
有没有办法在不使用的时候降低Java堆?

我目前正在开发一个Java应用程序,并努力优化其内存使用。据我所知,我正在遵循正确垃圾回收的准则。但是,似乎我的堆似乎位于其最大大小,即使它不是必需的。
当计算机无人使用时,我的程序每小时运行一次资源密集型任务。这个任务使用了大量的内存,但是在任务完成后会立即释放所有的内存。NetBeans profiler显示内存使用情况如下:

我真的很想在不使用时将所有堆空间都还给操作系统。当程序在至少一个小时内都不会做任何事情的时候,我没有理由把它都浪费掉。
这可能吗?谢谢
共有3个答案

Java12使用G1GC支持此功能。
JEP 346:立即从 G1 返回未使用的已提交内存。
增强G1垃圾收集器,在空闲时自动将Java堆内存返回给操作系统。
https://openjdk.html" target="_blank">java.net/jeps/346
Java 13使用zgc支持此功能
JEP 351:ZGC:取消提交未使用的内存
ZGC当前不会取消提交并将内存返回到操作系统,即使该内存已长时间未使用。对于所有类型的应用程序和环境,尤其是那些需要考虑内存占用的应用程序和环境,此行为并不是最佳的。例如:按使用量支付资源费用的容器环境。
> < li>
应用程序可能长时间处于空闲状态,并与许多其他应用程序共享或竞争资源的环境。
应用程序在执行过程中可能有非常不同的堆空间要求。例如,启动期间所需的堆可能大于以后在稳态执行期间所需的堆。
http://openjdk.java.net/jeps/351

简而言之:是的,你可以。
长版本:
对于大多数应用程序,JVM默认值是可以的。看起来JVM希望应用程序只运行有限的时间。因此它似乎不会自行释放内存。
为了帮助 JVM 决定如何以及何时执行垃圾回收,应提供以下参数:
-
< li>
-Xms指定最小堆大小 < Li > < code >–Xmx 指定最大堆大小
对于服务器应用程序,添加:-server
如果上述参数不够,您可以影响JVM关于垃圾回收机制的行为。
首先,您可以使用System.gc()告诉VM您认为垃圾回收机制何时有意义。其次,您可以指定JVM应该使用哪些垃圾收集器:
>
串行GC
命令行参数: -XX: 使用串行GC
停止应用程序并执行 GC。
并行GC
命令行参数: -XX: 使用并行积分 -XX:并行积分线程 = 值
与您的应用程序并行运行次要集合。减少主要集合所需的时间,但使用另一个线程。
并行压缩GC
命令行参数:-XX:UseParallelOldGC
与您的应用程序并行运行主要收集。使用更多CPU资源,减少内存使用。
CMS GC
命令行参数: -XX: 使用图标清除 -XX: 使用Par新标记 -XX: CMS并行标记启用 -XX:CMS启动占用情况=值 -XX: 使用CMS启动占用仅
执行比串行GC更小的收集,并且更频繁,从而限制了应用程序的中断/停止。
命令行参数:-XX:Unlock实验性VMOptions-XX:UseG1GC
实验性的(至少在Java 1.6中):试图确保应用程序不会停止超过1s。
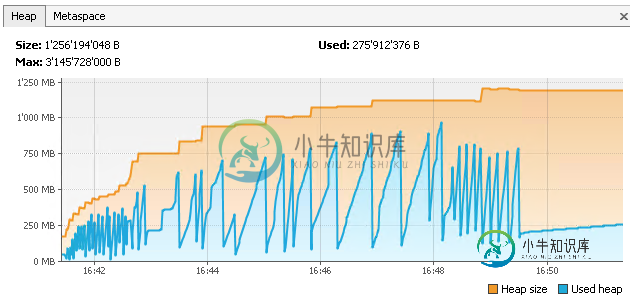
在这种情况下,仅使用参数的优化是无效的。有些计划任务占用了相当多的内存。在这种情况下,在内存密集型操作后,使用CMS GC结合System.gc()来实现最佳性能。结果,WebApp的内存使用量从1.8 GB减少到大约400-500 MB。
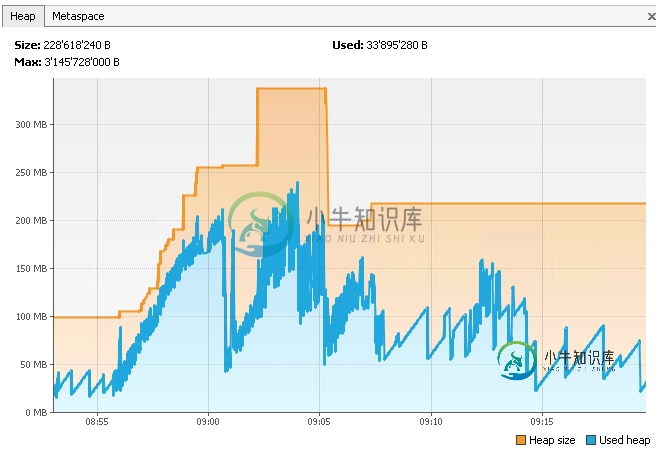
您可以在这里看到VisualVM的另一个屏幕截图,其中显示了JVM如何释放内存并实际返回到操作系统:
- 关于JVM GC调优的文章
- 可用GC的Oracle文档

