
超级队列和行填充缓冲区的语义是什么?

我问这个问题关于哈斯韦尔微架构(英特尔至强E5-2640-v3 CPU)。从CPU和其他资源的规格中,我发现有10个LFB,超级队列的大小是16。我有两个与LFB和超级队列有关的问题:
1)系统可以提供的最大内存级并行度是多少,10或16(LFB或SQ)?
2)根据一些来源,每个L1D未命中被记录在SQ中,然后SQ分配行填充缓冲区,并且在一些其他来源,他们已经写道SQ和lfb可以独立工作。你能简单解释一下SQ的工作原理吗?
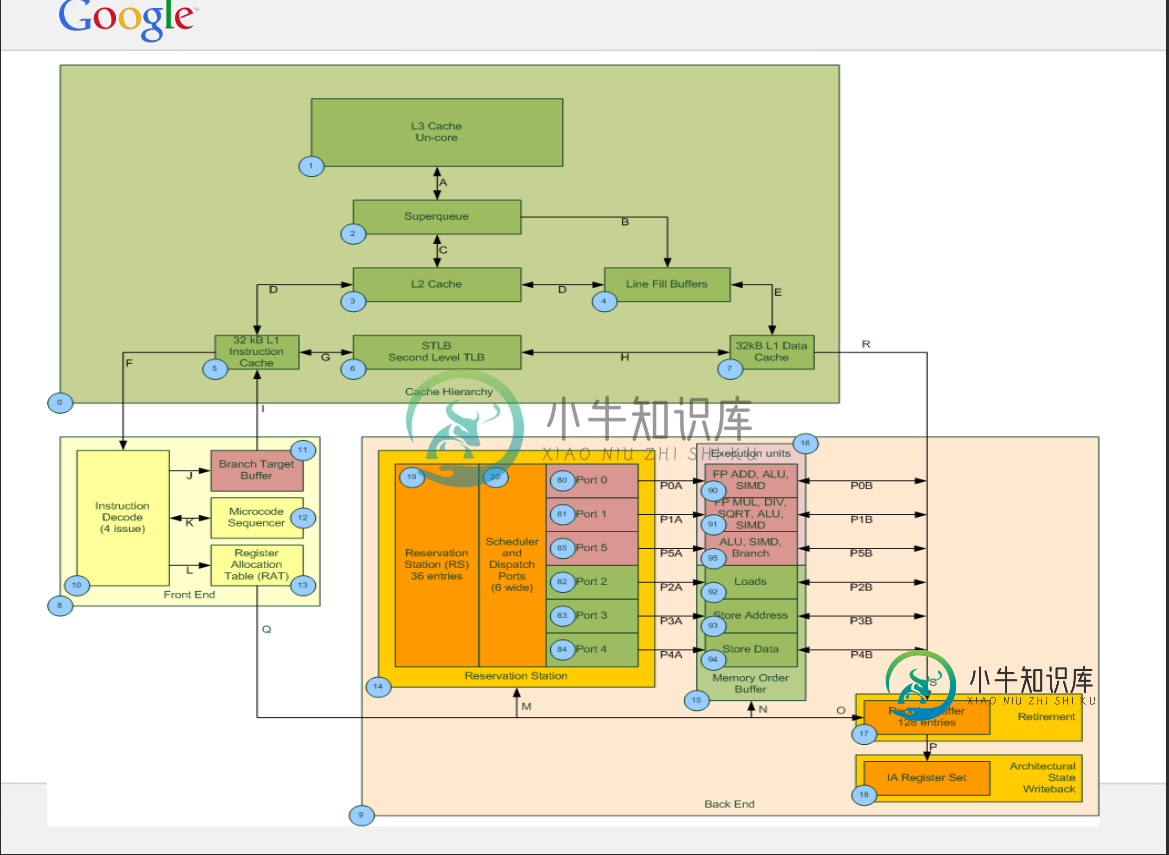
http://www.realworldtech.com/haswell-cpu/
共有1个答案

对于 (1) 从逻辑上讲,最大并行度将受到管道的最小并行部分(即 10 个 LFB)的限制,当预取被禁用或无法帮助时,对于需求加载并行性,这可能是严格正确的。在实践中,一旦您的负载至少部分地通过预取得到帮助,一切都会变得更加复杂,因为这样就可以使用L2和RAM之间的更宽的队列,这可能会使观察到的并行度大于10。最实用的方法可能是直接测量:给定测量到的 RAM 延迟和观察到的吞吐量,您可以计算任何特定负载的有效并行度。
对于(2),我的理解是,情况正好相反:L1中的所有需求未命中首先分配到LFB(当然,除非它们命中现有的LFB),如果它们也未命中缓存层次结构中的较高位置,则稍后可能涉及“超级队列”(或者现在称之为什么)。您包含的图表似乎证实了这一点:从L1到LFB的唯一路径是通过LFB队列。
-
问题内容: 我碰到一行,命令的输出已完全缓冲。这是什么意思? 问题答案: 在线C11标准 7.21.3 / 3: 当流没有 缓冲时 ,字符应尽快从源或目标出现。否则,字符可能会作为块被累积并传输到主机环境或从主机环境传输。当流被 完全缓冲时 ,打算在填充缓冲区时将字符作为块与主机环境进行传输。当流被 行缓冲时 ,当遇到换行符时,字符打算作为块与主机环境进行传输。此外,当填充缓冲区,在无缓冲流上请求
-
两者都是序列化库,由谷歌开发人员开发。他们之间有什么大的区别吗?将使用协议缓冲区的代码转换为使用FlatBuffers需要大量工作吗?
-
在循环队列的数组实现中,如果在第一个元素之前指向一个插槽,而在最后一个元素之后指向一个插槽,则会面临如何识别队列是满还是空的问题。 为了解决这个问题,我们要么使用计数器,要么在缓冲区中浪费一个空间。 我在想下面的方法。请纠正我的错误,如果没有请让我知道这是一个更好/更差的解决方案比以上。 null
-
以下是我的情况: 我已经编写了一个小型的延迟3D引擎,使用MRT(多渲染目标)填充我的G缓冲区(同时填充我的所有位置、法线、颜色和镜面反射纹理)。 此外,我还在我的G-Buffer FBO上附加了一个渲染缓冲区对象(RBO),该对象初始化为GL_DEPTH_STENCIL_ATTACHMENT(GL_DEPTH24_STENCIL8)。因此,在G缓冲区执行期间,我的4个纹理同时被填充,渲染缓冲区同
-
问题内容: python中有一个类型,但是我不知道该如何使用它。 在Python文档中,描述为: object参数必须是支持缓冲区调用接口的对象(例如字符串,数组和缓冲区)。将创建一个引用该对象参数的新缓冲区对象。缓冲区对象将从对象的开头(或指定的偏移量)开始是一个切片。切片将延伸到对象的末尾(或具有由size参数指定的长度)。 问题答案: 用法示例: 在这种情况下,缓冲区是一个子字符串,从位置6
-
本文向大家介绍C#环形缓冲区(队列)完全实现,包括了C#环形缓冲区(队列)完全实现的使用技巧和注意事项,需要的朋友参考一下 公司项目中经常设计到串口通信,TCP通信,而且大多都是实时的大数据的传输,然后大家都知道协议通讯肯定涉及到什么,封包、拆包、粘包、校验……什么鬼的概念一大堆,说简单点儿就是要一个高效率可复用的缓存区。按照码农的惯性思维就是去百度、谷歌搜索看有没有现成的东西可以直接拿来用,然而