
将一组数字分成两组,这样一组中的数字与另一组中的数字没有任何共同因素

我必须把一组数字分成两组,这样一组中的任何一个数字都不会有一个因数是另一组中任何一个数字的因数。我认为我们只需要找出这样的组,使得每个组中的数的乘积的GCD为1。比如-
如果我们有列表2,3,4,5,6,7,9,可能的组将是 -
(2,3,4,6,9)(5,7) (2,3,4,5,6,9)(7) (2,3,4,6,7,9)(5)
我最初想到的是——
- 生成一个素数列表,直到列表中的最大数字。
- 将列表中的所有元素逐个除以每个素数,如果数字不可被素数整除,则将 0 分配给列表,如果数字不可整除,则将 1 分配给列表。
- 对所有素数重复此操作,给我们一个零和一的矩阵。
- 从第一个素数开始,将所有具有 1 的元素放入一个组中。
- 如果两个组具有相同的元素,则将组合并为一个组。
- 计算出这些组可以组合的可能方式的数量,我们就完成了。
从前面的示例来看,该算法将如下所示 -
- 素数列表 = [2,3,5,7]
- 除法后,矩阵将如下所示 -
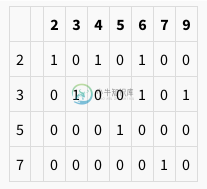
我认为这个算法是可行的,但这是解决这个问题的一个非常糟糕的方法。我可以将质数硬编码到一个大数,然后找到最接近我的最大数的质数,这可能会使它更快,但如果元素的数量是10E6或更多,它仍然涉及太多的除法。我在想也许有一个更好的方法来解决这个问题。也许我缺少一些数学公式,或者一些可以减少迭代次数的小逻辑。
我的问题是关于算法的,所以伪代码也可以工作,我不需要完成的代码。但是,我对Python、Fortran、C、BASH和Octave很熟悉,所以用这些语言回答也会有所帮助,但是正如我所说,语言不是这里的关键点。
我想我可能对一些可能会使我的问题更好的术语一无所知,所以任何改写方面的帮助都是值得感激的。
共有2个答案

这是一种非常冗长的做法...如果数字互换,你也可能会遇到答案重复的问题。
from functools import reduce
from itertools import combinations, chain
import copy
def factors(n):
return [x for x in set(reduce(list.__add__, ([i, n//i] for i in range(1, int(n**0.5) + 1) if n % i == 0))) if x != 1]
#this creates a dictionary with the factors as keys and every element of the value list that it is a factor of
#{'2': [2, 4, 6], '3': [3, 6, 9], '4': [4], '5': [5], '6': [6], '7': [7], '9': [9]}
def create_factor_dict(values):
factor_dict = {}
for val in values:
if len(factors(val)) != 0:
for fac in factors(val):
if str(fac) in list(factor_dict.keys()):
factor_dict[str(fac)] = factor_dict[str(fac)] + [val]
else:
factor_dict[str(fac)] = [val]
return factor_dict
#this deletes all the factor keys that appear as factor values of another key
#{'2': [2, 4, 6], '3': [3, 6, 9], '4': [4], '5': [5], '6': [6], '7': [7], '9': [9]} --> {'2': [2, 4, 6], '3': [3, 6, 9], '5': [5], '7': [7]}
def delete_duplicates(a_dict):
for key in list(a_dict.keys()):
check = copy.deepcopy(a_dict)
del check[key]
if int(key) in list(chain.from_iterable(list(check.values()))):
del a_dict[key]
return a_dict
#this merges values into groups if they contain common values
#{'2': [2, 4, 6], '3': [3, 6, 9], '5': [5], '7': [7]} -- > [[7], [5], [2, 3, 4, 6, 9]]
def merge_groups(a_dict):
a_dict = delete_duplicates(a_dict)
for key in a_dict:
values = a_dict[key]
for key2 in [x for x in list(a_dict.keys()) if x != key]:
if True in [True for x in values if x in a_dict[key2]]:
a_dict[key] = list(set(a_dict[key] + a_dict[key2]))
groups = [list(i) for i in set(map(tuple, list(a_dict.values())))]
return groups
#creates all pairs of 2 then merges into one group
#[[7], [5], [2, 3, 4, 6, 9]] ---> [[7, 5], [7, 2, 3, 4, 6, 9], [5, 2, 3, 4, 6, 9]]
def create_groups(a_dict):
groups = merge_groups(a_dict)
groups = [list(chain.from_iterable(x)) for x in list(combinations(groups, 2))]
return groups
values = [2, 3, 4, 5, 6, 7, 8, 9]
groups = create_groups(create_factor_dict(values))
#this finds the elements of value that do not appear in each group (that's the complimentary pair)
pairs = []
for x in groups:
pair = []
for v in values:
if v in x:
pass
else:
pair.append(v)
pairs.append((x, pair))
print(pairs)
它输出:
[([7, 5], [2, 3, 4, 6, 8, 9]), ([7, 2, 3, 4, 6, 8, 9], [5]), ([5, 2, 3, 4, 6, 8, 9], [7])]

