
Itextsharp在页尾插入页脚

我有一个模板分裂成3个文件(头,正文和页脚),所有在HTML。我需要导出一个pdf文件,使用
itextsharp lib。
我使用折叠代码来实现这一点。
public string GeneratePDF(Dictionary<string, object> fieldValues, string pdfPath, string templatePath)
{
//Inicializes a New Document
Document document = new Document(PageSize.A4,0,0,0,0);
try
{
PdfWriter writer = PdfWriter.GetInstance(document, new FileStream(pdfPath, FileMode.Create));
PdfPageEvents events = new PdfPageEvents();
//Initializes page events
writer.PageEvent = events;
//Open Document
document.Open();
//Gerar efetivamente o html
TemplateHelper objTemplate = new TemplateHelper();
//This function is not important, only replaces the content by a dictionary
string htmlContent = objTemplate.GenerateHTML(fieldValues, templatePath);
//Gerar o PD
StringReader reader = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, reader);
}
catch (Exception ex)
{
throw;
}
finally
{
document.Close();
}
return pdfPath;
}
public class PdfPageEvents : PdfPageEventHelper
{
public override void OnStartPage(PdfWriter writer, Document document)
{
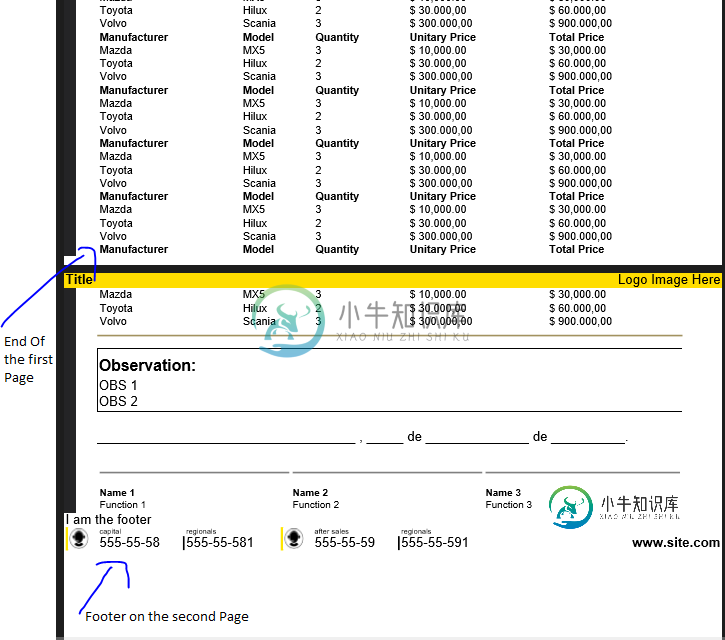
StreamReader template = new StreamReader(@"d:\Header.html");
string htmlContent = template.ReadToEnd();
StringReader reader = new StringReader(htmlContent);
ElementList e = XMLWorkerHelper.ParseToElementList(htmlContent, "");
PdfDiv div = (PdfDiv)e.First();
document.Add(div.Content.First());
template.Close();
template = new StreamReader(@"d:\Footer.html");
htmlContent = template.ReadToEnd();
reader = new StringReader(htmlContent);
}
//começa com o cabeçalho
public override void OnEndPage(PdfWriter writer, Document document)
{
StreamReader template = new StreamReader(@"d:\Footer.html");
string htmlContent = template.ReadToEnd();
StringReader reader = new StringReader(htmlContent);
ElementList elementListFooter = XMLWorkerHelper.ParseToElementList(htmlContent, "");
PdfDiv div = (PdfDiv)elementListFooter.First();
PdfPTable t = (PdfPTable)div.Content.First();
document.Add(t);
template.Close();
}
}


共有1个答案

为了更详细地解释Bruno在注释中所说的内容,如果在页面事件中add()内容,可以想象可以导致文档生成一个新页面,这将导致页面事件再次激发。更有趣的是,如果页面事件添加了太多内容,您实际上可能会陷入添加、溢出、新建页面、重复的无限循环。
如果您想要真正的页眉和页脚,请设置文档页边距以说明两者的高度,而普通的文档。add()代码将尊重它。如果您不知道页眉和/或页脚每次将有多高,可以尝试使用以下代码来计算高度。
然后,可以使用page events或two-pass来添加页眉和页脚以及使用DirectContent或ColumnText的已知固定位置。您的内容似乎相当简单,所以您可能可以将其转换为普通的iTextSharp命令,但是如果您希望将HTML用于页眉和页脚,请参阅以下文章,将HTML解析为元素列表,并将其添加到columntext中。
-
我试过以下方法。它似乎使每个页面后面的空白页的方向和大小是源PDF页面的方向和大小,但源PDF页面的方向和大小似乎是前一个空白页的方向和大小:
-
我有一个PDF文档,通常,每一页都有一个页脚,页脚上有一个页码,前面有该页应该所在的章节或节的名称。但是,偶尔,我会得到一些跨越多个页面的大表结果。 我跳过为文档添加页眉和页脚信息,因为我有一个封面。因为不同的部分是不同的信息,所以我根据不同的领域将它们分解为章节和小节。此外,用户可以选择打印出一次从数据库信息生成的多个PDF。在每一章的开头,我使用以下命令设置页脚文本: 或者至少我在努力。当谈到
-
我需要在页眉中插入页码,比如第x页,共n页。这应该很简单,但我无法让它工作。 我试过了。 使用xmlns:fo = " http://www . w3 . org/1999/XSL/Format名称空间并在文档末尾 任何帮助将不胜感激。 谢谢。
-
我是ItextSharp的新手,只是想知道如何在页面结束事件后将页眉和页脚放在边距之外?似乎当我使用onendpage事件而不是将页脚添加到页边距之外时,它添加到了页边距内部,并且当它将在应该添加到页边距之外的底部页边距之上时,它总是产生stackoverflow异常? 是否有任何设置来将文本添加到页边距之外的文档页脚(或者是填充)? 提前谢了。
-
我正在尝试使用iTextSharp循环浏览PDF文档并删除所有空白页。我有代码检查每个页面是否为空,并将其写入新的PDF,但在关闭新文档时,我收到错误“文档没有页面”。但是,在文件夹中创建的文件确实具有我所期望的文件大小。 这是我目前的代码:
-
我尝试使用iTextSharp创建一个多页pdf文档。我有一个包含自身方向(横向或纵向)的对象。当第一个对象包含需要横向模式的信息时,我用< code > Document doc = new Document(PageSize。A4.Rotate(),10f,10f,10f,0f)。这工作得很好,直到下一个元素是肖像模式!如果一个元素处于纵向模式,我再次设置页面大小:< code>doc。Set