
Netty:如何跨松散耦合的服务共享ChannelHandleContext

在客户端服务器应用程序上工作,在服务器端,我有一个面向客户端的服务组件,它拦截来自客户端的所有套接字请求,扫描消息后,它通过消息总线路由到不同的服务,因此它们是松散耦合的。
类似这样:
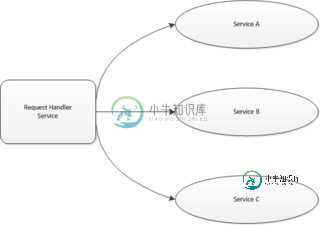
问题是,一旦服务完成了业务逻辑,就需要将回复发送回客户端,但通过“请求处理程序服务”,因此来自所有服务的所有回复消息都通过单个服务组件,即“请求处理程序服务”,因为我没有ChannelHandleContext对象引用与其他服务将回复发送回客户端。
我在考虑使用一个集中式分布式缓存服务(如memcached)来存储类似以下的映射(用户Id-
在这种情况下,什么是正确的方法,以便我现在可以轻松地扩展我的应用程序这确实是一个大的设计问题。
共有1个答案

您可以通过保留队列来解决此问题
问题的解决方案看起来像这个答案,但我们需要编辑一些对流中流水线的支持,以便正确处理多个路由。
假设您的用例是这样的:
+------------+ +------------+
| | | |
| client |+--------+ +----->| upstream |
| 1 | | | | 1 |
+------------+ | | +------------+
| |
+------------+ | +----------+ | +------------+
| | | | this | | | |
| client +---------+------>| server |-----+----->| upstream |
| 2 | | | | | | 2 |
+------------+ | +----------+ | +------------+
| |
+------------+ | | +------------+
| | | | | |
| client +---------+ +----->| upstream |
| 3 | | 3 |
+------------+ +------------+
我们需要确保在实施时满足以下几点:
如果我们允许请求的流水线(建议用于性能),我们需要一种使用例如序列号来识别请求的方法,或者我们需要对数据包进行去分段以正确的顺序出现。- 我们需要一种方法,在上游超时时向客户端发送超时响应
我们将假设该协议没有任何数据包序列号,因为这是最难解决的情况。
假设“请求处理程序服务”的编写考虑到了对大量请求的支持,它具有可以通过一些回调调用的方法。
前提是您的“请求处理程序服务”具有如下所示的 api 实现:
public interface RequestHandlerService {
public default Future<Response> callMethod(Command cmd) {
return callMethod(cmd, promise);
}
public Future<Response> callMethod(Command cmd, Promise promise);
}
public interface ServerSelector {
public RequestHandlerService selectNextServer(Command cmd);
}
public interface Command {
// ....
}
public interface Response {
// ....
}
上面的系统是通用的,可以用于几乎所有类型的api,这是一种快速实现的方法,即使上面的系统不支持传递回调类,如本答案所示,它为Netty连接执行此操作。
我们可以制作以下处理程序来处理来自客户的请求:
public class UpstreamDispachHandler extends SimpleInboundHandler<String> {
private final static int MAX_PIPELINED_REQUESTS = 32;
private final ServerSelector servers;
private final ArrayDeque<Future<Response>> messageList =
new ArrayDeque<>(MAX_PIPELINED_REQUESTS);
protected ChannelHandlerContext ctx;
public UpstreamDispachHandler (ServerSelector servers) {
this.servers = servers;
}
public void channelRegistered(ChannelHandlerContext ctx) {
this.ctx = ctx;
}
// The following is called messageReceived(ChannelHandlerContext, Command) in Netty 5.0
@Override
public void channelRead0(ChannelHandlerContext ctx, Command msg) {
if(messageList.size() >= MAX_PIPELINED_REQUESTS) {
// Fast fail if the max requests is exceeded
ctx.writeAndFlush(new FailedResponse(msg));
return;
}
RequestHandlerService nextServer = servers.selectNextServer(msg);
if (nextServer == null) {
// Fast fail if the max requests is exceeded
ctx.writeAndFlush(new FailedResponse(msg));
return;
}
sendCommandUpstream(msg, nextServer);
}
}
上面的代码声明了构造函数和我们使用的变量,我们使用ArrayDeque作为我们响应的临时存储,以确保顺序保持不变。
现在,我们定义了 sendCommand 上游(命令、请求处理程序服务)以将请求添加到队列中,并将其传递到上游。
private void sendCommandUpstream(Command cmd, RequestHandlerService nextServer) {
synchronized(messageList) {
messageList.add(nextServer.callMethod(cmd, ctx.executor().newPromise()
.addListener(f->recalculatePendingReplies())));
}
}
我们通过messageList进行同步,而不是使用具有内部同步支持的队列>,其原因是为了确保我们未来的一些操作能够正常工作。
我们现在处于软件客户端-服务器部分的最后一部分,确保回复以正确的顺序路由回去。为此,我们正在偷看队列的头部,以检查未来是否完成。如果头部完成,我们可以删除它(),从中提取响应,并将其发送回客户端,确保在发送所有响应后刷新()管道。出于性能原因,我们只是在每个数据包之后在最后刷新。
