
如何缩小java堆空间?[重复]

我有一个Java控制台应用程序,它使用DOM处理大的xml文件,基本上它从数据库中获取的数据创建xml文件。现在,正如你所猜测的那样,它使用了大量的内存,但令我惊讶的是,它与糟糕的代码无关,而是与“Java堆空间没有缩小”有关。我尝试使用这些JVM参数从Eclipse运行我的应用程序:
-Xmx700m -XX:MinHeapFreeRatio=10 -XX:MaxHeapFreeRatio=20
我甚至添加了
-XX:-UseSerialGC
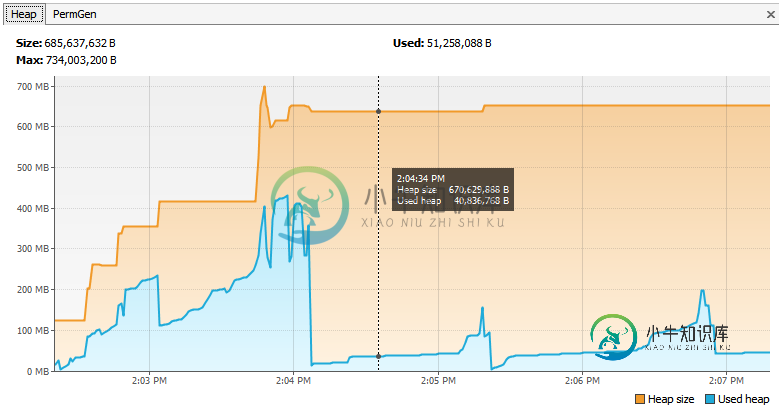
正如您所看到的,我的应用程序在某一点上占用了约400 MB的堆空间,堆增长到约650 MB,但几秒钟后(当xml生成完成时),应用程序使用的堆减少到12MB,但“堆大小”仍保持在约650 MB。它占用了我650 MB的内存!这太奇怪了,你不觉得吗?
**有没有办法强制 JVS 将可用堆大小缩小到当前已用堆的 150%?**例如,如果我的应用需要 15 MB 的 RAM,堆大小约为 20MB,当我的应用要求 400 MB 的 RAM 时,堆会增长到 ~600 MB,一旦我的应用完成繁重的提升操作,堆就会增长到 ~600 MB,并丢弃回 ~20 MB?
共有1个答案

您可能应该使用并行收集,并使用-XX:-UseAdaptiveSizePolicy。文档是针对Java 1.5的,但是我找不到更新的。
默认情况下与-XX:UseParallelGC垃圾收集器一起使用的-XX:UserAdaptiveSizePolicy的实现已更改为考虑三个目标:
- 期望的最大GC暂停目标
- 期望的应用程序吞吐量目标
- 最小占用空间
实施检查(按此顺序):
-
< li >如果GC暂停时间大于暂停时间目标,则减小代的大小以更好地实现目标。 < li >如果达到暂停时间目标,则考虑应用程序的吞吐量目标。如果没有达到应用程序的吞吐量目标,那么增加代的大小以更好地达到目标。 < li >如果同时满足暂停时间目标和吞吐量目标,则减小代的大小以减少占用空间。
编辑
根据OP的建议增加了“-”。
-
我有一个Quarkus应用程序,它可以转换大量数据。在某个时候,我总是会遇到内存不足异常。我想当我在“Java模式”下运行应用程序时,JVM xmx标志应该可以为Quarkus提供更多内存。对吗? 作为本机映像运行时如何设置应用程序的内存?
-
我有一个文件,大小,我试图在Windows10上运行它,在DBeaver程序上使用RAM,我得到错误 我尝试了许多解决办法,但都不起作用。、、对我都不起作用。
-
我面临一些关于内存问题的问题,但我无法解决它。非常感谢您的帮助。我不熟悉Spark和pyspark功能,试图读取大约5GB大小的大型JSON文件,并使用 每次运行上述语句时,都会出现以下错误: 我需要以RDD的形式获取JSON数据,然后使用SQLSpark进行操作和分析。但是我在第一步(读取JSON)本身就出错了。我知道要读取如此大的文件,需要对Spark会话的配置进行必要的更改。我遵循了Apac
-
当我使用spark运行一个模型训练管道时,我产生了上面的错误 oom错误由org.apache.spark.util.Collection.ExternalSorter.WritePartitionedFile(ExternalSorter.Scala:706)触发(在堆栈跟踪的底部) 日志: 任何建议都会很棒:)
-
在Ubuntu中,当我运行hadoop示例时: 在日志中,我得到的错误为: 信息映射。JobClient:任务Id:尝试\u 201303251213\u 0012\u m\u000000 \u 2,状态:失败错误:Java堆空间13/03/25 15:03:43信息映射。JobClient:任务Id:trunt\u 201303251213\u 0012\u m\00000 1\u 2,状态:F
-
突然我的应用程序无法运行并弹出此错误...这个错误有什么想法吗?努力了还是解决不了... Java堆空间绑定文件。例如,在gradle.properties文件中,以下行将最大Java堆大小设置为1,024 MB:org.gradle.jvmargs=-Xmx1024m阅读Gradle的配置指南 阅读Java的堆大小