
使用Jsoup获取完整的HTML

我正在刮网页使用JSoup库通过选择类属性,其中包含"nav"字符串。
这是获取网站超文本标记语言的代码:
var bodyString = Jsoup.connect(url)
.ignoreContentType(true)
.userAgent("Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:25.0) Gecko/20100101 Firefox/25.0")
.timeout(12000)
.followRedirects(true)
.execute()
.body();
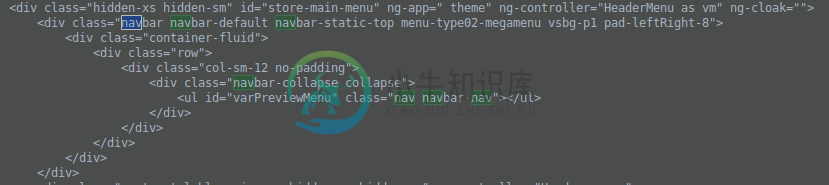

正如您所看到的,id=“varPreviewMenu”的ul元素包含Jsoup检索到的HTML不包含的li元素。
我怎样才能得到那些元素?
共有1个答案

您看到的元素很可能是通过一些JavaScript代码动态添加到DOM中的。这意味着在使用Jsoup时,它们在请求主体中不可用。
-
我正在尝试用JSOUP从以下页面获取内容:
-
问题内容: 我有一个学校项目,可以解析网络代码并将其像数据库一样使用。当我尝试从(https://www.marathonbet.com/en/betting/Football/)提取数据时,我没有全部了解吗? 这是我的代码: 获得的结果(这是显示的联赛的最后一个): 在她上面显示所有联赛。 为什么我没有完整的数据?感谢您的时间! 问题答案: Jsoup的默认正文响应限制为1MB。您可以使用 ma
-
Jsoup库未解析给定URL的完整html。URL的原始html中缺少一些分区。 有趣的事情:http://facebook.com/search.php?init=s:email&q=somebody@gmail.com&type=users 如果您在jsoup的官方站点http://try.jsoup.org/中给出了上面提到的url,它通过提取正确地显示了url的确切html,但是在使用js
-
问题内容: 我想实现一个Java方法,该方法以URL作为输入并将整个网页(包括CSS,图像,JS(所有相关资源))存储在磁盘上。我已经使用Jsoup html解析器来获取html页面。现在,我想实现的唯一选择是使用jsoup获取页面,现在解析html内容并将相对路径转换为绝对路径,然后再次请求获取javascript,图像等并将其保存在磁盘上。我还阅读了有关HTML清洁器,htmlunit解析器的
-
我想实现一个java方法,它将URL作为输入,并将包括css、图像、js(所有相关资源)在内的整个网页存储在我的磁盘上。我已经使用Jsoup html解析器来获取html页面。现在,我想实现的唯一选项是使用jsoup获取页面,现在解析html内容,将相对路径转换为绝对路径,然后发出另一个获取javascript、图像等的请求。并将它们保存在磁盘上。我也读过html cleaner和htmlunit
-
我有一些url。我想从url指向的html中获取所有href,从所有获取的hrefs中获取所有href(递归)。关键是我想设置“递归”的深度。例如,如果深度=1,我只需要来自超文本标记语言的href。如果深度=2,我需要来自超文本标记语言的hrefs(假设为list1)和来自list1的每个href的hrefs,依此类推 以下是我使用jsoup得到的结果: 我应该如何修复递归条件以使其正确?