
如何使用selenium从span获取文本

我试图从span(图片中的质量)获取文本,但我还没有找到它无法获取文本的原因。
感谢所有的帮助,我正在使用python。
我的代码:
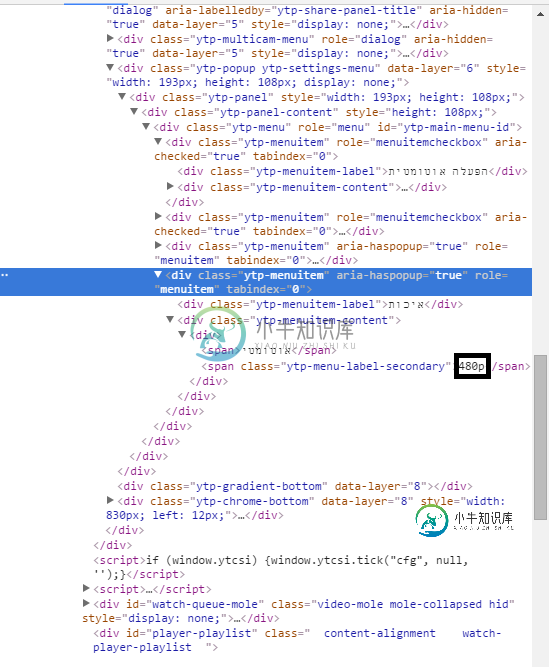
elem=driver.findElement(By.XPATH("//span[@class='ytp-menu-label-secondary']"));
从html:
共有2个答案

http://yizeng.me/2014/04/08/get-text-from-hidden-elements-using-selenium-webdriver/
摘录自此链接:根据WebDriver规范中的定义,Selenium WebDriver将只与可见元素交互,因此不可见元素的文本将始终作为空字符串返回。
然而,在某些情况下,人们可能会发现获取隐藏文本是很有用的,可以通过调用element.attribute(“属性名称”)或注入像返回参数[0]这样的JavaScript来从元素的文本内容、innerText或innerHTML属性中检索隐藏文本。
innerHTML将返回此元素的内部HTML,其中包含所有HTML标记。例如,Hello的innerHTML
世界!
世界!
从selenium导入webdriver
DEMO_PAGE=''数据:text/html,
演示页面,介绍如何使用Selenium WebDriver从隐藏元素中获取文本。
driver = webdriver.PhantomJS()
driver.get(DEMO_PAGE)
demo_div = driver.find_element_by_id("demo-div")
print demo_div.get_attribute('innerHTML')
print driver.execute_script("return arguments[0].innerHTML", demo_div)
print demo_div.get_attribute('textContent')
print driver.execute_script("return arguments[0].textContent", demo_div)
driver.quit

在python中应该是这样的
element = driver.find_element_by_xpath("//span[@class='ytp-menu-label-secondary']")
如果你愿意,也可以用类名
element = driver.find_element_by_class_name('ytp-menu-label-secondary')
对于文本
elementText = element.text
-
我正在尝试使用Python和Selenium获取此元素。 这就是我所尝试的: 我做错了什么?
-
我正在尝试使用webdriver从上面的html代码中获取动态跨度文本,但得到的是: org.openqa.selenium.nosuchelementException:找不到元素:{“method”:“id”,“selector”:“MathQ2”} 我需要从span id“MathQ2”获取文本:“6+4=” 此文本“6+4=”在每次刷新页面或加载新页面时都在更改 我尝试过xpath、id、
-
您好,我想得到的值以下的"交联",但我不知道如何做到这一点。 我正在使用Jsoup,下面是我的代码: 这就是我所拥有的: 你有什么想法可以得到价值,而不是“cotation”? 提前谢谢。
-
当我执行时,它也打印和,我如何在Python中使用selenium只获取示例文本?
-
问题内容: 我的链接看起来像这样 我想从那里去。我试过了 它输出。 我试过了,但它给了我KeyError。我该如何解决?我的错误是什么? 问题答案: 您可以使用css选择器,使用标题文本拉出所需的跨度: 找到具有包含 RAM 的 title 属性的 跨度 ,等效于在python中说。 或在 re.compile中 使用 find __ 要获取所有数据: 这会给你:
-
问题内容: 请参阅以下元素: 找到我的元素: 因此,找到后并使用带有selenium 或return 的文本: 所以我的问题是如何只获得没有这一点的最后一行 问题答案: 所需的文本出现在文本节点中,并且无法直接使用Selenium检索,因为它仅支持元素节点。 您可以删除开头: 您还可以使用正则表达式从中提取所需的内容: 或使用一段JavaScript: