
在Google云平台中解释成本数据

我在谷歌云平台上托管了一个基本的网络应用程序,我注意到在过去的几个月里,我的成本在慢慢上升。在过去的30天里,它真的加速了(幸运的是,在一个很小的基础上--我仍然在每天不到2美元的水平上滴答作响)。我已经几个月没有添加任何新的功能或客户端了,所以这有点令人惊讶。
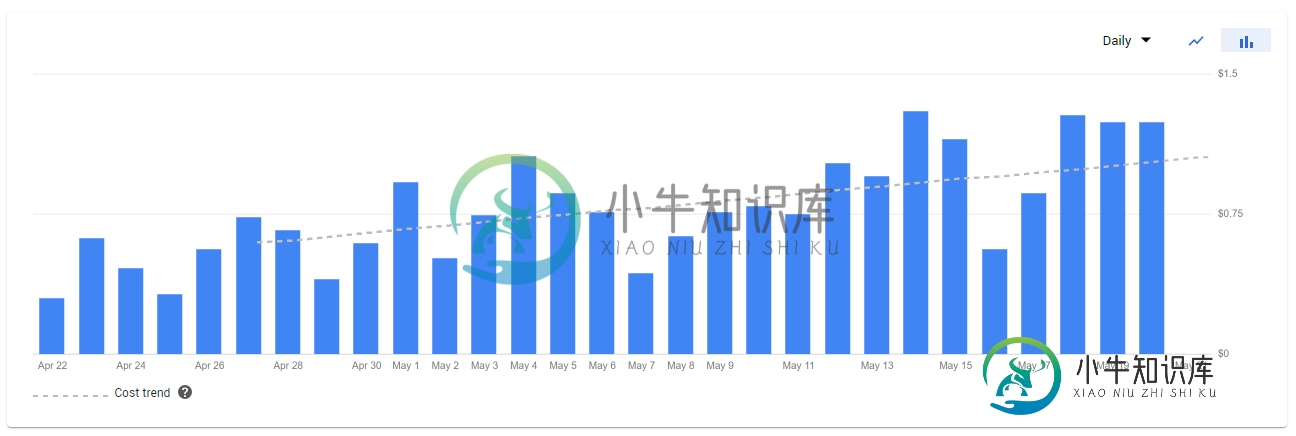
我的第一直觉是交通增加了。我在App Engine仪表板上看不到类似的内容,但我放入了一堆优化,并大幅降低了QPS以防万一。没有变化。
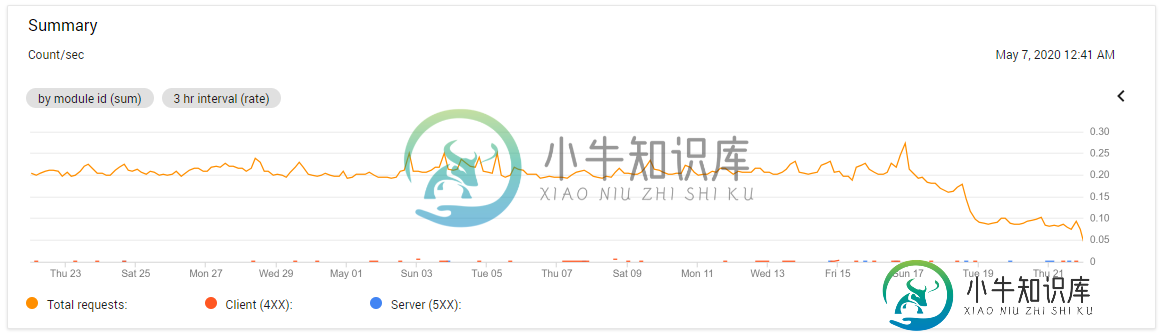
实例的数量也没有太大的变化--这看起来是最有可能的罪魁祸首,但它仍然只是持平,没有增长。
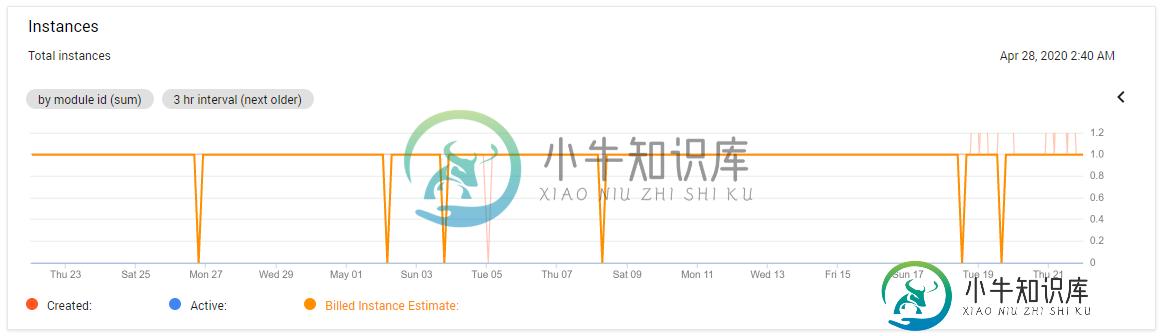
你知道怎么回事吗?我已经点击了计费中的所有图表和报告,但无法将成本的100%增长与qps、实例计数和数据库大小的持平或下降相协调。
共有1个答案

是的!我在一个运行Python 3.7的简单App Engine网站上看到过同样的事情!我从4月29日起就有一张票开着,他们没有帮助。我在3月24日看到前端实例时间发生了一个台阶变化,流量没有相应的增加。我有截图,真的很说明问题,但我不能上传,因为我没有10个声誉点。
无论是云控制台还是谷歌分析,流量都没有相应的增长。
更糟糕的是,每天的估计都显示我在28小时的配额下。例如,我拍摄了一张截图,显示在15小时后,我在当天的24.352个前端实例小时内保持同步(我在配额日结束时没有拍摄,因为它在凌晨3点重置)
-
我正在将一个整体应用程序重新设计成一个微服务架构,并希望使用谷歌云平台(GCP)来承载整个解决方案。我很难理解他们的成本细分,并担心我的成本将无法控制后,我建立它。这是一个个人项目,但我希望将有许多用户后,我推出,所以我想得到底层架构的权利,同时有合理的成本,最初当我推出。 下面是我的架构: 微服务1-4(共4个API服务): 在App Engine上运行 公开REST API并将数据保存到Dat
-
我正在寻找一种方法来执行在谷歌云平台的实例启动脚本类似于AWS中的用户数据。我检查‘启动脚本',但它是在每次启动时执行的。有什么办法可以实现吗?
-
在我的新公司,我是一名数据工程师,负责构建google cloud platform(GCP)批处理ETL管道。我的团队的数据科学家最近给了我一个数据模型(用Python3.6编写的.py文件)。 数据模型有一个主函数,我可以调用它并获得一个dataframe作为输出,我打算将这个dataframe附加到一个bigquery表中。我是否可以只导入这个主函数,并使用apache beam(Dataf
-
我有一个flask应用程序,它同时运行flask和flask-socketioendpoint。当我在google App engine上部署时,我意识到App engine不支持websockets。这意味着我需要为我的flask-socketio使用compute engine,并为我假设的常规flaskendpoint使用app engine。我将如何创建这两个实例,并在相互连接的同时并行运
-
我正在谷歌云平台上工作,我必须使用java非Web应用程序访问云功能,就像我正在尝试使用谷歌云存储JSON API存储和检索谷歌云存储中的对象一样。 在访问这些之前,我需要对我的应用程序进行身份验证,所以我找到了授权API来进行授权访问。 null 我浏览了GCP文档,但没有得到区分这些文档的明确信息,我对GCP非常陌生,所以请您分享任何信息或博客链接,以说明如何使用Google Cloud Cl
-
主题中的Kafka数据可以被流式传输、消费和吸收到BigQuery/云存储中,有哪些可能的选项。 按照,是否可以将Kafka与Google cloud Dataflow一起使用 GCP自带Dataflow,它建立在Apache Beam编程模型之上。KafkaIO与Beam Pipeline一起使用是对传入数据执行实时转换的推荐方式吗? https://beam.apache.org/releas