
使用PostMan上传多部分亚马逊S3 Rest API时出现问题

我正在尝试使用亚马逊-S3 REST API来上传大文件。
根据这里的API文档,我与邮递员形成了我的请求,如下所示。
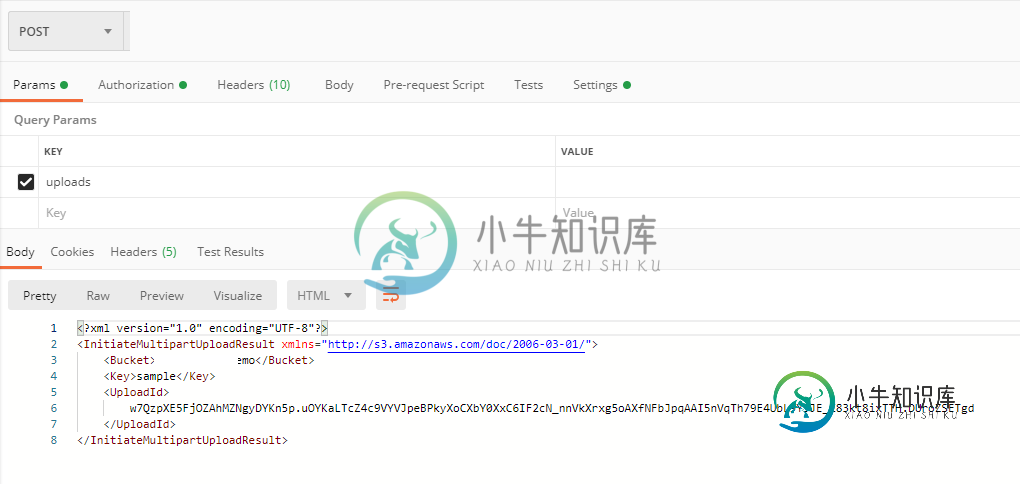
我了解多部分顺序,但在执行上传部分编号的步骤时
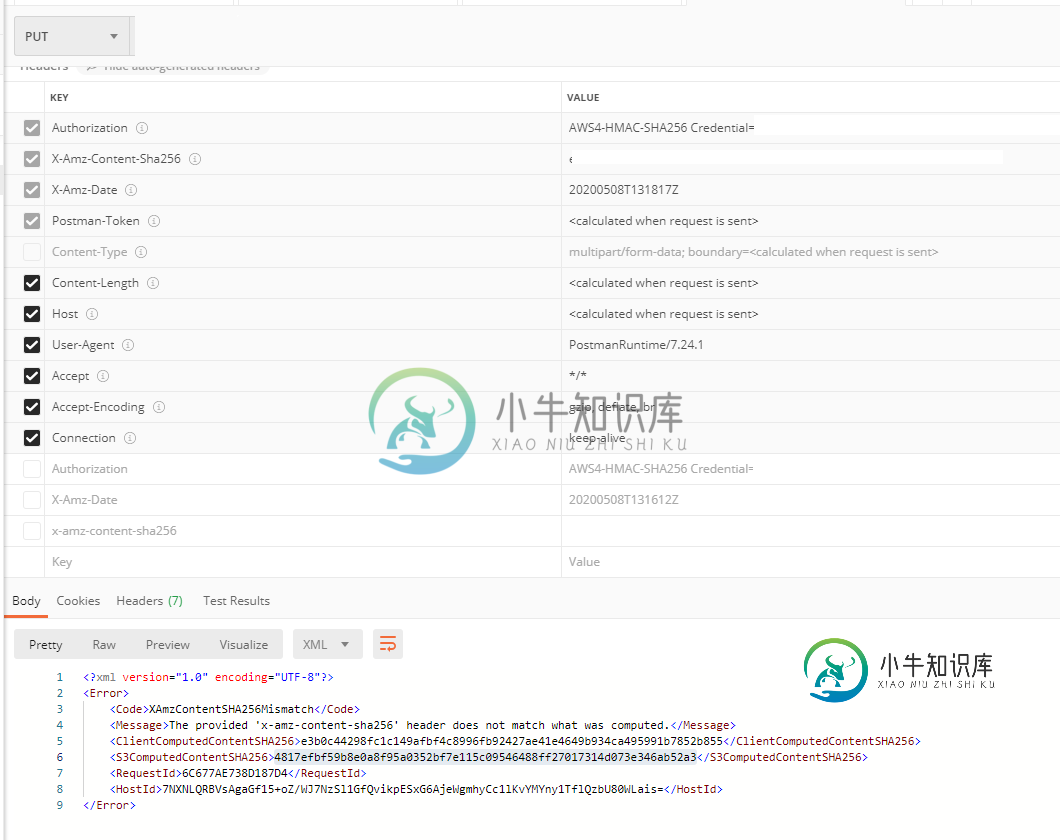
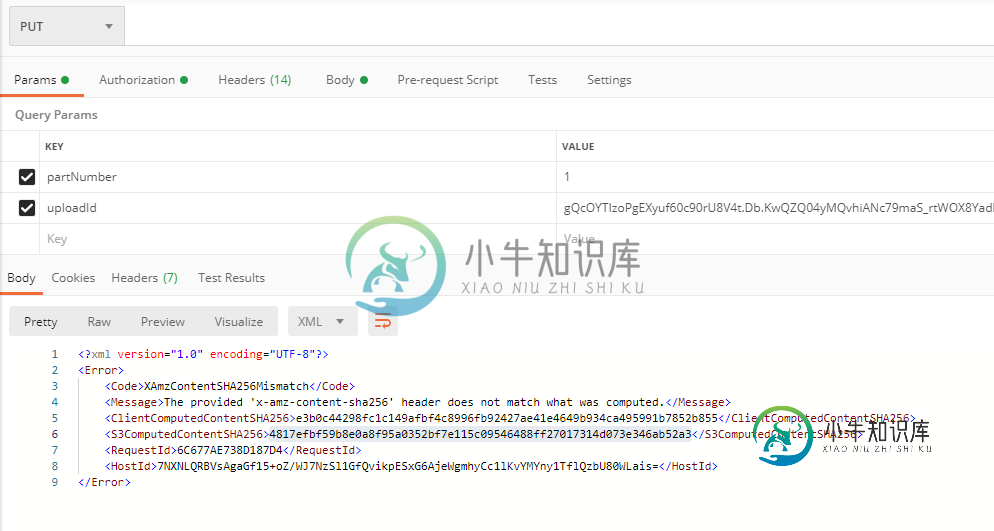

我在各种论坛上找到了多种解决方案,但这些方案都不起作用。我错过了什么吗?
共有1个答案

成功上传到亚马逊S3使用亚马逊的多部分上传和关键(对我来说)是手动添加一个< code>Content-MD5头,并粘贴在Base64编码的MD5散列的一部分(详情如下)。这可能不是操作遇到的确切问题,但我仍然想分享如何使用PostMan,前提是你有良好的工作IAM密钥id和你的亚马逊S3桶的秘密。
首先,我将一个9MB的“mytest.pdf”文件分为两部分进行测试(我使用Linux/WSL命令:split-b 5242880 mytest.pdf),确保第一部分大于5MB(最后一部分可以小于5MB)。
接下来,用以下四个请求设置PostMan:
-
< li>CreateMultipartUpload(如POST https://{ { my bucket } } . S3 . { { my region } } . Amazon AWS . com/mytest . pdf?上传 < li>UploadPart1(如放https://{ { my bucket } } . S3 . { { my region } } . Amazon AWS . com/mytest . pdf?零件号=1
我在PostMan的授权部分粘贴了我的IAM密钥id和访问密钥(单独的文章)
运行CreateMultipartUpload POST以从Amazon获取UploadId。
接下来,计算我的两个文件部分的MD5哈希值(我使用7-zip,但使用您选择的工具)。现在,将结果转换为Base64。但是,我必须确保我最终得到22个字符,后跟可选的两个等号==。当我将MD5转换为文本到Base64时,我得到了一个更长的字符串,它以单个等号结尾,而不是双号(这表明它没有以Amazon期望的方式编码,并且会产生InvalidDigest错误)。