TL;dr:使用一个素数筛来得到一个素数列表,使用一个不相交的集合来存储和组合组
你在正确的轨道上。您可以使用Erasthones筛选来获得质数列表,并且您只需要~O(nlogn)时间和内存来进行质数分解,这还不错。
让我们稍微重新定义一下问题的后半部分:
- 原始列表中的每个数字都是图中的一个节点
- 如果数字共享一个公共因子,则两个节点之间有一条边
现在您的问题是找到两个不相交的节点组。将这些组存储在不相交的集合中。
您的示例的稍短版本,包含元素< code>[2,3,4,5,6]。让我们跟踪subsets列中的每组节点,并遍历上面的数组。
| iteration | subsets | subset1 | description |
|-----------|-----------------|---------|-------------------------------------------------------------------------------------------------------------------------|
| start | [] | n/a | |
| 1 | [] | {2} | add a new subset, 2 |
| 2 | [{2}] | {3} | 3 shares no common factors with 2, so create a new subset 2 |
| 3 | [{2},{3}] | {4} | 4 shares a common factor with 2, but not with 3, so merge it with {2} |
| 4 | [{2,4},{3}] | {5} | 5 shares no common factors with 2,3 or 4, so create a new subset |
| 5 | [{2,4},{3},{5}] | {6} | 6 shares a common factor with {2,4}, so merge it into that. it also shares a common factor with {3}, so merge that too |
| 6 | [{2,4,3,6},{5}] | | done |
从一个不相交的集合开始,使用维基百科上描述的标准属性< code>make_set 、< code>union和< code>find方法。
-
< li >使用< code>get_prime_factors对其进行扩充,返回该子集元素的素因子的Python
集。为了提高空间效率,只有父节点应包含此属性
def get_prime_factors(x):
return Find(x)._prime_factors
def union(x, y):
# use Wikpidia's code
# ...
# add this:
xRoot._prime_factors |= yRoot._prime_factors
return xRoot
disjoint_set = AugmentedDisjointSet([])
elems = [2,3,6,5,4]
for new_number in elems:
subset1 = disjoint_set.make_set(new_number)
for subset2 in disjoint_set.get_subsets():
if (subset1.get_prime_factors() & subset2.get_prime_factors()): # merge if the subsets share a common factor
subset1 = disjoint_set.union(subset1, subset2)
# show result. this may give between 1 (all numbers share a common factor)
# and infinite subsets (all numbers are relatively prime)
# for your example, this will return something like {2,3,4,6,9}, {5}, {7}
# you can group them however you'd like to.
print('result': disjoint_set.get_subsets())
最坏情况在O(n^2*a(n))时间运行,其中< code>a(n)是逆阿克曼函数(即非常小),如果每个元素都是互质的,并且< code>O(n)空间。
-
我是一名编程初学者,并尝试使用处理来实现简单的数据可视化。为了测试,我创建了一个csv文件,其中列出了三列数据,其中第二列和第三列是数字。我分析了这些列,并尝试将第二列数字与第三列数字分开。但不幸的是,结果显示为零。 代码是
-
问题内容: 给定一个字节数组,我如何在其中找到(较小)字节数组的位置? 使用,该文档看起来很有希望,但是如果我正确的话,那只会让我在要搜索的数组中找到一个单独的字节。 (我认为这并不重要,但以防万一:有时搜索字节数组将是常规的ASCII字符,有时是控制字符或扩展的ASCII字符。因此使用String操作并不总是合适的) 大数组可能在10到10000个字节之间,而小数组大约在10个字节。在某些情况下
-
有一种方法可以将特定的数字从一个数组复制到另一个数组吗? 例如: 我有一个数组 ,我想将奇数和偶数复制到不同的数组中。因此,结果应该是
-
如何编写一个Java程序将一组数分成两组,使得它们各自的和的差最小。 例如,我有一个包含整数-[5,4,8,2]的数组。我可以把它分成两个数组-[8,2]和[5,4]。假设给定的一组数字,可以像上面的例子一样有一个唯一的解决方案,那么如何编写一个Java程序来实现这个解决方案。即使我能找出最小的可能差异,也没关系。假设我的方法接收一个数组作为参数。该方法必须首先将接收到的数组分成两个数组,然后将其
-
示例数据: 我想要的查询结果:
-
我不知道如何创建一个字符数组,更糟糕的是,一个作为“扫描器”(System.in)的数组。我会解释: 我想输入一个名字,并从每个字母中接收(输出)等效的数字。但是我不知道怎么做。例如: 但我不希望有一个整数,我希望每个数都是一个完全独立的索引,因为我要“算名字”。 下面是我在没有扫描仪的情况下尝试的一个例子: 9数组的每个索引都是一个有3个字母的字符数组。也许我的想法完全错误。 非常感谢大家的关注