
beam/dataflow ReadAllFromParquet没有读取任何内容,但我的工作仍然成功?

我有一个数据流工作:
- 从GCS读取包含其他文件名的文本文件
- 将文件名传递给ReadAllFromParquet以读取。Parquet文件
- 写入BigQuery
尽管我的工作“成功”了,但它基本上没有经过ReadAllFromParquet步骤的输出集合。我成功地读取了列表中的文件,例如:['gs://my_bucket/my_file1.snappy.parquet'、'gs://my_bucket/my_file2.snappy.parquet'、'gs://my_bucket/my_file3.snappy.parquet']我还在readallfromparquet之前的步骤中使用记录器确认此列表和文件的GCS路径是正确的。
with beam.Pipeline(options=pipeline_options_batch) as pipeline_2:
try:
final_data = (
pipeline_2
|'Create empty PCollection' >> beam.Create([None])
|'Get accepted batch file: {}'.format(runtime_options.complete_batch) >> beam.ParDo(OutputValueProviderFn(runtime_options.complete_batch))
|'Read all filenames into a list'>> beam.ParDo(FileIterator(runtime_options.files_bucket))
|'Read all files' >> beam.io.ReadAllFromParquet(columns=['locationItemId','deviceId','timestamp'])
|'Process all files' >> beam.ParDo(ProcessSch2())
|'Transform to rows' >> beam.ParDo(BlisDictSch2())
|'Write to BigQuery' >> beam.io.WriteToBigQuery(
table = runtime_options.comp_table,
schema = SCHEMA_2,
project = pipeline_options_batch.view_as(GoogleCloudOptions).project, #options.display_data()['project'],
create_disposition = beam.io.BigQueryDisposition.CREATE_IF_NEEDED, #'CREATE_IF_NEEDED',#create if does not exist.
write_disposition = beam.io.BigQueryDisposition.WRITE_APPEND #'WRITE_APPEND' #add to existing rows,partitoning
)
)
except Exception as exception:
logging.error(exception)
pass
这就是我的工作图表后面的样子:

有人知道这里可能出了什么问题吗?最好的调试方法是什么?我目前的想法是:
>
桶权限问题。我注意到我正在阅读的桶是奇怪的,因为早些时候我不能下载文件,尽管我是一个项目所有者。project的所有者只有“存储遗留桶所有者”。我添加了“存储管理”,然后在用自己的帐户手动下载文件时,它工作得很好。根据Dataflow文档,我已经确保默认的compute service帐户和Dataflow帐户在此bucket上都有“Storage Admin”。然而,也许这都是一个转移注意力的问题,因为最终如果有权限问题,我应该在日志中看到这一点,作业将失败?
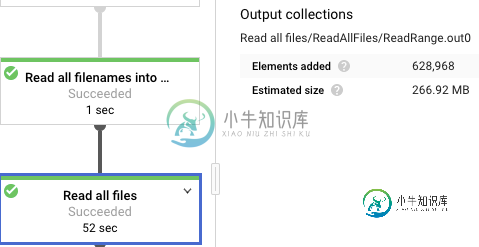

特别注意
Read all files/ReadAllFiles/ReadRange.out0
VS
Read all files/Read all files/ReadRange.out0
路径的第一部分是两个作业的步骤的名称。但我认为第二个是apache_beam.io.fileBasedSource(https://github.com/apache/beam/blob/master/sdks/python/apache_beam/io/filebasedsource.py)中的ReadAllFiles类,ReadAllFromText和ReadAllFromParquet都调用它。
我想知道如果这是一个实验功能,有没有办法打开它?
共有1个答案

您没有提到如果您使用的是最后一个Beam SDK,请尝试使用SDK2.16来测试最后的更改。
doc声明ReadAllFromParquet是一种实验性的功能,也是ReadFromParquet;尽管如此,ReadFromParquet仍被报告在以下线程中工作:从嵌套HDFS目录中读取parquet文件,您可能希望尝试使用此功能。
-
我知道这是个老问题,但它真的把我困住了。 我采纳了使用classLoader获取inputsream的建议,代码如下: 我确认ResourceUtil.GetInputStream工作正常,因为我可以打印hibernate.cfg.xml的内容,但为什么仍然给我错误: 信息:HHH000040:配置资源:/hibernate.cfg.xml线程“main”org.hibernate.hiberna
-
从https://projects.spring.io/spring-framework/,我有一个spring framework hellpworld程序。我删除了注释。然而,程序仍然可以像以前一样运行。为什么?这里的角色是什么?
-
我是一个初学者,所以请确保我正在开发的应用程序不是太复杂,只是一些基本的实验应用程序。 今天,我在处理的不同应用程序中不断遇到相同的错误:任务执行失败:“:app:compiledBugkotlin”。 我今天在演播室里肯定有关于kotlin的最新消息。这可能是更新的问题吗?其他人也有同样的经历吗?我不知道如何修理它。 Android没有在我的代码中标记任何错误,我已经确保构建中的依赖项是正确的。
-
对于套接字服务器应用程序,我创建了一个PacketFragmenter,它读取数据包的长度(在数据包的第二个字节中),然后将数据包发送回管道。 下面是我写的代码: 我在测试中得到了这个堆栈: 但一切都像它应该的那样进行,我得到两个数据包在一行,但他们很好地拼接,下一个处理程序正在做他的工作。 所以我不知道我应该处理这个例外还是忽略它?或者我可以做一件简单的事情来修复它,我根本不是网络专家(一周前开
-
我创建了一个应用程序来显示。但是,当我启动应用程序在模拟器关闭说。我在网上搜索,但找不到任何解决方案。我的代码activity_main.xml 美娜ctivity.java 我已经为Tab1、Tab2和Tab3创建了单独的. java文件。 Logcat是 06-01 01:40:35.429 1847-1847/com。realtech。6月1日带dalvikvm的标签﹕ threadid=1
-
我有两张桌子锻炼和练习。我正在尝试使用与我们点击的锻炼匹配的workout_id获取所有锻炼。我做了一个内部联接查询,但它似乎没有返回任何东西。我的查询有问题吗? 我正在使用SQLite创建我的数据库。我已经检查了,以确保练习表中有练习,并且它们有一个workout_id。 2)回到我的WorkoutProvider类中,我将selectionArgs设置为: 并把它传递到我的RawQuery中。