例如,如果您使用7-zip计算文件部分的MD5哈希并获得值58942651efd0f5886810d04ed9df502f,然后使用诸如下面的Bases64编码器之类的工具并在Text处选择输入,您将获得NTg5NDI2NTFlZmQwZjU4ODY4MTBkMDRlZDlkZjUwMmY=,但如果您选择“HEX”作为输入,您将获得一个较小的字符串WJQmUe/Q9YhoENBO2d9QLw==即24个字符(22个字符2等于符号)。这就是您想要的。
(此工具无默示认可-无附属https://emn178.github.io/online-tools/base64_encode.html)
如果你弄错了,亚马逊会回复下面的< code>InvalidDigest错误
<?xml version="1.0" encoding="UTF-8"?>
<Error>
<Code>InvalidDigest</Code>
<Message>The Content-MD5 you specified was invalid.</Message>
<Content-MD5>thisisbad</Content-MD5>
<RequestId>8274DC9566D4AAA8</RequestId>
<HostId>H6kSy4cl+54nMon1Hq6AGjmTX/MfTVMQQr8vEVNXUnPlfMtIt8HPdObfusckhBpwpG/CJ6ORWv16c=</HostId>
</Error>
UploadPart 1和2都运行了
最后运行CompleteMultipartUpload,从前面两个请求的头中复制并粘贴Etag值
<CompleteMultipartUpload>
<Part>
<PartNumber>1</PartNumber>
<ETag>"c716d98e83db1edb27fc25fd03e0ae32"</ETag>
</Part>
<Part>
<PartNumber>2</PartNumber>
<ETag>"58942651efd0f5886810d04ed9df502f"</ETag>
</Part>
</CompleteMultipartUpload>
-