您也许可以使用-XX:MaxHeapFreeRatio来处理-这是GC收缩之前空闲堆的最大百分比(默认值为70)。也许把它调低一点(40或50?)然后使用System。gc()可能会花费一些时间来获得所需的行为?
然而,没有办法强迫这种情况发生,你可以尝试鼓励JVM这样做,但是你不能随心所欲地把内存拿走。虽然上述方法可能会缩小堆,但内存不一定会直接返回操作系统(尽管在最近的JVM实现中确实如此)。
-
例如,-从索引0迭代到索引10。 -但从10到0不起作用,如何使用流API实现?
-
问题内容: 我想在Python中使用PhantomJS。我用谷歌搜索了这个问题,但是找不到合适的解决方案。 我发现 可能是一个不错的选择。但是我无法通过一些争论。 使用可能是目前合适的解决方案。我想知道是否有更好的解决方案。 有没有办法在Python中使用PhantomJS? 问题答案: 在python中使用PhantomJS的最简单方法是通过Selenium。最简单的安装方法是 安装NodeJS
-
我想在Python中使用PhantomJS。我谷歌了这个问题,但找不到合适的解决方案。 我发现可能是一个不错的选择。但我无法向它传递一些论据。 使用目前可能是一个合适的解决方案。我想知道是否有更好的解决办法。 有没有办法在Python中使用PhantomJS?
-
问题内容: 我有一个自动运行git clone /pull的脚本(这实际上发生在jenkinsCI中,但我的问题更笼统)。远程git服务器基于HTTPS。带有git客户端的计算机具有不稳定的DSL Internet连接,因此有时会重新连接并更改IP地址,从而丢失所有现有连接。当git客户端运行时连接失败时,客户端将永远不会成功,但也不会因超时而失败,因此我的脚本会挂断。 我想设置客户端,使其在一段
-
问题内容: 我希望Jenkins为开放拉取请求中的每个分支自动找到并运行测试套件。我找不到的某些Jenkins插件有可能吗? 问题答案: 最近为Jenkins发布了一个新插件-Github pull request builder 。 如果它按锡罐上的说明去做,那可能就是您想要的。
-
我正在使用的Springboot REST服务器使用Logback的RollingFileAppender和SizeAndTimeBasedRollingPolicy记录文件。 我希望spring执行器的“logfile”endpoint从最近的文件返回日志,但是文件名会根据给定的文件名模式更改。 日志文件执行器是否有访问日志文件的方法,而不是使用应用程序中给定的文件或路径。财产?