("HashNode").withPropertyKeys("_c21","_c20")
val Dropoff_mapping=NodeMapping.withSourceIdKey("id2").withImpliedLabel("HashNode").withPropertyKeys("_c23","_c22")
val Trip_mapping=RelationshipMapping.withSourceIdKey("idj").withSourceStartNodeKey("id1").withSourceEndNodeKey("id2").withRelType("TRIP").withPropertyKeys("_c0","_c3","_c4","_c9","_c10","_c11","_c12","_c13","_c14","_c15","_c16","_c17","_c18","_c19")
//10) create tables
val Pickup_Table2 = CAPSNodeTable(Pickup_mapping, pickup_dataframe3)
val Dropoff_Table = CAPSNodeTable(Dropoff_mapping, dropoff_dataframe2)
val Trip_Table = CAPSRelationshipTable(Trip_mapping,trip_data_dataframe4)
//11) Create graph
val graph = session.readFrom(Pickup_Table2,Dropoff_Table, Trip_Table)
//12) Connect to Neo4j
val boltWriteURI: URI = new URI("bolt://localhost:7687")
val neo4jWriteConfig: Neo4jConfig = new Neo4jConfig(boltWriteURI, "neo4j", Some("wakarimashta"), true)
val neo4jResult: Neo4jPropertyGraphDataSource = new Neo4jPropertyGraphDataSource(neo4jWriteConfig)(session)
//13) Store graph in neo4j
val neo4jResultName: GraphName = new GraphName("neo4jgraphs151")
neo4jResult.store(neo4jResultName, graph)
}
共有1个答案

你是对的,CAPS就像Spark一样,是一个不变的系统。但是,使用CAPS,您可以在Cypher语句中创建新的图:https://github.com/opencypher/cypher-for-apache-spark/blob/master/spark-cypher-examples/src/main/scala/org/opencypher/spark/example/multiplegraphexample.scala
目前,construct子句对merge的支持有限。它只允许将已经绑定的节点添加到新创建的图中,而每个绑定的节点只添加一次,与它在绑定表中出现的次数无关。
考虑以下查询:
MATCH (n), (m)
CONSTRUCT
CREATE (n), (m)
RETURN GRAPH
为了解决这个问题,您可以使用两种方法:a)在创建图之前已经删除重复数据,b)使用密码查询。方法b)如下所示:
// assuming that graph is the graph created at step 11
session.catalog.store("inputGraph", graph)
session.cypher("""
CATALOG CREATE GRAPH temp {
FROM GRAPH session.inputGraph
MATCH (n)
WITH DISTINCT n.a AS a, n.b as b
CONSTRUCT
CREATE (:HashNode {a: a, b as b})
RETURN GRAPH
}
""".stripMargin)
val mergeGraph = session.cypher("""
FROM GRAPH inputGraph
MATCH (from)-[via]->(to)
FROM GRAPH temp
MATCH (n), (m)
WHERE from.a = n.a AND from.b = n.b AND to.a = m.a AND to.b = m.b
CONSTRUCT
CREATE (n)-[COPY OF via]->(m)
RETURN GRAPH
""".stripMargin).graph
注意:使用bot pickup和dropoff节点的属性名(例如a和b)
-
我们正在运行火花流来获得Kafka的饲料。现在我们正在尝试使用Phoenix JDBC从HBase中提取一些数据。当我在本地运行代码时,它运行良好,没有任何问题,但当我使用yarn-cluster运行它时,它会抛出异常。 下面是代码片段: 添加的SBT依赖项为 我手动检查了丢失的类,它在凤凰核心罐子中。纱线/火花抛出异常背后的原因是什么。Spark 1.3.1ClassNotFoundExcept
-
我已经将kafka代理从0.8升级到0.11,现在我正在尝试升级火花流作业代码以与新的kafka兼容-我正在使用火花1.6.2-。 我搜索了很多步骤来执行此升级,我没有找到任何官方或非官方的文章。 我发现唯一有用的文章是这篇,但是它提到了spark 2.2和kafka 0.10,但是我得到一行文字说 但是,由于较新的集成使用新的 Kafka 使用者 API 而不是简单的 API,因此在用法上存在显
-
问题内容: 请看下面的场景:一个Spark应用程序(Java实现)正在使用Cassandra数据库加载,转换为RDD并处理数据。该应用程序还从数据库中提取新数据,这些新数据也由自定义接收器处理。流处理的输出存储在数据库中。该实现使用了与数据库集成中的Spring Data Cassandra。 CassandraConfig: DataProcessor.main方法: 预计在初始加载时会有大量数
-
Java 1.8.0_151 Spark 2.2.1 Scala 2.11 卡桑德拉3.11.1
-
问题内容: 我编写了一个pyspark脚本,该脚本读取两个json文件,然后将它们发送到elasticsearch集群。当我在本地运行该文件时,一切都会正常运行(大部分情况下),我下载了和类的jar文件,然后使用pyspark使用参数运行我的工作,并且可以看到在我的Elasticsearch集群中出现的文档。 但是,当我尝试在Spark群集上运行它时,出现此错误: 在我看来,这很清楚:工人无法使用
-
问题内容: 问题:给定一个时间序列数据(即用户活动的点击流)存储在配置单元中,要求使用Spark使用会话ID丰富数据。 会话定义 闲置1小时后,工作阶段将终止 会话保持活动状态,总计2个小时 数据: 以下是仅考虑会话定义中第一点的部分解决方案: 实际输出: 为了包括第二个条件,我试图找出当前时间与上次会话开始时间之间的差异,以检查该时间是否超过了2小时,但是对于接下来的行,引用本身会发生变化。这些