我正在尝试使用 java 对亚马逊 S3 进行分段上传。我正在使用下面链接中的代码。 http://docs.aws.amazon.com/AmazonS3/latest/dev/llJavaUploadFile.html 方案 1:要上载的文件大小为 31627。我使用 partSize 作为 500000 来指定单个部件的大小。 由于文件的大小小于部分大小,因此文件将上传到 S3。 方案 2:
-
问题内容: 我有一个800KB的JPG文件。我尝试上传到S3,并不断收到超时错误。你能弄清楚哪里出了问题吗?800KB很小,无法上传。 错误消息:在超时期限内未读取或写入到服务器的套接字连接。空闲连接将关闭。 HTTP状态码:400 AWS错误代码:RequestTimeout 问题答案: IOUtils.toByteArray是否有可能正在耗尽您的输入流,以便在进行服务调用时不再需要从中读取任何
-
当用户上传图片时,我正在动态调整图像大小。原始图片存储在Amazon S3上一个名为djangobucket的bucket中。在这个桶中,包含数千个文件夹。 每个文件夹都以用户命名。我不必担心存储桶创建或文件夹创建,因为所有这些都是从客户端处理的。 下图为: 如您所见,Bob有许多图片。一旦用户将图片上传到S3,我就会通过URL通过Django下载它,在这种情况下,它将是:http://s3.am
-
我在推记录的时候检查过了,如果我们有2个碎片,说Shard1 我有几个问题: 如果多个出版商说两个lambda正在用一个碎片推送到一个kinesis流,这会导致任何竞争条件吗?两个不同的源是否可能推送到单个碎片 建议每个制作人使用不同的碎片,还是多个制作人使用单个碎片
-
亚马逊云 图 1.20.2.1 - AWS AWS,即 Amazon Web Services,是亚马逊(Amazon)公司的 IaaS 和 PaaS 平台服务。AWS 提供了一整套基础设施和应用程序服务,使用户几乎能够在云中运行一切应用程序:从企业应用程序和大数据项目,到社交游戏和移动应用程序。AWS 面向用户提供包括弹性计算、存储、数据库、应用程序在内的一整套云计算服务,能够帮助企业降低 IT
-
我使用的是Hazelcast v3。6在两台amazon AWS虚拟机上(不使用hazelcast的AWS特定设置)。连接应该通过TCP/IP连接设置(而不是多播)工作。我已在虚拟机上打开5701-5801地址进行连接 我曾尝试在两台虚拟机上使用iperf,通过这两台虚拟机,我可以看到一台虚拟机上的客户机连接到另一台虚拟机上的服务器(当我切换iperf的客户机-服务器设置时,反之亦然)。 当我在不