private void recalculatePendingReplies() {
boolean hasSendMessage = false;
boolean interruped = false;
synchronized(messageList) {
Future<Response> elm = messageList.peek();
while (elm != null && elm.isDone()) {
elm.remove();
Response result;
try {
while(true) {
try {
result = elm.get();
break;
} catch (InterruptedException e) {
interrupted = true;
}
}
} catch (ExecutionException e) {
// Do something better with e
e.printStackTrace();
result = new FailedResponse();
} catch (ExecutionException e) {
// Task is cancelled
result = new FailedResponse();
}
ctx.write(result);
hasSendMessage = true;
}
if(hasSendMessage)
ctx.flush();
}
if(interrupted)
Thread.currentThread().interrupt();
}
上面的代码中使用了一些设计模式,例如,布尔标志用于存储线程的中断状态,而不是吞咽异常。即使在抛出InterruptedException(不应该发生)的情况下,也会正确处理它。
有时,我们想在协议中实现对超时的支持,例如,如果上游在x时间内没有响应。HashedWheelTimer非常适合这种操作,因为它的特性可以轻松修改以适应应用程序的使用模式。
如“近似”所述,该定时器不按时执行预定的TimerTask。HashedWheelTimer将在每个时钟周期检查是否有任何TimerTasks落后于计划并执行它们。通过在构造函数中指定更小或更大的节拍持续时间,可以提高或降低执行计时的准确性。在大多数网络应用中,I/O超时不需要精确。因此,默认的节拍持续时间是100毫秒,在大多数情况下,您不需要尝试不同的配置。
HashedWheelTimer维护着一个叫做‘wheel’的数据结构。简单来说,轮子就是TimerTasks的哈希表,其哈希函数是‘任务的死线’。每个轮子的默认刻度数(即轮子的大小)是512。如果要安排大量超时,可以指定一个较大的值。
我们在程序的顶部定义了以下常量集:
private final static long TICK_DURATION = 100;
private final static int WHEEL_SIZE = 128;
private final static long DEFAULT_TASK_TIMEOUT = TICK_DURATION * DEFAULT_TASK_TIMEOUT;
private final static HashedWheelTimer timer = new HashedWheelTimer(
Executors.defaultThreadFactory(),
TICK_DURATION,
TimeUnit.MILLISECONDS,
WHEEL_SIZE);
然后,我们修改我们的< code>sendCommandUpstream方法,将时间表设置为超时,这样就调用了tasks cancel()。我们可以通过以下方式做到这一点:
private void sendCommandUpstream(Command cmd, RequestHandlerService nextServer) {
synchronized(messageList) {
Future<Response> r = nextServer.callMethod(cmd, ctx.executor().newPromise()
.addListener(f->recalculatePendingReplies()));
messageList.add(r);
timer.newTimeout((Timeout timeout) -> {
if (!r.isDone())
r.cancel(true);
}, DEFAULT_TASK_TIMEOUT, TimeUnit.MILLISECONDS);
}
}
-
作为将微服务连接在一起并使其工作的机制,通常建议使用API和服务发现。但它们通常作为自己的微服务工作,但这些微服务显然应该“硬编码”到其他微服务中,因为每个微服务都应该向它们注册并查询其他微服务的位置。这是否打破了松耦合的思想,因为发现服务的丢失意味着其他服务无法通信?
-
我不清楚如何取回购买服务不保存的数据--例如:用户的全名。当试图通过购买用户名进行更复杂的搜索购买时,问题会变得更严重。 我认为,显然可以通过在两个服务之间同步用户来解决这个问题,方法是在用户创建时广播某种类型的事件(并在购买服务端只保存相关的用户属性)。在我看来,这远非理想。当你有数百万用户时,你如何处理这个问题?您会在每个使用用户数据的服务中创建数百万条记录吗? 另一个明显的选择是在用户服务端
-
有人能帮我吗,我读了一些Java紧耦合和松耦合的文章。我看了好几段YouTube视频和文章,对松散耦合有一定的怀疑,但仍然无法理解某些要点。我会解释我所理解的和让我困惑的。 在松散耦合中,我们限制类之间的直接耦合。但在紧密耦合中,我们注定要去上课。让我们举个例子。我有一个主类和另一个名为Apple的不同类。我在Main类中创建了这个类的一个实例 让我们看看松耦合 如果我将松散耦合中的方法签名从“喝
-
问题内容: 首先,我想说两件事。首先,很抱歉,如果已经有人问过这个问题,我已经搜索了与此主题相关的类似问题,但找不到解决方案。其次,对于冗长的问题,我们深表歉意,如有任何错误,请通知我,我将确保做出适当的更改:)。 我是Android开发的新手(大约2个月),所以请原谅我的无知。我有关于Android服务的问题。 我的问题如下,我创建了以下3个应用程序: 一个包含小型测试服务( myService
-
问题内容: 编辑: 这不是理论上的冲突,而是实现上的冲突。 另一个编辑: 问题不是将域模型作为仅数据/ DTO,而是将Order具有OrderItems和一些calculateTotal逻辑的更丰富,更复杂的对象映射。特定的问题是,例如,当Order需要从中国的某个Web服务中获取OrderItem的最新批发价格时(例如)。因此,您正在运行一些Spring Service,可以在中国调用该Pric
-
我正在使用SpringBoot1.4开发一些Spring应用程序。1和spring boot starter与ELEAF的依赖关系。我希望在我的Web服务器上共享我的ThymileAF模板(例如页眉和页脚),以便能够将它们包含在我的应用程序中。实现这一点的最简单方法是在我的每个应用程序中包含指向我的模板的服务器根相对链接。这样,我的应用程序将是可移植的,我可以让它在我的所有环境(开发、测试、产品)