
DAG在RDD中是如何工作的?

共有1个答案

甚至我也一直在web上寻找了解spark如何从RDD中计算DAG并随后执行任务。
在高层,当在RDD上调用任何操作时,Spark创建DAG并将其提交给DAG调度器。
>
DAG调度程序将操作符划分为任务阶段。阶段由基于输入数据分区的任务组成。DAG调度器将运算符管道在一起。例如,许多地图操作符可以在一个阶段中被调度。DAG调度器的最终结果是一组阶段。
狭义转换--不需要在分区之间洗牌数据。例如,映射,过滤等。
广泛转换--要求数据被洗牌,例如reduceByKey等。
让我们举一个例子,计算在每个严重级别上出现多少日志消息,
INFO I'm Info message
WARN I'm a Warn message
INFO I'm another Info message
val input = sc.textFile("log.txt")
val splitedLines = input.map(line => line.split(" "))
.map(words => (words(0), 1))
.reduceByKey{(a,b) => a + b}
(2) ShuffledRDD[6] at reduceByKey at <console>:25 []
+-(2) MapPartitionsRDD[5] at map at <console>:24 []
| MapPartitionsRDD[4] at map at <console>:23 []
| log.txt MapPartitionsRDD[1] at textFile at <console>:21 []
| log.txt HadoopRDD[0] at textFile at <console>:21 []

构建DAG后,Spark调度器将创建一个物理执行计划。如上所述,DAG调度器将图分成多个阶段,阶段是基于转换创建的。狭窄的转换将被分组(管道内衬)到一个单一的阶段。因此,对于我们的示例,Spark将创建两个阶段的执行,如下所示:
https://imgs.xnip.cn/cj/n/22/252e14eb-165e-4efe-a59e-43bef8a75d7a.png" width="100%" height="100%" />
然后,DAG计划程序将把阶段提交到任务计划程序中。提交的任务数取决于TextFile中存在的分区数。Fox示例在这个示例中考虑我们有4个分区,那么将有4组任务被并行创建和提交,前提是有足够的从/核。下图更详细地说明了这一点:
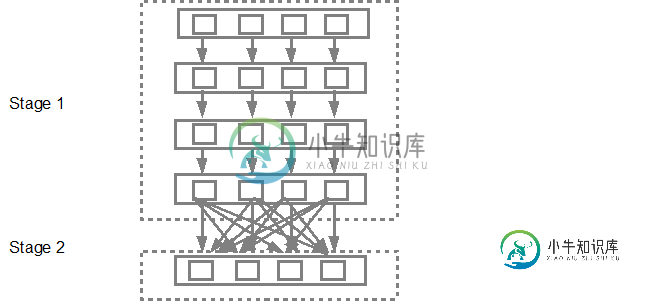
要获得更详细的信息,我建议您浏览以下youtube视频,在这些视频中,Spark的创建者提供了关于DAG和执行计划以及生命周期的深入细节。
-
null
-
在Spark中是如何工作的? 如果我们注册一个对象作为一个表,会将所有数据保存在内存中吗?
-
我从网上和论坛上看到了关于BatchSize的相关主题,但我仍然不明白一些部分。所以让我们描述一下我理解的和不理解的。 批量取数:选择取数的优化策略。Hibernate通过指定主键或外键列表,在一次选择中检索一批实体实例或集合。 让我们有JPA 2.0,带有Hibernate实现。这些实体: } 因此,我懒得去了解产品中的制造商。因此,当我执行select fetching时,就完成了。所以我有很
-
我的项目中的三个模型对象(本文末尾的模型和存储库片段)之间确实存在关系。 当我调用时,它会触发三个select查询: (“sql”) (对我来说)那是相当不寻常的行为。在阅读Hibernate文档后,我认为它应该始终使用连接查询。当类中的更改为时,查询没有区别(使用附加选择进行查询),当更改为时,城市类的查询也一样(使用JOIN进行查询)。 当我使用抑制火灾时,有两种选择: 我的目标是在所有情况下
-
我经常把文本输出到文件中。我想知道:是如何工作的? 当我调用时,它是否在文件上写入文本?如果它不写文本,我需要使用flush函数来写数据吗? 例如: 如果while循环中发生错误,文件将在不写入数据的情况下关闭。如果我在while循环中使用函数,那么为什么要使用?如果我错了,请纠正我。
-
我正从最基本的方面着手研究递归,因为我在过去很挣扎。我在看这个阶乘解: 因此函数会一直调用自己,直到<code>n==0</code>为止。然后在每次调用时返回值。这就是我不明白的:当它从基本条件返回时,它返回一个值,并不断添加每个调用的值。 这些值存储在哪里,以便最终能够返回总和?
-
在Kotlin中,编译以下代码: 但是,该代码不: 编译此代码将导致以下错误: 在Java中,两个示例都无法编译: 不出所料,前面的两个代码片段都会产生熟悉的编译器错误: 令我惊讶的是,第一个 Kotlin 示例根本有效,其次,如果它有效,为什么第二个 Kotlin 示例会失败?Kotlin 是否将方法的返回类型视为其签名的一部分?此外,为什么 Kotlin 中的方法签名与 Java 相比,它遵循